去年,机器学习和人工智能领域取得了爆炸性的进展。像 ChatGPT 这样的高质量生成式人工智能解决方案引起了公众的兴趣,并已延伸到商业领域。组织和个人都在考虑如何利用这项技术来加快影响力并取悦客户。
虽然这些通用模型非常出色,但在特定行业的使用案例中往往不够完美。公开可用的训练数据无法为模型提供解决每个企业特有用例所需的专业知识。为了满足这些需求,许多组织正在投资调优和训练自己的模型。为此,他们需要扩展他们的计算空间,使其超出工程师的笔记本电脑或现有的构建工具。数据科学家和机器学习工程师需要可帮助他们扩展工作负载的工具,使其可以操控访问与之匹配的计算资源。
为了应对这些挑战,我们高兴的宣布:VMware 与 Ray 的创建者 Anyscale 建立合作伙伴关系。Ray是一个针对机器学习工作负载进行了优化的分布式Python工作负载调度器,为训练和推理工作负载带来了无服务器式的扩展能力。在并行处理和分布式计算方面,Ray具有广泛的应用和出色的性能。
Anyscale 和 VMware 合作创建了一个开源插件,用于使用虚拟机在 vSphere 上运行 Ray。该插件使系统管理员能够为数据科学团队提供满足其需求的计算基础架构。当数据科学团队能够使用计算来运行支持其数据探索、清理和模型实验的工作负载时,企业就能缩短从原始数据到得到调优后差异化模型所需的时间,从而促进目标业务成果的实现。这过程如同DevOps,但这次的目标是将工作模型交付到生产中。
它是如何工作的?
Ray 集群包含一个头部节点和工作节点。
![]()
头部节点负责管理集群,并调整集群内工作节点的数量。这些分布式工作节点负责训练、微调和提供模型。
要开始工作,头部节点的 Autoscaler 需要了解它能提供多大的群集以及在哪里提供,这需要一个群集配置文件。
为了实现这一点,我们的插件扩展了Ray Autoscaler,使其能够直接与 vSphere 上的虚拟机协同工作。
![]()
为了协调 Ray 工作负载,Ray Autoscaler 插件会调用 vSphere 群集。vSphere 群集是一组主机,其中主机的资源成为群集资源的一部分。群集管理其中所有主机的资源。群集支持 vSphere High Availability (HA) 和 vSphere Distributed Resource Scheduler (DRS)。这些功能可确保 Ray 群集具有容错性,与其他关键任务工作负载隔离,并以最佳方式分配计算资源。
配置vSphere Provider
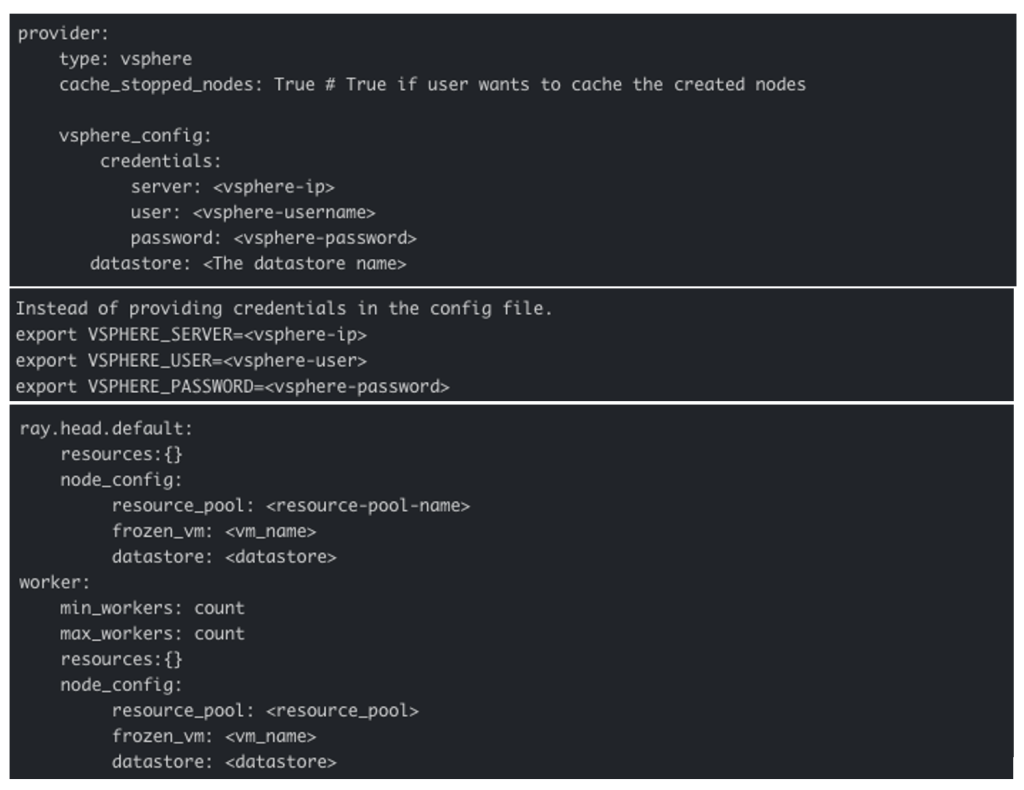
下图显示了与 vSphere 一起使用的 Ray 群集配置文件示例。在提供程序部分,我们必须将类型指定为 vSphere,并指定 vSphere 群集的凭据和部署 Ray 群集的数据存储。
![]()
此外,在工作者节点和头配置中,我们可以配置资源池将Ray Worker与其他工作负载隔离开。为了提高性能,我们还可以指定冻结虚拟机( Frozen VM)。这个被冻结的虚拟机将被用作即时克隆(Instant clone),以快速扩展工作节点。
下一步做什么?
我们今天分享的只是第一步。我们目前正在探索如何在数据中心空闲的时间利用未使用的计算来训练 ML 模型,使组织能够在不影响生产工作负载的情况下从其数据中心获得更多价值。这对地球也大有裨益!
我们已经准备好利用我们的 Ray on vSphere 插件迎接自动化的新时代,并简化对机器学习的访问。欢迎试用和反馈,请将问题发送至 rayonvmware@vmware.com。
本文作者:Ala Dewberry,OCTO xLabs 高级产品经理;Sean Huntley,OCTO 产品工程师。
内容来源|公众号:VMware 中国研发中心
有任何疑问,欢迎扫描下方公众号联系我们哦~
![]()