时间序列数据在各行业和领域中无处不在,如物联网传感器的测量结果、每小时的销售额业绩、金融领域的股票价格等等,都是时间序列数据的例子。时间序列预测就是运用历史的多维数据进行统计分析,推测出事物未来的发展趋势。
为加快企业智能化转型进程,降低时序技术应用门槛,飞桨持续进行产品技术打磨,推出了基于启发式搜索和集成学习的高精度时序模型PP-TS,在电力场景数据集上经过验证,精度提升超20%。
PP-TS今天正式上线飞桨AI套件PaddleX!源码全部开放!您可以在AI Studio(星河社区)云端或者PaddleX本地端尽情探索!尝试结合到真实的业务场景中去!在工具箱模式中,您只需提供一个场景下的历史数据,PP-TS就能为您准确预测出该场景下未来一段时间内的数据情况。
![]() 数据
数据
![]() 训练
训练
![]() 评估测试
评估测试
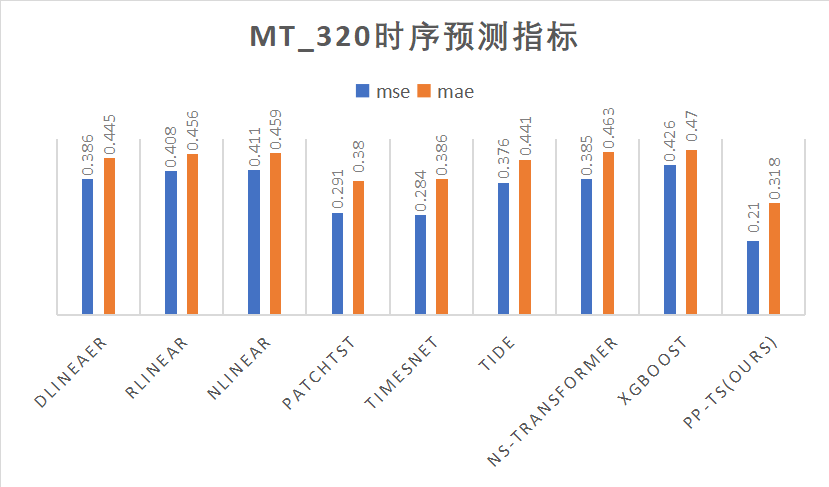
除PP-TS外,飞桨也提供了8种业界领先的时序预测方法,即TimesNet, TiDE, PatchTST, DLinear, RLinear, NLinear, Nonstationary Transformer和XGBoost以便您对比使用。
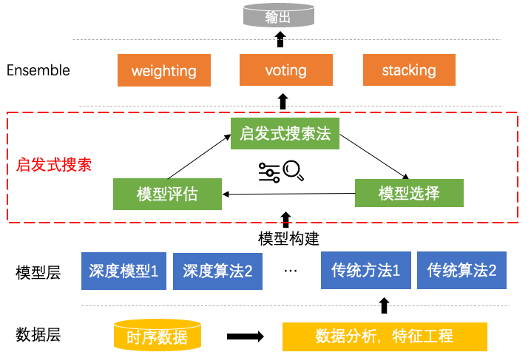
PP-TS核心思想
基于集成方法,相较于传统时序预测,PP-TS预测更加准确
随着5G时代的到来,企业逐步进入数字化转型新阶段,面临越来越多复杂时间序列预测场景,如设备剩余寿命预测、电力负荷预测等。在复杂时序预测场景下,长时序、多变量、非平稳等特性严重影响模型预测的精度,对时序预测任务提出了更高的要求。因此我们采用集成方法,通过对多个单预测模型的选择和融合,从而达到更佳的预测表现。
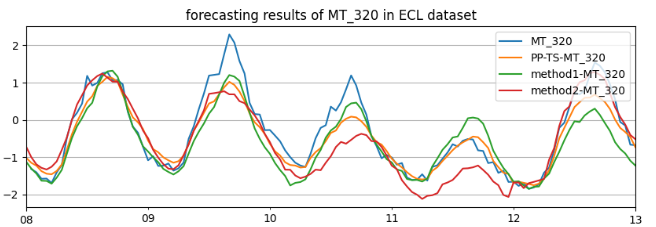
在电力场景下,PP-TS的准确度优于传统模型,预测误差平均降低30%
![]()
![]()
通过启发搜索,降低搜索次数
不同单模型具有不同的能力,如Non-Stationary Transformer针对数据非平稳场景进行优化,TimesNet通过多周期分解具有更强的表达能力。可见,不同的算法组合集成会产生不同的预测表现,那么选择什么模型能够达到最佳效果,在选择模型组合的过程中,又如何提高选择效率,这些便是要重点关注和解决的问题。因此我们提出了PP-TS,通过启发式搜索选择模型集成,降低选择模型组合次数,比如:在8个基础单模型的情况下,每个模型都有选择和不被选择两种情况,总的集成组合有2^8种,通过启发搜索,能够将搜索的次数压缩到30次左右,同时保证了集成的模型能够取得最佳精度。
PP-TS关键技术点解读
能力更强的PP-TS,整体的技术框架图,如下图所示:
![]() PP-TS
PP-TS
PP-TS主要从三个角度进行了深入探索,主要包括:
-
基础单模型:深度模型一般拟合能力强,Transformer-based方法善于捕捉长期依赖,而机器学习方法具有更好的可解释性,PP-TS选择了前沿深度模型和传统方法的结合,包含TimesNet, TiDE, PatchTST, DLinear, RLinear, NLinear, Nonstationary Transformer和XGBoost。
-
启发式搜索:将单模型是否被选择建模成0/1问题,通过遗传算法,对选择的组合进行精度评估,通过选择交叉变异进化,筛选最优组合。
-
模型集成:将被选择的模型进行集成,结果融合,得到精度最佳的方法。
如何定制个性化的PP-TS
在真实业务中,一般不建议直接使用通用版的PP-TS,而是需要针对业务场景中的数据类型进行专门的优化适配,以达到足够高的精度和稳定性,满足真实业务需求。那么,如何打造个性化的PP-TS呢?下面让我们一一道来。
创建PP-TS模型产线
飞桨AI套件PaddleX已上线AI Studio(星河社区),目前的入口在模型库,大家可以在这里找到PP-TS,阅读其介绍文档,并最终创建属于你自己的PP-TS模型产线。
AI Studio(星河社区)模型库链接如下:https://aistudio.baidu.com/aistudio/modelsoverview?supportPaddlex=true&sortBy=weight
准备评估数据与效果验证
为了客观地评价PP-TS的效果,建议大家从业务场景中准备一定量的评估数据进行定量的综合评价。例如,可以准备过去3个月的行业数据,根据业务需求标注所关注的字段及其真值。
在对通用的PP-TS效果进行评估之后,其结果可以作为baseline指导后续针对业务场景的优化工作。
One more thing,未来在飞桨AI套件PaddleX,大家不仅可以开发自己的模型,还可以联创贡献,和平台收益共享!
联创模式不仅可以技术变现,还可以让个人开发者收获满满的成就感,为企业开发者吸引流量和关注,真可谓好事成双!而且,有了大量的用户,就能够收集到有价值的反馈,促进贡献者进一步优化模型,从而吸引更多的用户,可谓双螺旋上升~
为了保护贡献者的知识产权,我们会提供完善的加密鉴权机制,各位贡献者只需要按照我们的文档接入加密鉴权能力,就可以放心地贡献模型啦!关于联创的更多细节,敬请关注飞桨AI套件PaddleX后续更新!
飞桨AI套件PaddleX中的PP-TS
https://aistudio.baidu.com/modelsdetail?modelId=339
PP-TS GitHub
https://github.com/PaddlePaddle/PaddleTS
 数据
数据