摘要:在读多写少的环境中,有没有一种比ReadWriteLock更快的锁呢?有,那就是JDK1.8中新增的StampedLock!
本文分享自华为云社区《【高并发】高并发场景下一种比读写锁更快的锁》,作者: 冰 河。
什么是StampedLock?
ReadWriteLock锁允许多个线程同时读取共享变量,但是在读取共享变量的时候,不允许另外的线程多共享变量进行写操作,更多的适合于读多写少的环境中。那么,在读多写少的环境中,有没有一种比ReadWriteLock更快的锁呢?
答案当然是有!那就是我们今天要介绍的主角——JDK1.8中新增的StampedLock!没错,就是它!
StampedLock与ReadWriteLock相比,在读的过程中也允许后面的一个线程获取写锁对共享变量进行写操作,为了避免读取的数据不一致,使用StampedLock读取共享变量时,需要对共享变量进行是否有写入的检验操作,并且这种读是一种乐观读。
总之,StampedLock是一种在读取共享变量的过程中,允许后面的一个线程获取写锁对共享变量进行写操作,使用乐观读避免数据不一致的问题,并且在读多写少的高并发环境下,比ReadWriteLock更快的一种锁。
StampedLock三种锁模式
这里,我们可以简单对比下StampedLock与ReadWriteLock,ReadWriteLock支持两种锁模式:一种是读锁,另一种是写锁,并且ReadWriteLock允许多个线程同时读共享变量,在读时,不允许写,在写时,不允许读,读和写是互斥的,所以,ReadWriteLock中的读锁,更多的是指悲观读锁。
StampedLock支持三种锁模式:写锁、读锁(这里的读锁指的是悲观读锁)和乐观读(很多资料和书籍写的是乐观读锁,这里我个人觉得更准确的是乐观读,为啥呢?我们继续往下看啊)。其中,写锁和读锁与ReadWriteLock中的语义类似,允许多个线程同时获取读锁,但是只允许一个线程获取写锁,写锁和读锁也是互斥的。
另一个与ReadWriteLock不同的地方在于:StampedLock在获取读锁或者写锁成功后,都会返回一个Long类型的变量,之后在释放锁时,需要传入这个Long类型的变量。例如,下面的伪代码所示的逻辑演示了StampedLock如何获取锁和释放锁。
public class StampedLockDemo{
//创建StampedLock锁对象
public StampedLock stampedLock = new StampedLock();
//获取、释放读锁
public void testGetAndReleaseReadLock(){
long stamp = stampedLock.readLock();
try{
//执行获取读锁后的业务逻辑
}finally{
//释放锁
stampedLock.unlockRead(stamp);
}
}
//获取、释放写锁
public void testGetAndReleaseWriteLock(){
long stamp = stampedLock.writeLock();
try{
//执行获取写锁后的业务逻辑。
}finally{
//释放锁
stampedLock.unlockWrite(stamp);
}
}
}
StampedLock支持乐观读,这是它比ReadWriteLock性能要好的关键所在。 ReadWriteLock在读取共享变量时,所有对共享变量的写操作都会被阻塞。而StampedLock提供的乐观读,在多个线程读取共享变量时,允许一个线程对共享变量进行写操作。
我们再来看一下JDK官方给出的StampedLock示例,如下所示。
class Point {
private double x, y;
private final StampedLock sl = new StampedLock();
void move(double deltaX, double deltaY) { // an exclusively locked method
long stamp = sl.writeLock();
try {
x += deltaX;
y += deltaY;
} finally {
sl.unlockWrite(stamp);
}
}
double distanceFromOrigin() { // A read-only method
long stamp = sl.tryOptimisticRead();
double currentX = x, currentY = y;
if (!sl.validate(stamp)) {
stamp = sl.readLock();
try {
currentX = x;
currentY = y;
} finally {
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
void moveIfAtOrigin(double newX, double newY) { // upgrade
// Could instead start with optimistic, not read mode
long stamp = sl.readLock();
try {
while (x == 0.0 && y == 0.0) {
long ws = sl.tryConvertToWriteLock(stamp);
if (ws != 0L) {
stamp = ws;
x = newX;
y = newY;
break;
}
else {
sl.unlockRead(stamp);
stamp = sl.writeLock();
}
}
} finally {
sl.unlock(stamp);
}
}
}
在上述代码中,如果在执行乐观读操作时,另外的线程对共享变量进行了写操作,则会把乐观读升级为悲观读锁,如下代码片段所示。
double distanceFromOrigin() { // A read-only method
//乐观读
long stamp = sl.tryOptimisticRead();
double currentX = x, currentY = y;
//判断是否有线程对变量进行了写操作
//如果有线程对共享变量进行了写操作
//则sl.validate(stamp)会返回false
if (!sl.validate(stamp)) {
//将乐观读升级为悲观读锁
stamp = sl.readLock();
try {
currentX = x;
currentY = y;
} finally {
//释放悲观锁
sl.unlockRead(stamp);
}
}
return Math.sqrt(currentX * currentX + currentY * currentY);
}
这种将乐观读升级为悲观读锁的方式相比一直使用乐观读的方式更加合理,如果不升级为悲观读锁,则程序会在一个循环中反复执行乐观读操作,直到乐观读操作期间没有线程执行写操作,而在循环中不断的执行乐观读会消耗大量的CPU资源,升级为悲观读锁是更加合理的一种方式。
StampedLock实现思想
StampedLock内部是基于CLH锁实现的,CLH是一种自旋锁,能够保证没有“饥饿现象”的发生,并且能够保证FIFO(先进先出)的服务顺序。
在CLH中,锁维护一个等待线程队列,所有申请锁,但是没有成功的线程都会存入这个队列中,每一个节点代表一个线程,保存一个标记位(locked),用于判断当前线程是否已经释放锁,当locked标记位为true时, 表示获取到锁,当locked标记位为false时,表示成功释放了锁。
当一个线程试图获得锁时,取得等待队列的尾部节点作为其前序节点,并使用类似如下代码判断前序节点是否已经成功释放锁:
while (pred.locked) {
//省略操作
}
只要前序节点(pred)没有释放锁,则表示当前线程还不能继续执行,因此会自旋等待;反之,如果前序线程已经释放锁,则当前线程可以继续执行。
释放锁时,也遵循这个逻辑,线程会将自身节点的locked位置标记为false,后续等待的线程就能继续执行了,也就是已经释放了锁。
StampedLock的实现思想总体来说,还是比较简单的,这里就不展开讲了。
StampedLock的注意事项
在读多写少的高并发环境下,StampedLock的性能确实不错,但是它不能够完全取代ReadWriteLock。在使用的时候,也需要特别注意以下几个方面。
StampedLock不支持重入
没错,StampedLock是不支持重入的,也就是说,在使用StampedLock时,不能嵌套使用,这点在使用时要特别注意。
StampedLock不支持条件变量
第二个需要注意的是就是StampedLock不支持条件变量,无论是读锁还是写锁,都不支持条件变量。
StampedLock使用不当会导致CPU飙升
这点也是最重要的一点,在使用时需要特别注意:如果某个线程阻塞在StampedLock的readLock()或者writeLock()方法上时,此时调用阻塞线程的interrupt()方法中断线程,会导致CPU飙升到100%。例如,下面的代码所示。
public void testStampedLock() throws Exception{
final StampedLock lock = new StampedLock();
Thread thread01 = new Thread(()->{
// 获取写锁
lock.writeLock();
// 永远阻塞在此处,不释放写锁
LockSupport.park();
});
thread01.start();
// 保证thread01获取写锁
Thread.sleep(100);
Thread thread02 = new Thread(()->
//阻塞在悲观读锁
lock.readLock()
);
thread02.start();
// 保证T2阻塞在读锁
Thread.sleep(100);
//中断线程thread02
//会导致线程thread02所在CPU飙升
thread02.interrupt();
thread02.join();
}
运行上面的程序,会导致thread02线程所在的CPU飙升到100%。
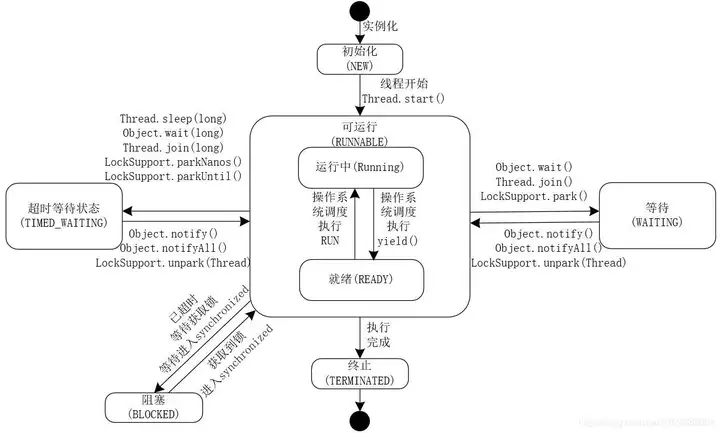
这里,有很多小伙伴不太明白为啥LockSupport.park();会导致thread01会永远阻塞。这里,冰河为你画了一张线程的生命周期图,如下所示。
这下明白了吧?在线程的生命周期中,有几个重要的状态需要说明一下。
- NEW:初始状态,线程被构建,但是还没有调用start()方法。
- RUNNABLE:可运行状态,可运行状态可以包括:运行中状态和就绪状态。
- BLOCKED:阻塞状态,处于这个状态的线程需要等待其他线程释放锁或者等待进入synchronized。
- WAITING:表示等待状态,处于该状态的线程需要等待其他线程对其进行通知或中断等操作,进而进入下一个状态。
- TIME_WAITING:超时等待状态。可以在一定的时间自行返回。
- TERMINATED:终止状态,当前线程执行完毕。
看完这个线程的生命周期图,知道为啥调用LockSupport.park();会使thread02阻塞了吧?
所以,在使用StampedLock时,一定要注意避免线程所在的CPU飙升的问题。那如何避免呢?
那就是使用StampedLock的readLock()方法或者读锁和使用writeLock()方法获取写锁时,一定不要调用线程的中断方法来中断线程,如果不可避免的要中断线程的话,一定要用StampedLock的readLockInterruptibly()方法获取可中断的读锁和使用StampedLock的writeLockInterruptibly()方法获取可中断的悲观写锁。
最后,对于StampedLock的使用,JDK官方给出的StampedLock示例本身就是一个最佳实践了,小伙伴们可以多看看JDK官方给出的StampedLock示例,多多体会下StampedLock的使用方式和背后原理与核心思想。
点击关注,第一时间了解华为云新鲜技术~