本文分享自华为云社区《DTSE Tech Talk | 第40期:Kurator,你的分布式云原生解决方案》,作者:华为云社区精选。
什么是分布式云原生?
中国信通院给出的定义:分布式云原生是指通过云原生技术统一多云技术栈,提供业务价值的设计模式。
根据这个定义,我们延伸出以下几个问题:
• 什么是云原生技术?
CNCF给出的定义是,云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
• 为什么需要统一多云技术栈?
多云多集群已经成为常态。全球各组织积极拥抱多云多集群。Gartner 机构预测分布式云在5-10年内进入稳定发展期,全球头部云服务商也在分布式云领域积极开展实践。涉及多个云环境的协调和整合,需要处理各种不同的技术栈和工具,同时还要保证数据的安全性和一致性。
多样化的云平台意味着更多的复杂性。统一多云技术栈可以为集群资源集中管理的统一入口,帮助用户从这些复杂性中跳脱出来,同时以云原生的方式将客户的业务协同、数据资产、AI 分析等一系列的业务能力无缝地分布于 分布式云之上,配以完善的安全、管理能力,形成一体化的多云业务管理能力,助力企业业务的扩展和数字化转型。
总的来说,分布式云原生这一设计模式鼓励我们超越单一的云环境,而是将多个云环境作为一个整体来看待,从而实现更高效、更灵活的资源分配和使用。
分布式云原生架构
Kurator,一站式企业级分布式云原生开源解决方案
Kurator 是华为云于2022年推出的分布式云原平台,融合了众多主流的云原生软件栈,如Kubernetes、Istio、Prometheus 等,旨在帮助用户构建和管理自己的分布式云原生基础设施,以推动企业的数字化转型。Kurator 体现了“基础设施即代码”的理念,允许用户以声明方式管理云、边缘或本地环境的基础设施。同时,其“开箱即用”的特性,使用户可以一键安装云原生软件栈。而借助Fleet,Kurator更提供了多云、多集群的统一管理,极大提升了管理效率。
Kurator 目标是一站式构建分布式云原生。这不仅仅包括基础的云服务和资源,还涵盖了服务的自动部署、监控、维护、扩展以及优化等多个环节,用户不需要从多个供应商或产品中选择,只需利用 Kurator 就能满足企业的所有云原生需求。
Kurator是一种开源的解决方案。这意味Kurator 的源代码是公开的,这让任何人都可以查看、修改或重新发布代码。开源不仅提供了透明性,让用户能够了解软件的内部工作,还能鼓励一个活跃的社区参与进来,共同改进和扩展功能。更重要的是,开源为企业提供了更大的灵活性,允许他们根据自己的特定需求进行定制,而不是被迫适应商业软件的约束。
![image.png]()
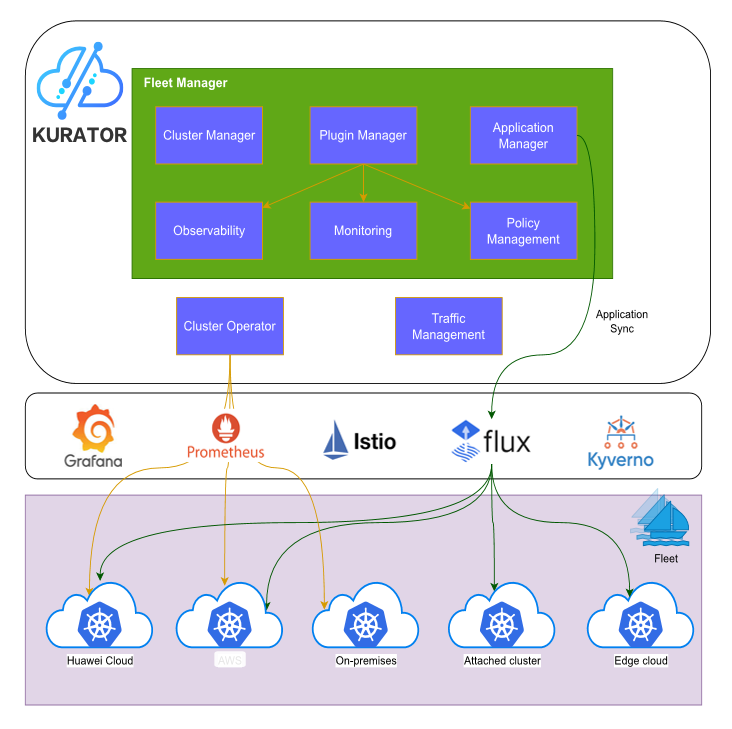
Kurator技术架构
Kurator 目前主要有两个核心组件,分别是 fleet manager 和 cluster operator
通过Cluster Operator 可以简化用户操作并自动化Kubernetes集群的部署流程,确保集群在各种环境中的稳定运行。
通过fleet manager,kurator 实现了以 fleet 为资源管理单位,对分布式云提供统一的管理。
Kurator的典型特性介绍
Kurator 最新版本 为分布式云原生提供了多个典型能力。
• 资源一体化方面,kurator 提供了多集群生命周期管理的能力,确保各集群始终在最佳状态,为资源的一体化打下坚实的基础。此外,还提供了统一多集群监控的能力,通过全局视野,保障所有集群的健康与稳定性,进一步强化资源的一体化。
• 业务广分布方面,kurator提供了应用统一分发的能力,以允许用户无缝地在多个集群中部署和同步应用,保证业务在任何场景下的广泛分布和高可用性。
• 安全无边界方面,kurator的统一安全策略管理确保在所有集群中实施和遵循相同的安全标准,确保整个平台的安全无边界。
集群生命周期管理
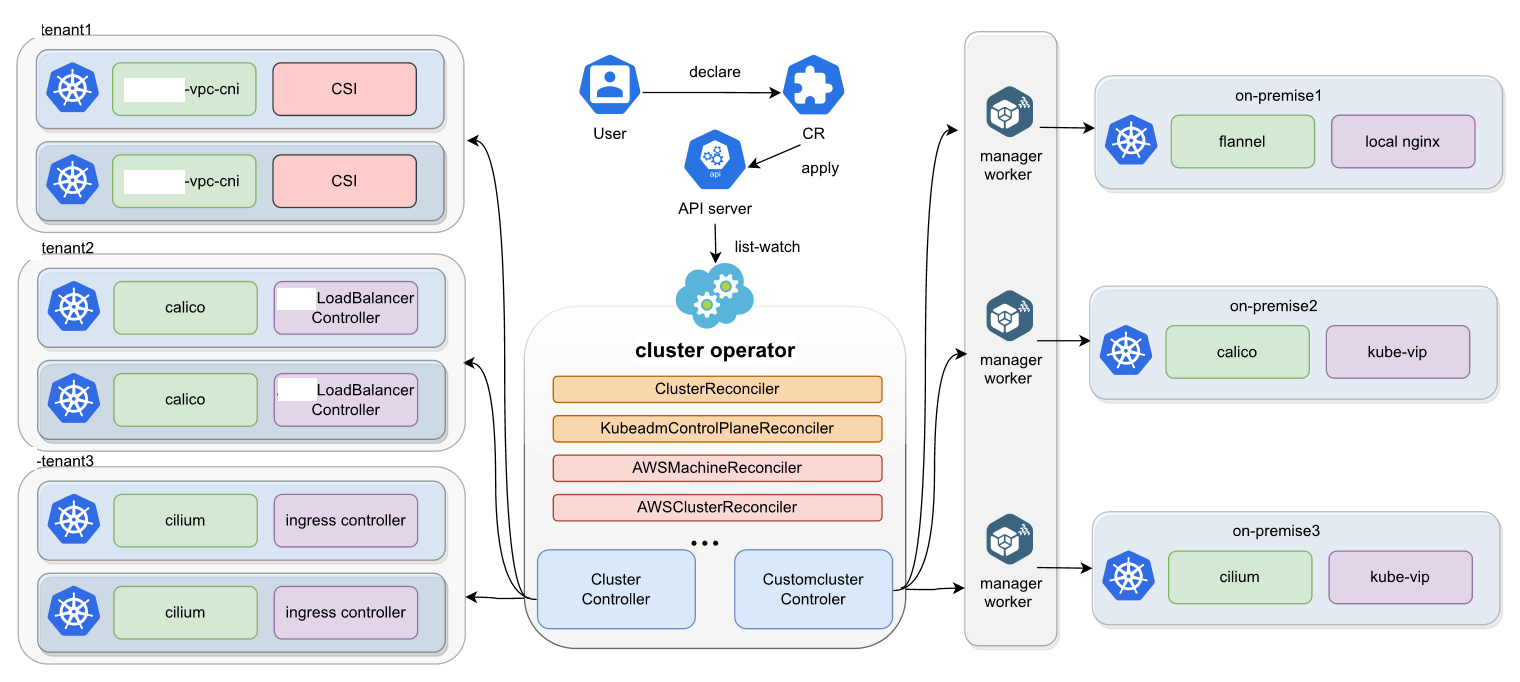
Kurator 通过 Cluster Operator 组件对集群的生命周期进行管理。基于 Cluster API,Cluster Operator 不仅可以管理集群生命周期,还统一并简化了创建集群所需的配置,为用户在不同云平台上管理集群提供了简单易用的 API 。目前 Cluster Operator 支持本地数据中心集群和第三方云厂商上的自建集群。
![image.png]()
Kurator 集群生命周期管理
Kurator 设计了声明式的API用以表达 Kubernetes 集群的期望状态,并通过 Cluster Operator 对集群生命周期进行管理。
统一应用分发
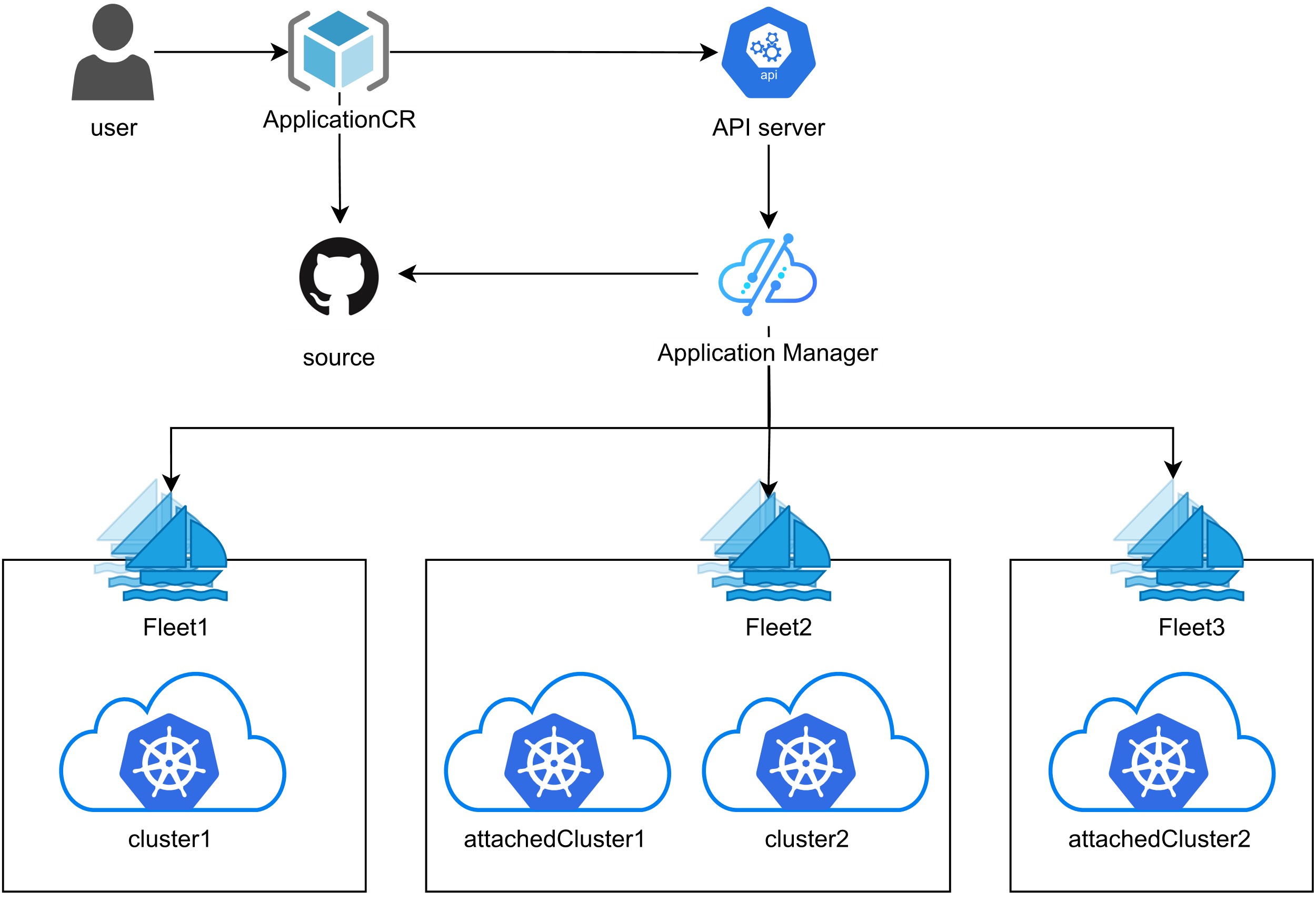
Kurator 的统一应用分发功能采用 GitOps 方式,使得一键将应用部署到多个云环境成为可能,同时简化了配置流程。这种方法确保了各集群中的应用版本保持一致,也能及时进行版本更新。在 Kurator 宿主集群上,用户可以对所有集群的应用部署情况进行统一的查看和管理,从而提高运维效率。
![image.png]()
Kurator 统一应用分发
Kurator 的统一应用分发功能简化了多云部署,确保各集群应用版本的一致性,提供了统一的管理视图,并支持灵活的配置与同步策略。
统一监控
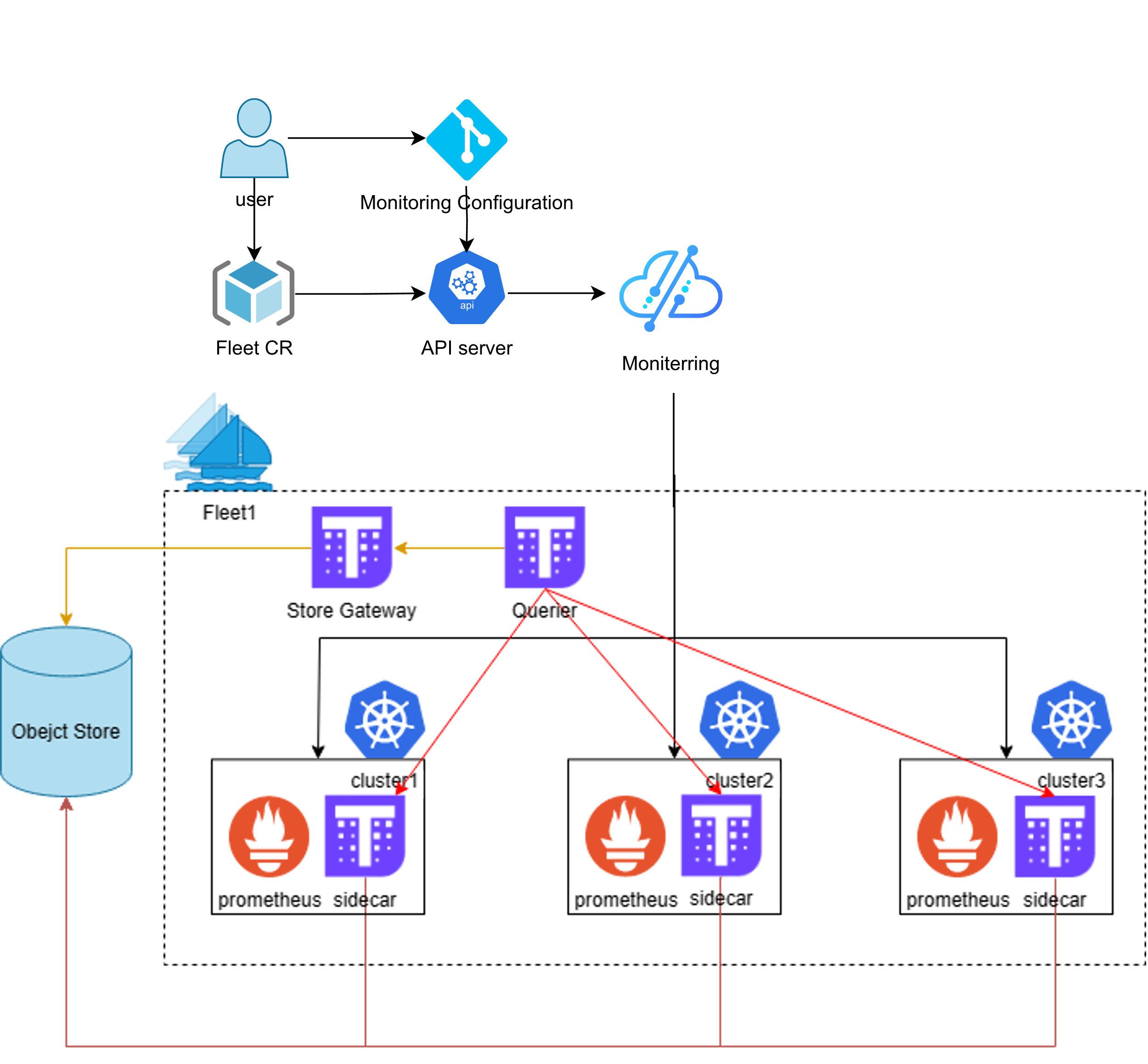
为了解决各个集群间进行有效的监控和管理,以确保服务的稳定性和优化资源使用率问题,Kurator 提供了一种基于 Prometheus、Thanos、Grafana 以及 Fleet 的多集群指标监控方案。
![image.png]()
Kurator 统一监控
Kurator 借助 Fleet 简化了多集群监控组件的安装,基于 Prometheus 和 Thanos Sidecar 实现了高效的指标采集,同时支持用户自定义监控配置在集群间的分发,为用户提供了一个全面、准确的统一监控视图。
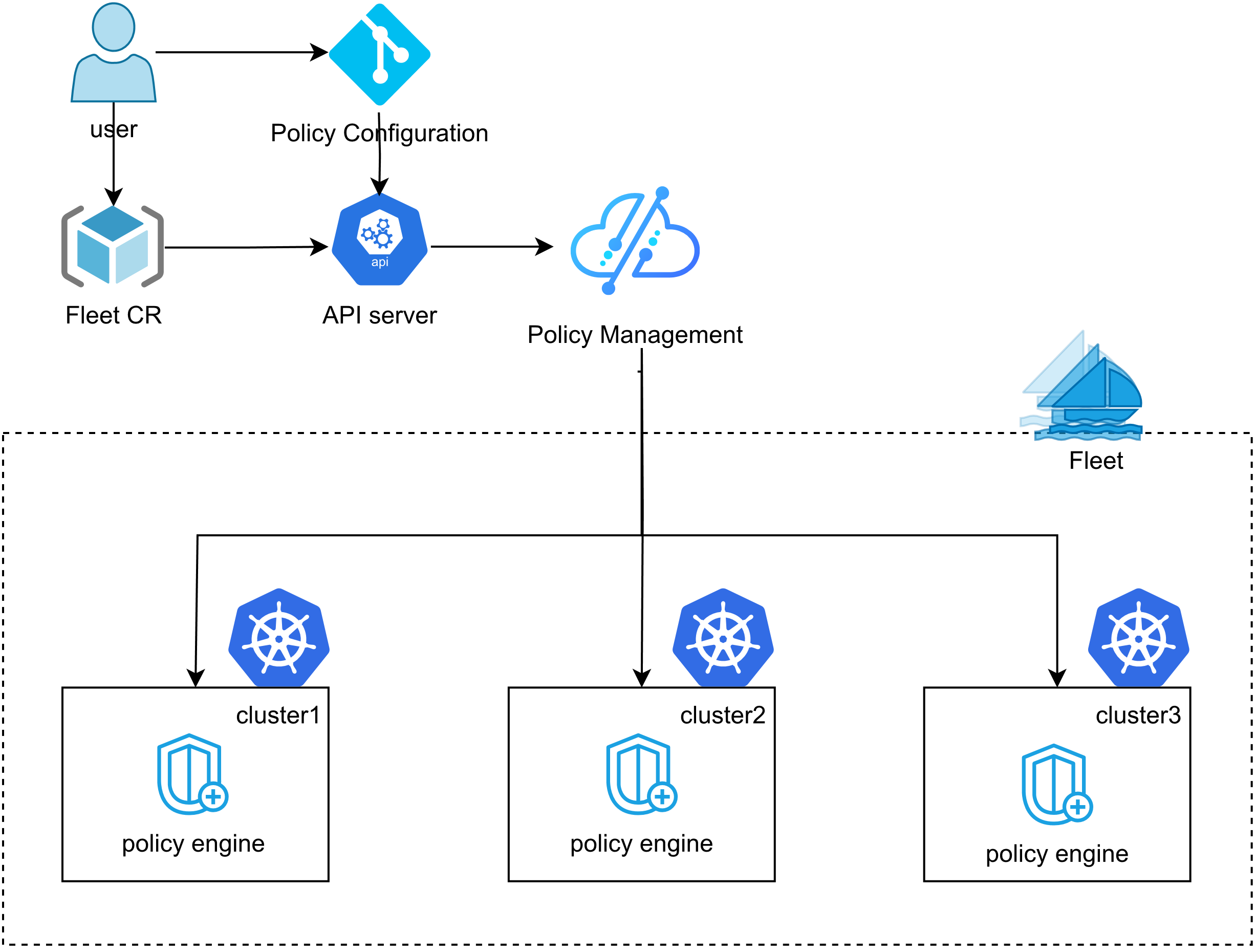
统一策略管理
在分布式云环境中,通过Kurator 的统一策略引擎(Kyverno),并利用 Fleet 实现应用策略的跨集群分发和应用。 借助 Kurator 的统一策略管理能力,可以有效提高策略管理的效率,同时保证所有集群中策略的一致性和安全性。
![image.png]()
Kurator 统一策略管理
Kurator 在分布式云环境中提供跨多集群的统一策略管理,简化策略配置与应用,与单一Kubernetes 集群管理相似,确保策略的一致性、安全性并提高管理效率。
Kurator项目地址
GitHub: https://github.com/kurator-dev/kurator
Website: https://kurator.dev
号外!
![cke_7691.jpeg]()
华为将于2023年9月20-22日,在上海世博展览馆和上海世博中心举办第八届华为全联接大会(HUAWEICONNECT 2023)。本次大会以“加速行业智能化”为主题,邀请思想领袖、商业精英、技术专家、合作伙伴、开发者等业界同仁,从商业、产业、生态等方面探讨如何加速行业智能化。
我们诚邀您莅临现场,分享智能化的机遇和挑战,共商智能化的关键举措,体验智能化技术的创新和应用。您可以:
- 在100+场主题演讲、峰会、论坛中,碰撞加速行业智能化的观点
- 参观17000平米展区,近距离感受智能化技术在行业中的创新和应用
- 与技术专家面对面交流,了解最新的解决方案、开发工具并动手实践
- 与客户和伙伴共寻商机
感谢您一如既往的支持和信赖,我们热忱期待与您在上海见面。
大会官网:https://www.huawei.com/cn/events/huaweiconnect
欢迎关注“华为云开发者联盟”公众号,获取大会议程、精彩活动和前沿干货。
点击关注,第一时间了解华为云新鲜技术~