监控系统是运维工作中不可或缺的一项技术,一个好的监控系统能够对设备和系统的关键指标实时采集、存储、分析、告警,真正做到“事前预警,事后追踪”,从而大大降低运维成本,提高运维效率。
openGemini提供了260+项丰富的内核运行状态和设备运行监控指标,来满足我们日常的监控告警需求和帮助问题定位,本文将着重介绍如何搭建openGemini的内核运行实时监控系统。
整体部署
监控系统的整体部署方案如下图所示:
![]()
该方案包含监控数据生产、采集、存储、分析告警和展示等所有功能,主要由四部分组成:
openGemini集群: 随着业务运行,openGemini持续输出内核运行状态的各项指标数据。openGemini同时支持两种方式输出指标数据,第一种将指标数据输出到日志中;第二种则为HTTP方式,采用openGemini的数据格式,接收端需使用InfluxDB或openGemini这两种数据库均可。
指标采集:如上所述,采用HTTP方式输出指标数据,则无需额外的数据采集工具,但会缺乏一些监控指标,如磁盘利用率、创建的表总数、时间线数量、创建的数据库总数等。
如果将数据输出到日志中时,则需要使用ts-monitor进行指标数据采集,除内核运行状态指标数据之外,ts-monitor工具还将采集如磁盘利用率、创建的表总数、时间线数量、创建的数据库总数等指标。ts-monitor同样将指标数据转换为openGemini的数据格式进行上报。
数据存储:考虑到监控系统频繁的查询操作,长期来看,为避免对业务集群的运行资源造成竞争,从而影响业务效率,因此建议将指标数据转存到专门的存储节点。openGemini提供了单机和集群两种版本,通常对于集群自身的指标数据保存,单机性能已然足够。与此同时,openGemini同样支持Grafana,且单机性能更优于InfluxDB,建议直接使用openGemini单机版部署,用于存储监控指标数据。
数据可视化与告警:Grafana是业界非常普遍使用的一款开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。选择它用在监控系统中最合适不过。
综上所述,该方案的优点是部署简单、易获取(所有组件开源)。接下来将重点介绍不同数据采集方式对应的部署和配置。
方式一:使用ts-monitor从业务日志中采集监控指标数据
![]()
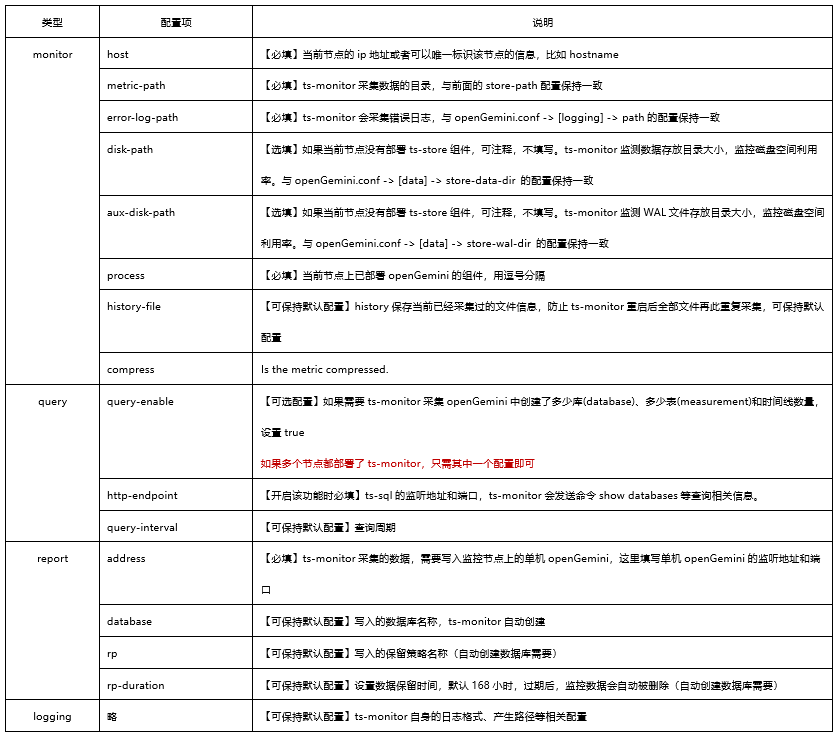
如图所示,监控数据以log files方式输出的方式需要在业务集群的每个节点中部署一个ts-monitor,用来从该节点上所有openGemini组件产生的监控日志中采集监控指标数据,然后将数据写入到远端监控节点上的openGemini中,最后使用Grafana作为监控/告警面板来读取单机版openGemini中的监控数据。
该部署方式下,业务集群的openGemini组件的配置文件openGemini.conf必要配置项如下图所示,各配置项说明如表一所示,当前配置会将openGemini组件的监控日志每隔10秒写一次到/home/openGemini/metric/metric.data中。
表一 log files方式业务集群配置项说明
![]()
示例
[monitor]
pushers = "file"
store-enabled = true
store-database = "monitor"
store-interval = "10s"
store-path = "/tmp/openGemini/metric/ts-sql/metric.data"
compress = false
# http-endpoint = ""
# username = ""
# password = ""
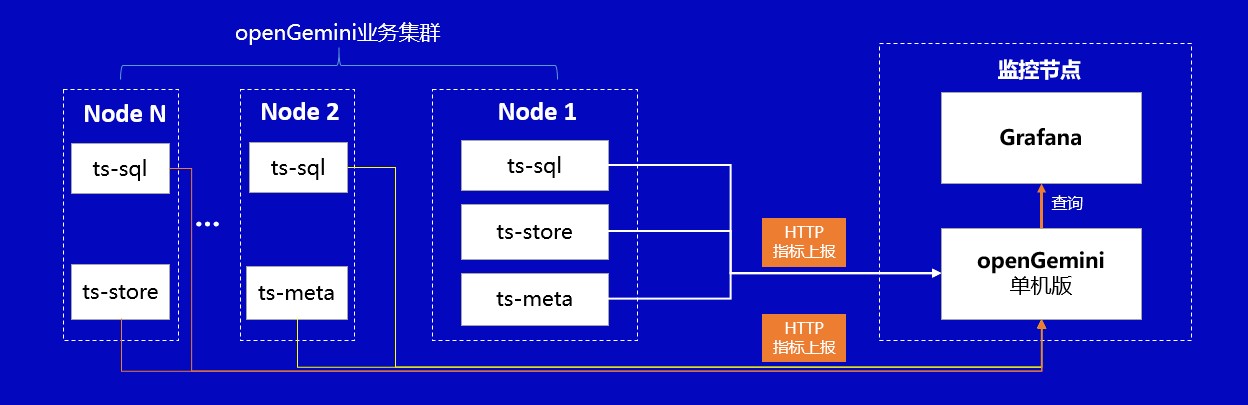
该部署方式下,业务集群中ts-monitor的配置文件monitor.conf的配置项说明如表二所示。
表二 ts-monitor配置项说明
![]()
其中monitor的必填项需要与业务集群中openGemini组件的配置保持一致,query开启表示一些与数据模式、数据统计相关的查询结果是否可以向ts-monitor上报,report中填写的是监控节点的有关信息需要与监控节点的openGemini.conf保持一致。
示例
[monitor]
host = "192.70.3.42"
metric-path = "/tmp/openGemini/metric"
error-log-path = "/tmp/openGemini/logs"
disk-path = "/tmp/openGemini/data"
aux-disk-path = "/tmp/openGemini/data/wal"
process = "ts-store,ts-meta"
history-file = "history.txt"
# Is the metric compressed.
compress = false
[query]
# query for some DDL. Report for these data to monitor cluster.
# - SHOW DATABASES
# - SHOW MEASUREMENTS
# - SHOW SERIES CARDINALITY FROM mst
query-enable = false
http-endpoint = "192.70.3.42:8086"
query-interval = "5m"
[report]
address = "192.70.3.43:8086"
database = "monitor"
rp = "autogen"
rp-duration = "168h"
[logging]
format = "auto"
level = "info"
path = "/tmp/openGemini/logs/"
max-size = "64m"
max-num = 30
max-age = 7
compress-enabled = true
方式二:监控指标数据直接push到监控节点
![]()
如图所示,监控数据直接push到监控节点的方式不需要在业务集群中部署ts-monitor,但这种情况下要求业务集群能够直连监控节点并且会缺乏一些监控指标,如磁盘利用率、创建的表总数、时间线数量、创建的数据库总数等。
该方式下,业务集群的openGemini组件的配置文件openGemini.conf必要配置项如下表所示,当前配置会将监控数据每隔10秒写一次到监控节点“192.70.3.43:8086”的“monitor”数据库中。
![]()
示例
[monitor]
pushers = "http"
store-enabled = true
store-database = "monitor"
store-interval = "10s"
# store-path = "/tmp/openGemini/metric/ts-sql/metric.data"
# compress = false
http-endpoint = "192.70.3.43:8086"
# username = ""
# password = ""
Grafana配置
Grafana安装过程略,启动Grafana后,通过浏览器访问http://192.70.3.43:3000 ,添加数据源选择InfluxDB(openGemini兼容InfluxDB)。
![]()
进入创建数据源界面,其中name填写为新创建的数据源的名称,URL为监控节点上openGemini的地址和端口,database为监控数据所在数据库名称。
![]()
图四 数据源创建
数据源创建完成后可以在Grafana中新建看板来完成监控用户感兴趣的内容,如下图所示,建立一个Panel,选择Data source为刚刚建立的monitor,然后通过图形化查询选择界面来建立看板的查询语句。
![]()
看板创建示例
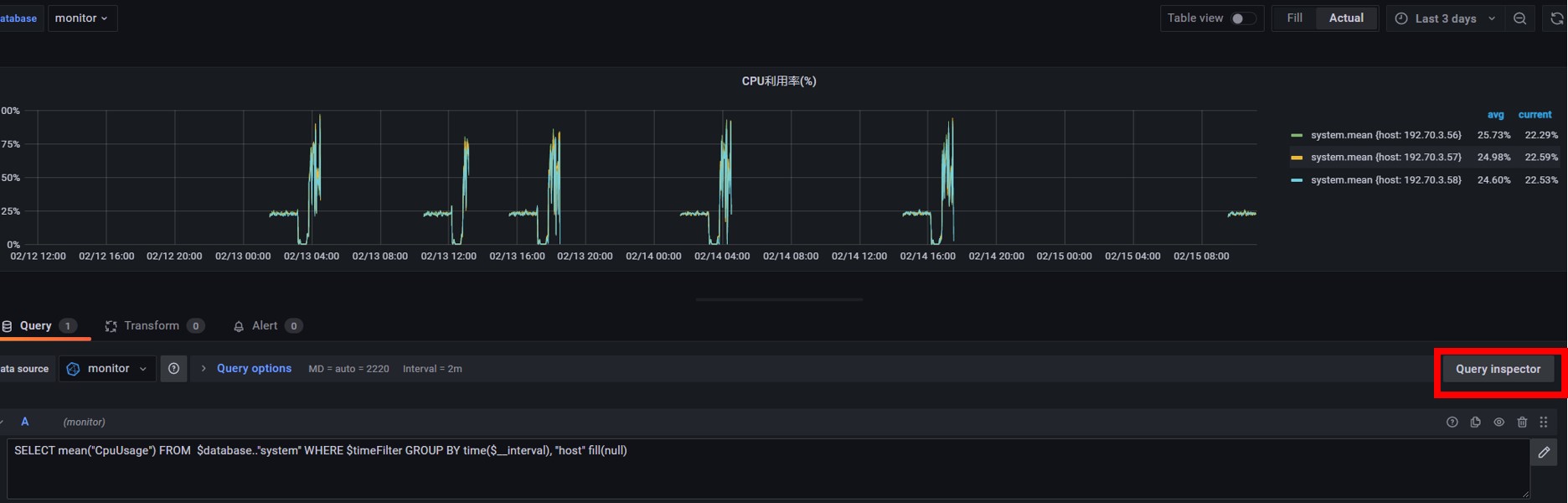
除了使用图形化界面查询,也可以点击“Query Inspector”来使用直接输入查询语句的方式建立Panel。如下图所示,先选择数据源为刚才建立的“monitor”,然后可以通过查询语句“SELECT mean("CpuUsage") FROM $database.."system" WHERE $timeFilter GROUP BY time($__interval), "host" fill(null)”来查询数据库中cpu的平均使用率。
![]()
输入查询语句的方式创建Panel示例
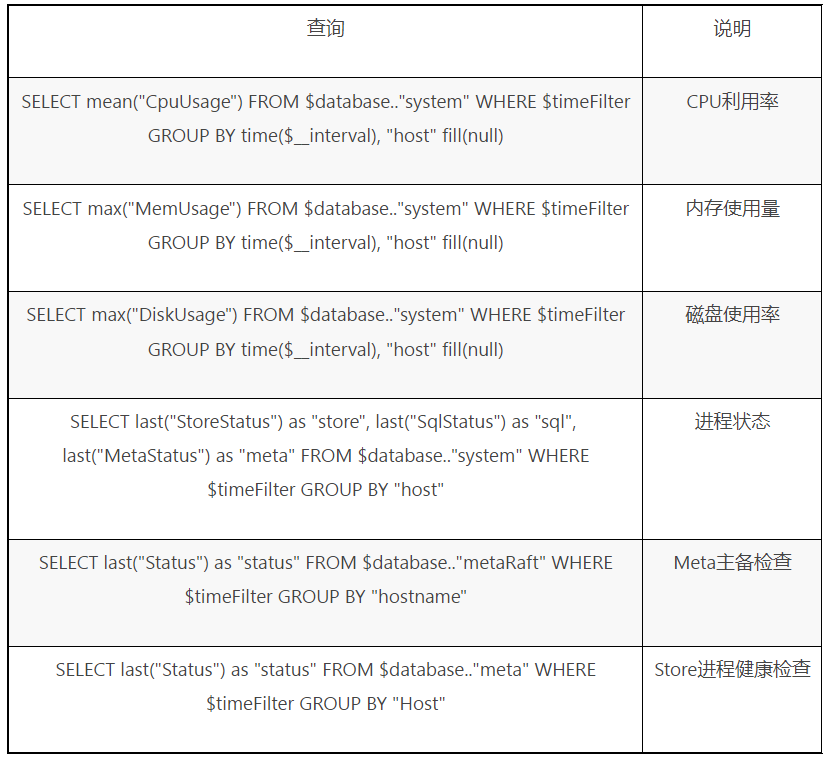
除了“CpuUsage”监控数据还包括其他的一些指标用来建立监控面板,例如跟集群整体健康状态相关的一些查询如下表所示。
表三 集群整体健康状态相关查询
![]()
总结
本文旨在帮助用户快速上手搭建openGemini的实时监控系统,希望能对大家有所帮助。文中并未提及单机版本的监控,单机版的监控与集群相同。
任何问题,可通过社区联系方式找到我们,或者提交issue到社区,我们第一时间会进行回复。
openGemini是一个共享、共建、共治的开放社区,欢迎大家参与!
更多资讯,欢迎关注openGemini社区公众号