🎉Firefly项目支持微调ChatGLM2模型啦,我们实现了一种比ChatGLM2官方更加充分高效的多轮对话训练方法,并且沿袭了官方的数据组织格式。
在此之前,很多同学询问Firefly项目是否支持微调ChatGLM或ChatGLM2模型,而我们迟迟未进行适配的原因主要如下:
-
此前,Firefly虽然已支持微调Llma2、Llama、Baichuan、InternLM、Ziya、Bloom等开源大模型,但都是在Pretrain模型上进行指令微调,指令数据的组织格式相对自由,可按需自行设计。
-
ChatGLM不属于严格意义上的Causal Language Model(因果语言模型),因为它存在prefix attention mask的设计。对于prefix而言,它的attention是双向的,而预测部分的attention是单向的,存在一定的适配成本。但ChatGLM2做出了改变,它的注意力是单向的。
-
ChatGLM2是一个经过指令微调的chat模型,微调时遵从官方的数据组织格式,才能达到最优效果。
-
Firefly项目有自己独特的多轮对话训练方式。
对于预训练模型,可以自由设计训练数据的组织格式;对于chat模型,最好遵从官方的数据组织格式。
在适配ChatGLM2的过程中,我们阅读了一些ChatGLM2的官方代码,发现ChatGLM2的多轮对话训练方式存在不足之处,在后续章节中,我们也将从源码对其进行分析。我们也将分享Firefly如何实现对ChatGLM2进行更加充分高效的多轮对话训练,以及训练效果。
此前,我们专门分享过多轮对话的训练方法,结合阅读有助于理解:一文看懂:如何充分高效训练多轮对话大模型。
Firefly项目链接:
https://github.com/yangjianxin1/Firefly
firefly-chatglm2-6b权重:
https://huggingface.co/YeungNLP/firefly-chatglm2-6b
我们使用Firefly项目对ChatGLM2进行微调,使用项目中分享的moss数据,以及采样了2万条school math数据,合并后大约100万数据,总共训练1万个step,目前训练了2500个step,大约消耗了24万条数据。
待训练完毕,我们也将开源该模型权重,我们将该模型命名为firefly-chatglm2-6b。下面将简单展示该模型的生成效果,模型在上下文理解、指代消歧等方面具有不错的效果,因为加入了一部分数学题,模型的数学推理能力也有一定的提升,但比起13B的模型还是略显逊色。总体而言,我们的微调方法有着不错的效果。
![]()
对话示例2:
![]()
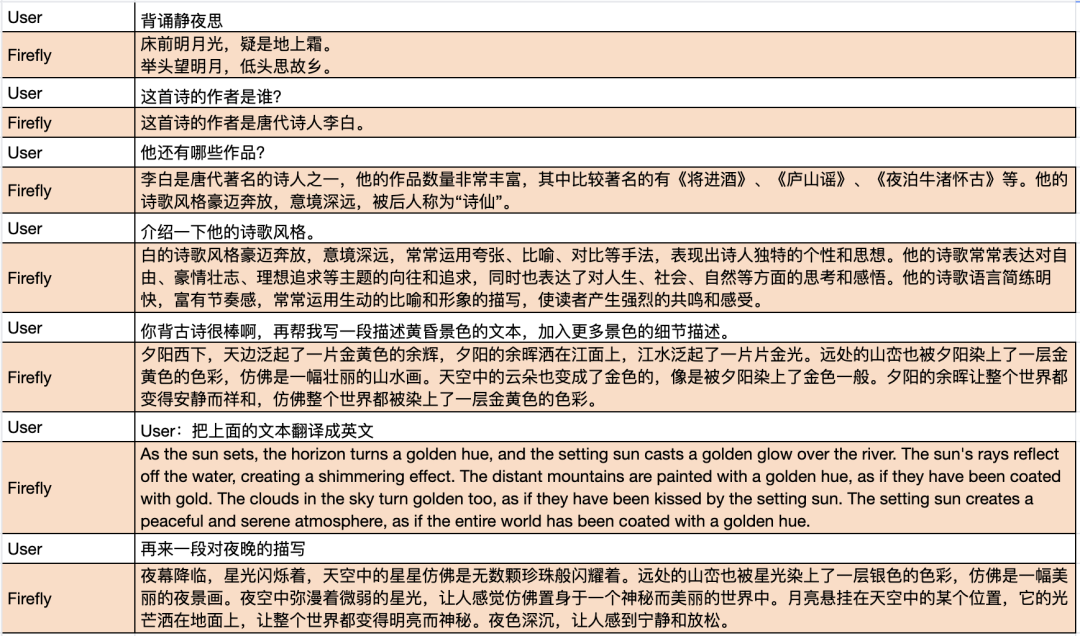
在分析源码之前,我们先抛出一个结论: ChatGLM2的多轮对话训练方式如下图所示,只有最后一轮对话内容参与计算loss,其他的Assistant回复内容不参与计算loss,训练数据利用不充分,造成浪费。
-
-
https://github.com/THUDM/ChatGLM2-6B/blob/main/ptuning/main.py#L180
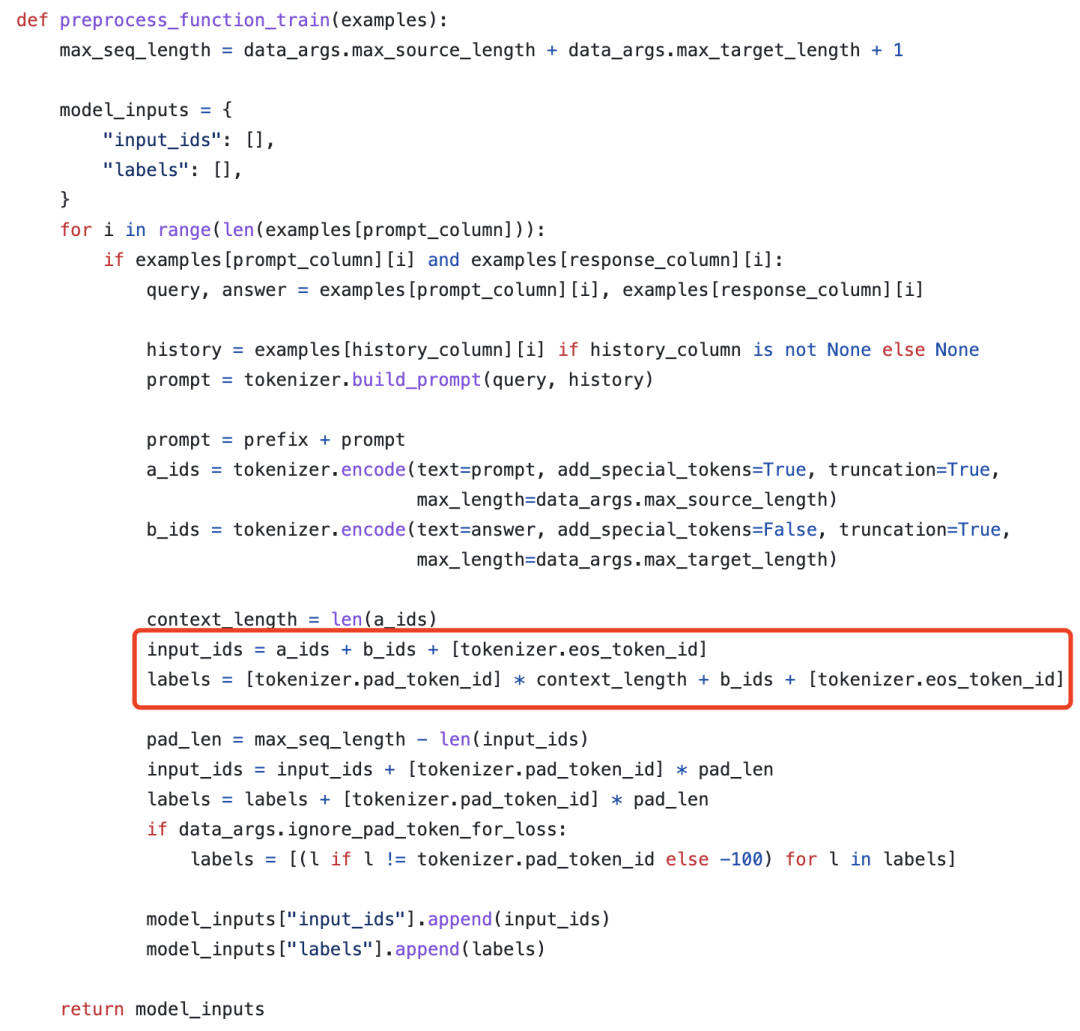
可以看到模型最终的输入是由prompt、answer和结束符拼接而成。其中prompt是由tokenizer.build_prompt(query,history)得到的,也就是将历史对话和当前轮次的用户输入进行拼接,而answer则是当前轮次的回复。
![]()
tokenizer的build_prompt方法如下:
![]()
通过上述分析,我们很容易得出ChatGLM2的多轮对话数据的组织格式如下,其中</s>表示模型的生成结束符。
[Round 1]
问:{input1}
答:{target1}
[Round 2]
问:{input2}
答:{target2}
[Round 3]
问:{input3}
答:{target3}</s>
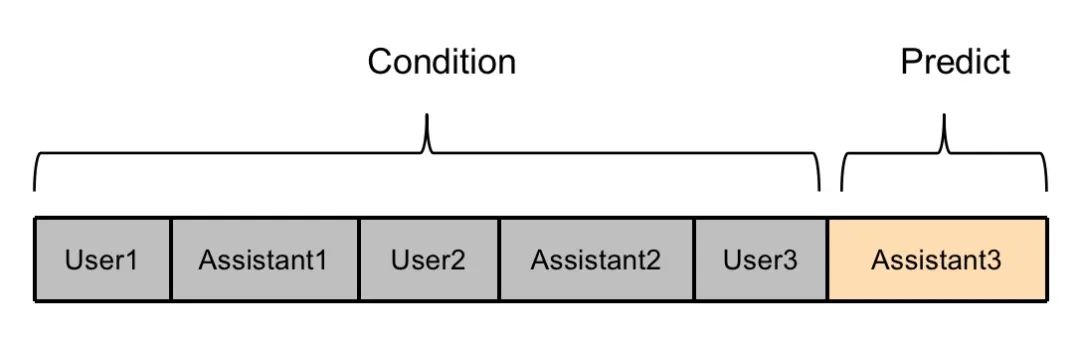
对于第二个问题,我们可以看到,对于labels而言,除了最后一个轮次的回复内容外,其他所有位置都被置为了pad_token_id。也就是说只有最后一轮的回复内容参与计算loss,其他轮次的回复内容不参与计算loss,训练数据没有被充分利用,被浪费了。
![]()
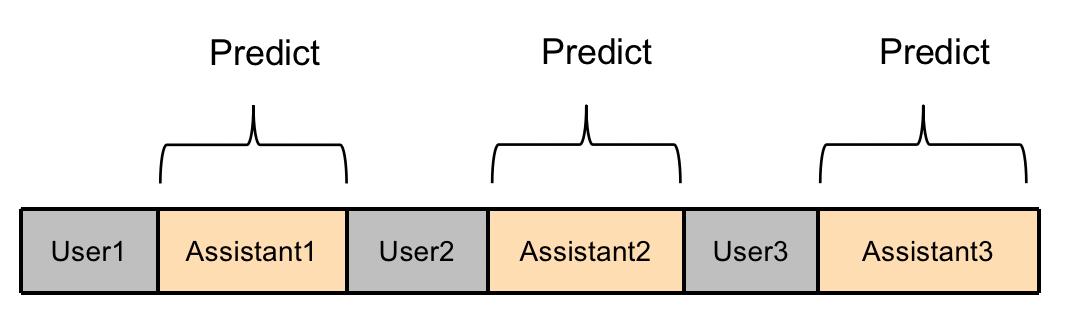
Firefly微调ChatGLM2的方法如下图所示,该方法的优势如下:
-
推理时候,模型不会出现“自问自答”和“不停止”的情况。
-
训练时,多轮对话中的每个回复都被充分利用。
-
计算高效,不需要将一条多轮对话数据拆分成多条数据。
![]()
在微调ChatGLM2时,Firefly基本上沿袭了ChatGLM2的数据组织格式,仅在每个target后面添加了</s>停止符。对于一条多轮对话数据,所有"{target}</s>"都会并行参与计算loss。并且因为</s>停止符的妙用,在推理时,模型不会遇到“自问自答”和“不停止”的情况。
[Round 1]
问:{input1}
答:{target1}</s>
[Round 2]
问:{input2}
答:{target2}</s>
[Round 3]
问:{input2}
答:{target2}</s>
为什么这种做法是可行的?详见文章:一文看懂:如何充分高效训练多轮对话大模型。
Talk is cheap,Show me the code。接下来将从代码层面介绍我们是如何充分高效地实现多轮对话训练。
微调ChatGLM2时,Firefly将多轮对话拼接成如下格式。
[Round 1]
问:{input1}
答:{target1}</s>
[Round 2]
问:{input2}
答:{target2}</s>
[Round 3]
问:{input2}
答:{target2}</s>
在生成input_ids的时候,我们还会生成一个target_mask,取值为0或1,用来标记每个token是否属于target部分,即是否参与loss计算。其中“target</s>”部分的target_mask均为1,其他部分均为0。
我们会并行计算每个位置的loss,但只有target_mask=1的部分的loss,才会参与权重更新。这种方式充分利用了模型并行计算的优势,更加高效,并且多轮对话中的每个target部分都参与了训练,更加充分利用了数据。
数据组织格式如下:
class ChatGLM2SFTDataset(SFTDataset):
def __getitem__(self, index): """ 基本沿袭ChatGLM2的指令微调的格式,做了小修改,多轮对话如下。 """ data = self.data_list[index] data = json.loads(data) conversation = data['conversation'] input_format = '[Round {}]\n\n问:{}\n\n答:' target_format = '{}'
utterances = [] for i, x in enumerate(conversation): human = input_format.format(i+1, x['human']) assistant = target_format.format(x['assistant']) utterances += ([human, assistant]) utterances_ids = self.tokenizer(utterances, add_special_tokens=False).input_ids
input_ids = [] target_mask = [] for i, utterances_id in enumerate(utterances_ids): input_ids += utterances_id if i % 2 == 0: target_mask += [0] * (len(utterances_id)) else: input_ids += [self.eos_token_id] target_mask += [1] * (len(utterances_id) + 1) assert len(input_ids) == len(target_mask) input_ids = input_ids[:self.max_seq_length] target_mask = target_mask[:self.max_seq_length] attention_mask = [1] * len(input_ids) assert len(input_ids) == len(target_mask) == len(attention_mask) inputs = { 'input_ids': input_ids, 'attention_mask': attention_mask, 'target_mask': target_mask } return inputs
loss计算方式如下:
class TargetLMLoss(Loss):
def __init__(self, ignore_index): super().__init__() self.ignore_index = ignore_index self.loss_fn = nn.CrossEntropyLoss(ignore_index=ignore_index)
def __call__(self, model, inputs, training_args, return_outputs=False): input_ids = inputs['input_ids'] attention_mask = inputs['attention_mask'] target_mask = inputs['target_mask'] outputs = model(input_ids=input_ids, attention_mask=attention_mask, return_dict=True) logits = outputs["logits"] if isinstance(outputs, dict) else outputs[0]
labels = torch.where(target_mask == 1, input_ids, self.ignore_index) shift_logits = logits[..., :-1, :].contiguous() shift_labels = labels[..., 1:].contiguous() loss = self.loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1)) return (loss, outputs) if return_outputs else loss
本文转载自社区供稿内容,不代表官方立场。了解更多,请关注微信公众号"YeungNLP":
如果你有好的文章希望通过我们的平台分享给更多人,请通过这个链接与我们联系:
https://hf.link/tougao