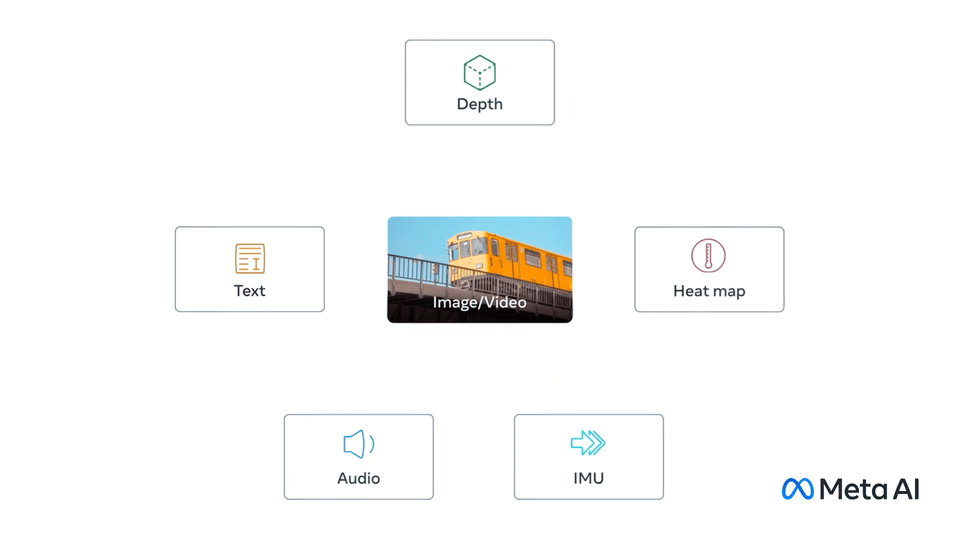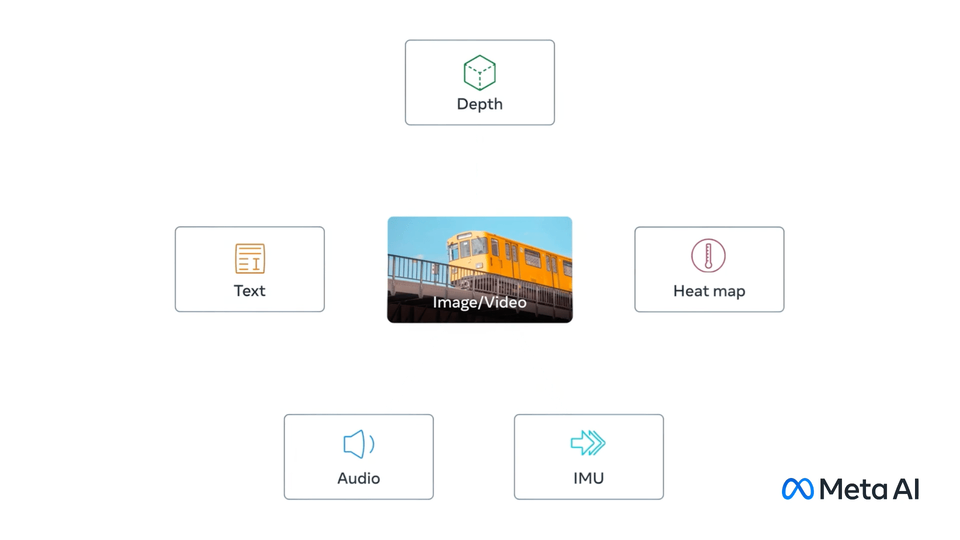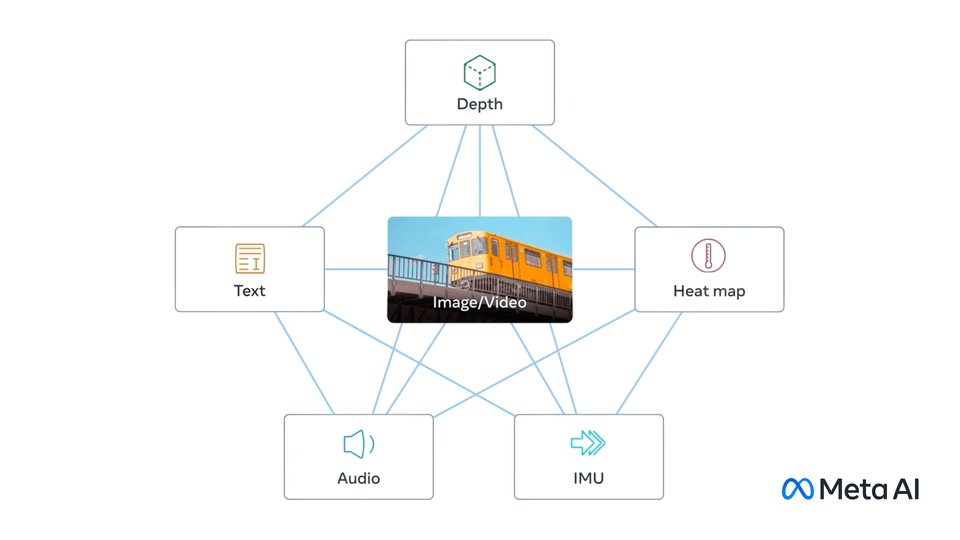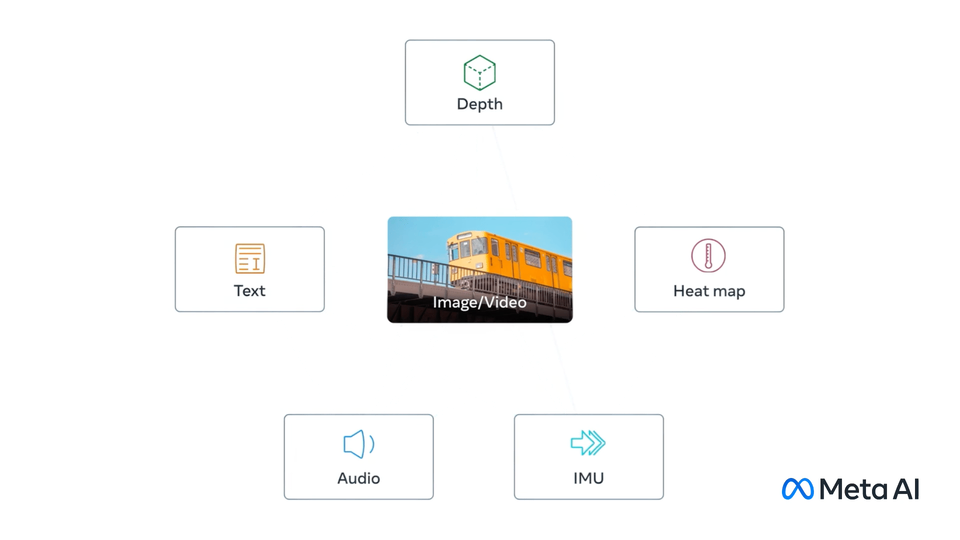
ImageBind 是支持绑定来自六种不同模态(图像、文本、音频、深度、温度和 IMU 数据)的信息的 AI 模型,它将这些信息统一到单一的嵌入式表示空间中,使得机器能够更全面、直接地从多种信息中学习,而无需明确的监督(即组织和标记原始数据的过程)。
ImageBind 通过将文本、图像/视频和音频、视觉、温度还有运动数据流串联在一起,形成一个单一的 embedding space,让机器能从多维度来理解世界,也能创造沉浸式的多感官体验。
![]()
ImageBind 通过将六种模式的嵌入对齐到一个共享的空间,实现了跨模式检索,这就能搜索那些没有同时出现的不同类型的内容。把不同的模式嵌入叠加,可以自然地构造它们的语义。例如 ImageBind 可以与 DALLE-2 解码器和 CLIP 文本一起嵌入,生成音频到图像的映射,就像人类听到声音脑补画面的那种感觉。
示例代码
跨模态(例如图像、文本和音频)提取和比较特征。
import data
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
text_list=["A dog.", "A car", "A bird"]
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Instantiate model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)
# Load data
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
with torch.no_grad():
embeddings = model(inputs)
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Audio x Text: ",
torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
print(
"Vision x Audio: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
)
# Expected output:
#
# Vision x Text:
# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
# [3.3836e-05, 9.9994e-01, 2.4118e-05],
# [4.7997e-05, 1.3496e-02, 9.8646e-01]])
#
# Audio x Text:
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
#
# Vision x Audio:
# tensor([[0.8070, 0.1088, 0.0842],
# [0.1036, 0.7884, 0.1079],
# [0.0018, 0.0022, 0.9960]])