浓荫夏木繁茂,阳光蝉鸣交织;在这初伏来临,万物葱茏之际,我们很高兴和大家宣布,DolphinDB V2.00.10 和 V1.30.22 新版本,近日即将炙热上线!
这次的新版本大大提升了用户编程体验,在数据分析性能提升的同时,进一步完善了我们的生态,降低了学习成本,比如加强了标准 SQL 常用语法的兼容性、新增 VSCode Debug 功能,以及推出插件在线安装功能等。
同时,我们还新增支持了数据类型 DECIMAL128,拓展了数据精度,为更精细化的业务场景提供支持;丰富并优化了内置的计算函数和一系列机器学习函数,拓展了 TopN 和 row 系列等函数功能。
下面一起来看看本次新版本的重要更新~
提高易用性,编程体验更丝滑
作为一个融合了编程语言与数据库的产品,DolphinDB 非常重视用户的编程体验,希望能够帮助用户更快地理解和掌握基本用法,提高代码质量,节省开发时间。本次 V2.00.10 和 V1.30.22 新版本中,我们进一步加强了对标准 SQL 语法的兼容,在数据类型和形式方面做了扩充,并新增了对 VSCode Debug 功能的支持。
加强兼容标准 SQL 语法
标准 SQL 是一种用于管理关系型数据库的编程语言和标准化查询语言,它提供了一套用于定义、操作和管理数据库的通用规范和语法。兼容标准 SQL 可以增强数据库的可移植性,便于用户在不同的数据库产品之间轻松迁移,此外还能降低用户的学习成本,提高开发和生产的效率。
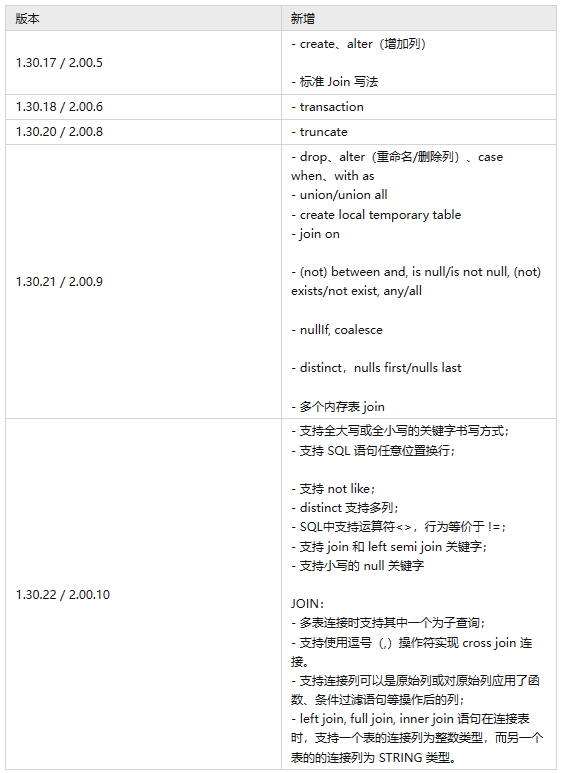
自 V1.30.17&V2.00.5 版本开始,DolphinDB 逐步支持了标准化 SQL 的书写方法;从本次 V2.00.10&V1.30.22 起,DolphinDB 还对标准 SQL 的常用语法和关键字实现了兼容。
各个版本对标准 SQL 的支持和功能增强列表如下:
![]()
增强支持 DECIMAL 数据类型
DECIMAL 类型用于存储高精度的数值,如货币、金融数据和科学计算等。与其他数值类型(如 FLOAT 或DOUBLE)相比,DECIMAL 类型能够准确保存和计算小数位数,避免舍入误差。
DolphinDB 在 2.00.8 版本已经支持了 DECIMAL32 和 DECIMAL64 类型。但现有的 DECIMAL64 类型在乘法计算时,结果可能会溢出,因此,新版本拓展支持了 DECIMAL128 类型。此外,算术运算溢出后,若存在更高精度的类型将自动拓展。
在新版本中,DolphinDB 还增强了内置函数对 DECIMAL 类型的支持,并在流数据时序聚合引擎和响应式引擎中也增加了对 DECIMAL 类型计算的支持。
新版本还新增支持了 DECIMAL 类型的乘法函数 decimalMultiply,与 mul 函数 (* 运算符) 相比,decimalMultiply 可以指定计算结果的精度。
推出 VSCode Debug 功能
新版本推出了 VSCode Debug 的功能,支持语法解析、断点设置、控制调试、栈帧和变量查询、模块文件跳转、多目标调试等功能,便于用户对问题进行排查和修复、跟踪理解代码执行流程。
调试模式下,支持用户添加断点,但是暂时不支持添加内联断点、条件断点和记录点。调试会话开始后,界面顶部会出现一个调试工具栏,包含以下功能:
-
继续:恢复正常的脚本执行(直到下一个断点);
-
单步跳过:不检查语法和组件,执行这一条语句;
-
单步调试:进入函数体内部,并且停在函数体的第一条语句;
-
单步跳出:当在函数或者循环中时,跳出当前函数或者循环,并且运行到下一个断点;
-
重启:终止当前程序执行,并使用当前运行配置再次开始调试;
-
停止:终止当前程序执行;
单步调试时,若计算中包含模块函数,则可以进入模块的函数体内部进行调试,模块文件内部也支持设置断点,暂不支持对 include 文件的调试。
调试过程中,既支持在运行调试窗口进行变量检查,也支持鼠标悬停的方式进行变量检查。调试中的 print, timer 以及异常信息将会打印在调试控制台中。
为数据分析而生,计算功能更强大
DolphinDB 是一款基于高性能时序数据库,支持复杂分析和流数据处理的实时计算平台,可以说,是专为数据分析而生的。数据分析涵盖了从收集、清洗、处理到分析和解释数据的全过程,可以帮助我们在海量的信息中洞察更深层的价值。
新版本中,我们在函数优化、机器学习支持、加速计算的 JIT 功能扩展以及整体性能上都做了重要更新。
拓展系列函数支持
新版本拓展了 TopN 系列函数和 row 系列函数的支持,具体的特性有:
-
新增支持了 26 个 TopN 相关的窗口函数,包含 2 个 moving TopN 函数,12 个 cum TopN 函数,以及 12 个 time-moving TopN 函数。此外,对 TopN 系列函数新增了设置最小观测窗口的功能(对应参数 tiesMethod)。
-
增强了 row 系列函数对数组向量和列式元组的支持性,新增支持的函数包含 3 个序列相关的 row 函数,5 个常用的 row cum 函数。
此外,我们新增了函数 summary,通过此函数,用户可以快速地获取海量数据的概括性信息,例如平均值、标准差、最小值、最大值和百分位数。
为了更好地支持生物医药领域对基因序列的存储和分析,新版本还新增了用于对 DNA 序列进行编解和解码的函数 encodeShortGenomeSeq(encodeSGS), decodeShortGenomeSeq(decodeSGS),以及用户在滑动窗口内进行 DNA 序列编码的函数 genShortGenomeSeq(genSGS)。
在机器学习方面,新版本优化了 lasso, ElasticNet, Ridge 等函数的性能,并新增了对应的向量化版本函数 lassoBasic。此外,机器学习相关的新特性还有:
-
新增施密特正交化函数 GramSchmidt;
-
提升了 KNN 的预测速度。
完善 JIT 功能,加速计算过程
新版本进一步完善了 JIT 版本的功能,对更多类型和函数进行了支持。此外支持用户通过接口来自定义函数的类型推导规则,添加后即可在 JIT 中使用相应的函数。
JIT 版本新增的类型和函数新特性有:
-
新增支持 complex 类型;
-
新增支持 join(<-) 函数;
-
新增 if 条件表达式中使用 in 运算符;
-
新增支持数据向量使用布尔值进行索引。
多线程快照分发,降低流计算延时
新版本推出流数据多线程分发引擎,用于将快照数据分发给多个响应式引擎并行计算,以实现负载均衡。
此外,流数据层面还有以下新特性:
插件在线安装,生态更完善
插件在 DolphinDB 的生态系统中扮演着重要的角色,提供了额外的灵活性和功能性,更好地适应了不同的使用场景和需求。本次更新我们推出了插件在线安装功能,安装和使用插件将更加便利、高效。
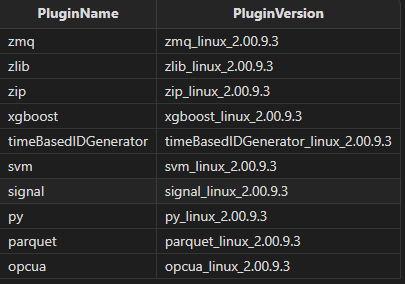
以往使用插件的过程非常费力,需要手动下载、安装相关库文件,并且需要仔细处理好插件与 server 的兼容性。新版本中,我们汇集了所有 DolphinDB 插件,提供了统一的下载和安装方法,并且为用户推荐和 server 版本相匹配的插件,解决兼容性困扰。用户可以在 DolphinDB 中通过调用函数,查看并安装插件。
获取市场的插件列表,包括插件的名称,版本信息。
![]()
安装插件,指定插件市场地址,插件名称,即可一键安装至集群,默认安装至 server 的 plugins 目录。例如安装 mysql 插件,只需执行:
installPlugin("mysql")
性能提升
TSDB 引擎是 DolphinDB 基于 LSM 树自研的存储引擎,它很好地克服了传统 OLAP 引擎在索引、去重、数据更改、宽表存储等方面的局限,功能更加全面。本次的新版本优化了 TSDB 引擎的性能,进一步提升了数据读写的效率和速度,节省了存储和计算资源,降低了运营成本。
此外,新版本还优化了其他函数的计算性能:
稳定性增强
稳定性一直是广大用户最为关注的基本需求之一,不稳定可能会导致数据丢失,或者无法准确、有效地检索数据。这次的新版本中,我们针对死锁、正确性和数据库崩溃等问题进行了修复,提高了产品整体的稳定性,确保满足系统和用户的需求。
修复死锁
-
多个节点同时执行 unsubscribeTable 时,可能产生死锁。
-
local executor 在进行任务调度时,可能产生死锁。
-
对维度表通过 renameTable 修改表名的同时进行查询,可能产生死锁。
修复正确性
-
SQL 查询时使用 distinct 关键字,在某些场景下可能结果不正确。
-
expr 函数中若传入了 DATEHOUR 类型,则结果不正确。
-
对 DECIMAL 类型列应用 unpivot 后,精度丢失。
-
createWindowJoinEngine 的 metrics 中若使用了列的别名,则聚合计算的结果错误。
修复崩溃
-
case when 语句中若使用运算、函数,可能导致 server 崩溃。
-
TSDB 引擎将内存中的数据刷入磁盘时,如果发生内存溢出,可能导致 server 崩溃。
-
createLeftSemiJoinEngine 的 metric 中指定的列名与输入表的列名大小写不一致,可能导致 server 崩溃。
-
对持久化流表并发进行追加数据和保存流表,可能导致 server 崩溃。