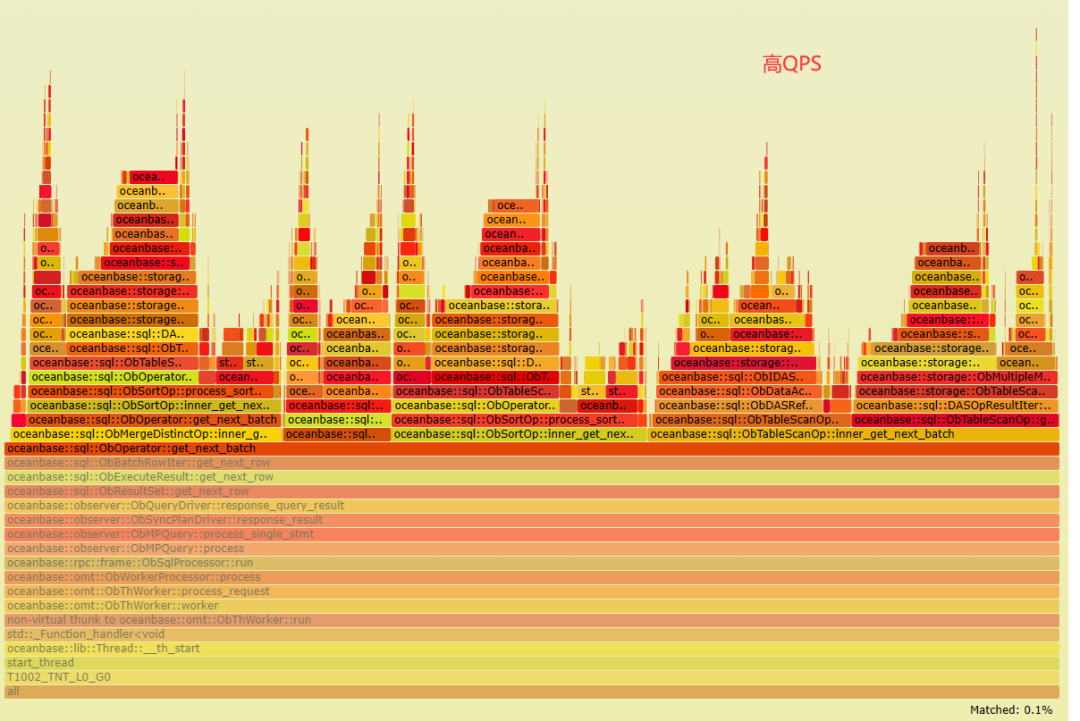
火焰图中指向的方法,会进一步调用 ObMultiVersionMicroBlockRowScanner::inner_get_next_row_impl。后者的主要作用是借嵌套 while 循环进行多版本数据行的读取,并将符合条件的行合并融合(do_compact 中会调用 fuse_row),返回一个合并后的行(ret_row)作为最终结果,源码如下:
int ObMultiVersionMicroBlockRowScanner::inner_get_next_row_impl(const ObDatumRow *&ret_row) { int ret = OB_SUCCESS; // TRUE:For the multi-version row of the current rowkey, when there is no row to be readin this micro_block bool final_result = false; // TRUE:For reverse scanning, if this micro_block has the last row of the previous rowkey bool found_first_row = false; bool have_uncommited_row = false; const ObDatumRow *multi_version_row = NULL; ret_row = NULL;
while (OB_SUCC(ret)) { final_result = false; found_first_row = false; // 定位到当前要读取的位置 if (OB_FAIL(locate_cursor_to_read(found_first_row))) { if (OB_UNLIKELY(OB_ITER_END != ret)) { LOG_WARN("failed to locate cursor to read", K(ret), K_(macro_id)); } } LOG_DEBUG("locate cursor to read", K(ret), K(finish_scanning_cur_rowkey_), K(found_first_row), K(current_), K(reserved_pos_), K(last_), K_(macro_id));
while (OB_SUCC(ret)) { multi_version_row = NULL; bool version_fit = false; // 读取下一行 if (read_row_direct_flag_) { if (OB_FAIL(inner_get_next_row_directly(multi_version_row, version_fit, final_result))) { if (OB_UNLIKELY(OB_ITER_END != ret)) { LOG_WARN("failed to inner get next row directly", K(ret), K_(macro_id)); } } } elseif (OB_FAIL(inner_inner_get_next_row(multi_version_row, version_fit, final_result, have_uncommited_row))) { if (OB_UNLIKELY(OB_ITER_END != ret)) { LOG_WARN("failed to inner get next row", K(ret), K_(macro_id)); } } if (OB_SUCC(ret)) { // 如果读取到的行版本不匹配,则不进行任何操作 if (!version_fit) { // do nothing } // 如果匹配,则进行合并融合 elseif (OB_FAIL(do_compact(multi_version_row, row_, final_result))) { LOG_WARN("failed to do compact", K(ret)); } else { // 记录物理读取次数 if (OB_NOT_NULL(context_)) { ++context_->table_store_stat_.physical_read_cnt_; } if (have_uncommited_row) { row_.set_have_uncommited_row(); } } } LOG_DEBUG("do compact", K(ret), K(current_), K(version_fit), K(final_result), K(finish_scanning_cur_rowkey_), "cur_row", is_row_empty(row_) ? "empty" : to_cstring(row_), "multi_version_row", to_cstring(multi_version_row), K_(macro_id)); // 该行多版本如果在当前微块已经全部读取完毕,就将当前微块的行缓存并跳出内层循环 if ((OB_SUCC(ret) && final_result) || OB_ITER_END == ret) { ret = OB_SUCCESS; if (OB_FAIL(cache_cur_micro_row(found_first_row, final_result))) { LOG_WARN("failed to cache cur micro row", K(ret), K_(macro_id)); } LOG_DEBUG("cache cur micro row", K(ret), K(finish_scanning_cur_rowkey_), "cur_row", is_row_empty(row_) ? "empty" : to_cstring(row_), "prev_row", is_row_empty(prev_micro_row_) ? "empty" : to_cstring(prev_micro_row_), K_(macro_id)); break; } } // 结束扫描,将最终结果放到ret_row,跳出外层循环。 if (OB_SUCC(ret) && finish_scanning_cur_rowkey_) { if (!is_row_empty(prev_micro_row_)) { ret_row = &prev_micro_row_; } elseif (!is_row_empty(row_)) { ret_row = &row_; } // If row is NULL, means no multi_version row of current rowkey in [base_version, snapshot_version) range if (NULL != ret_row) { (const_cast<ObDatumRow *>(ret_row))->mvcc_row_flag_.set_uncommitted_row(false); const_cast<ObDatumRow *>(ret_row)->trans_id_.reset(); break; } } } if (OB_NOT_NULL(ret_row)) { if (!ret_row->is_valid()) { LOG_ERROR("row is invalid", KPC(ret_row)); } else { LOG_DEBUG("row is valid", KPC(ret_row)); if (OB_NOT_NULL(context_)) { ++context_->table_store_stat_.logical_read_cnt_; } } } return ret; }
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。