更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
ByteHouse 是火山引擎上的一款云原生数据仓库,为用户带来极速分析体验,能够支撑实时数据分析和海量离线数据分析;便捷的弹性扩缩容能力,极致的分析性能和丰富的企业级特性,助力客户数字化转型。
本文将从需求动机、技术实现及实际应用等角度,介绍基于不同架构的 ByteHouse 实时导入技术演进。
内部业务的实时导入需求
ByteHouse 实时导入技术的演进动机,起初于字节跳动内部业务的需求。
在字节内部,ByteHouse 主要还是以 Kafka 为实时导入的主要数据源(本文都以 Kafka 导入为例展开描述,下文不再赘述)。对于大部分内部用户而言,其数据体量偏大;所以用户更看重数据导入的性能、服务的稳定性以及导入能力的可扩展性。而对于数据延时性,大多数用户只要是秒级可见就能满足其需求。基于这样的场景,ByteHouse 进行了定制性的优化。
分布式架构下的高可用
社区原生分布式架构
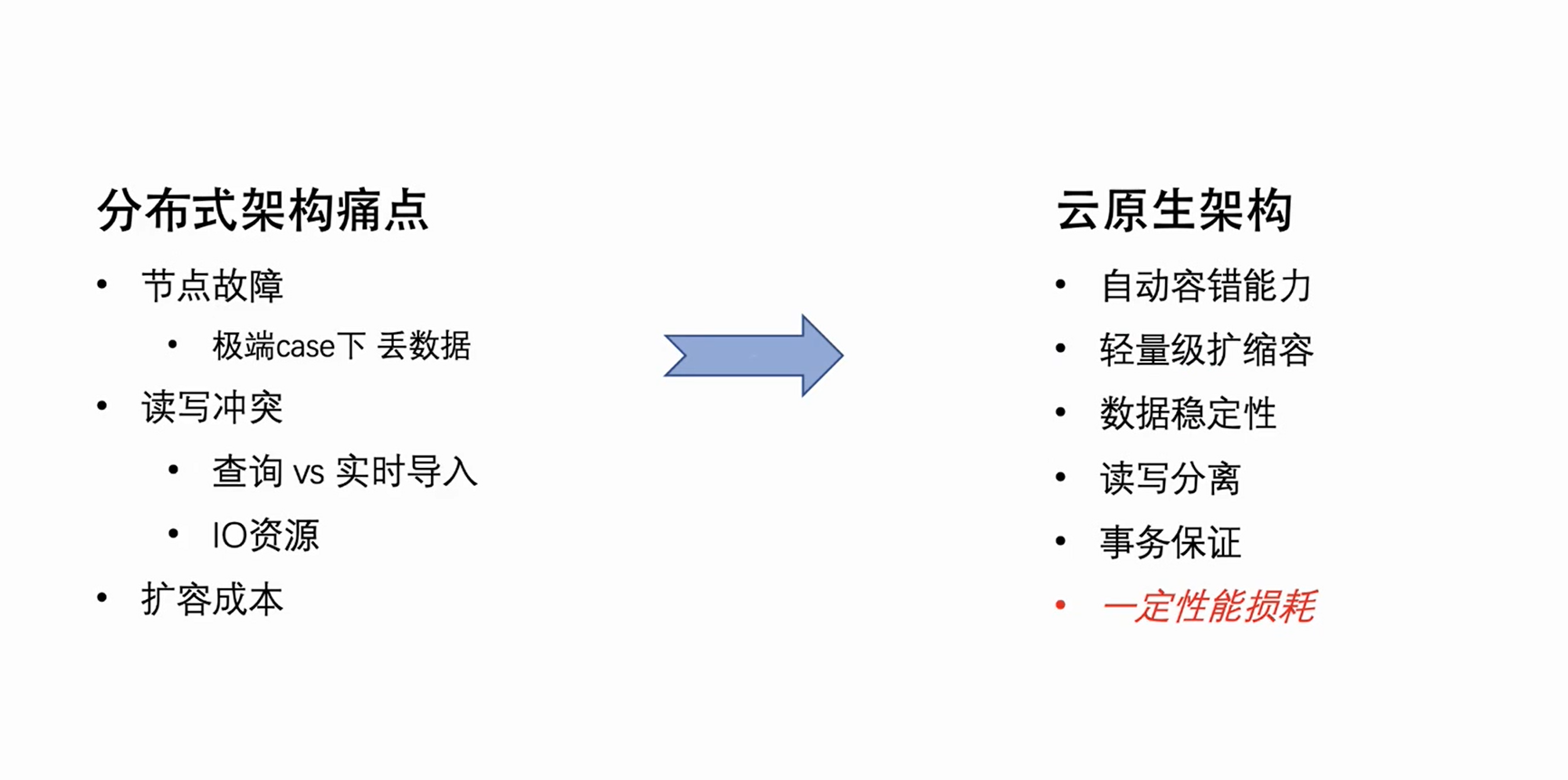
ByteHouse 首先沿用了 Clickhouse 社区的分布式架构,但分布式架构有一些天然性架构层面的缺陷,这些痛点主要表现在三个方面:
节点故障:当集群机器数量到达一定规模以后,基本每周都需要人工处理节点故障。对于单副本集群在某些极端 case 下,节点故障甚至会导致数据丢失。
读写冲突:由于分布式架构的读写耦合,当集群负载达到一定程度以后,用户查询和实时导入就会出现资源冲突——尤其是 CPU 和 IO,导入就会受到影响,出现消费 lag。
扩容成本:由于分布式架构数据基本都是本地存储,在扩容以后,数据无法做 Reshuffle,新扩容的机器几乎没有数据,而旧的机器上磁盘可能已经快写满,造成集群负载不均的状态,导致扩容并不能起到有效的效果。
这些是分布式架构天然的痛点,但是由于其天然的并发特性,以及本地磁盘数据读写的极致性能优化,可以说有利有弊。
社区实时导入设计
基于分布式架构的实时导入核心设计其实就是两级并发:
一个 CH 集群通常有多个 Shard,每个 Shard 都会并发做消费导入,这就是第一级 Shard 间的多进程并发;
每个 Shard 内部还可以使用多个线程并发消费,从而达到很高的性能吞吐。
就单个线程来说,基本消费模式是攒批写入——消费一定的数据量,或者一定时间之后,再一次性写入。攒批写入可以更好地实现性能优化,查询性能提升,并降低后台 Merge 线程的压力。
无法满足的需求
上述社区的设计与实现,还是无法满足用户的一些高级需求:
首先部分高级用户对数据的分布有着比较严格的要求,比如他们对于一些特定的数据有特定的 Key,希望相同 key 的数据落盘到同一个 Shard(比如唯一键需求)。这种情况下,社区 High Level 的消费模式是无法满足的。
其次是 High level 的消费形式 rebalance 不可控,可能最终会导致 Clickhouse 集群中导入的数据在各个 Shard 之间分配不均。
当然,消费任务的分配不可知,在一些消费异常情景下,想要排查问题也变得非常困难;对于一个企业级应用,这是难以接受的。
自研分布式架构消费引擎 HaKafka
为了解决上述需求,ByteHouse 团队基于分布式架构自研了一种消费引擎——HaKafka。
高可用(Ha)
HaKafka 继承了社区原有 Kafka 表引擎的消费优点,再重点做了高可用的 Ha 优化。
就分布式架构来谈,其实每个 Shard 内可能都会有多个副本,在每个副本上都可以做 HaKafka 表的创建。但是 ByteHouse 只会通过 ZK 选一个 Leader,让 Leader 来真正地执行消费流程,其他节点位于 Stand by 状态。当 Leader 节点不可用了,ZK 可以在秒级将 Leader 切到 Stand by 节点继续消费,从而实现一种高可用。
Low—Level 消费模式
HaKafka 的消费模式从 High Level 调整到了 Low Level 模式。Low Level 模式可以保证 Topic Partition 有序和均匀地分配到集群内各个 shard;与此同时,Shard 内部可以再一次用多线程,让每个线程来消费不同 Partition。从而完全继承了社区 Kafka 表引擎两级并发的优点。
在 Low-Level 消费模式下,上游用户只要在写入 Topic 的时候,保证没有数据倾斜,那么通过 HaKafka 导入到 Clickhouse 里的数据肯定也是均匀分布在各个 shard 的。
同时,对于有特殊数据分布需求——将相同 Key 的数据写到相同 Shard——的高级用户,只要在上游保证相同 Key 的数据写入相同 Partition,那么导入 ByteHouse 也就能完全满足用户需求,很好地支持唯一键等场景。
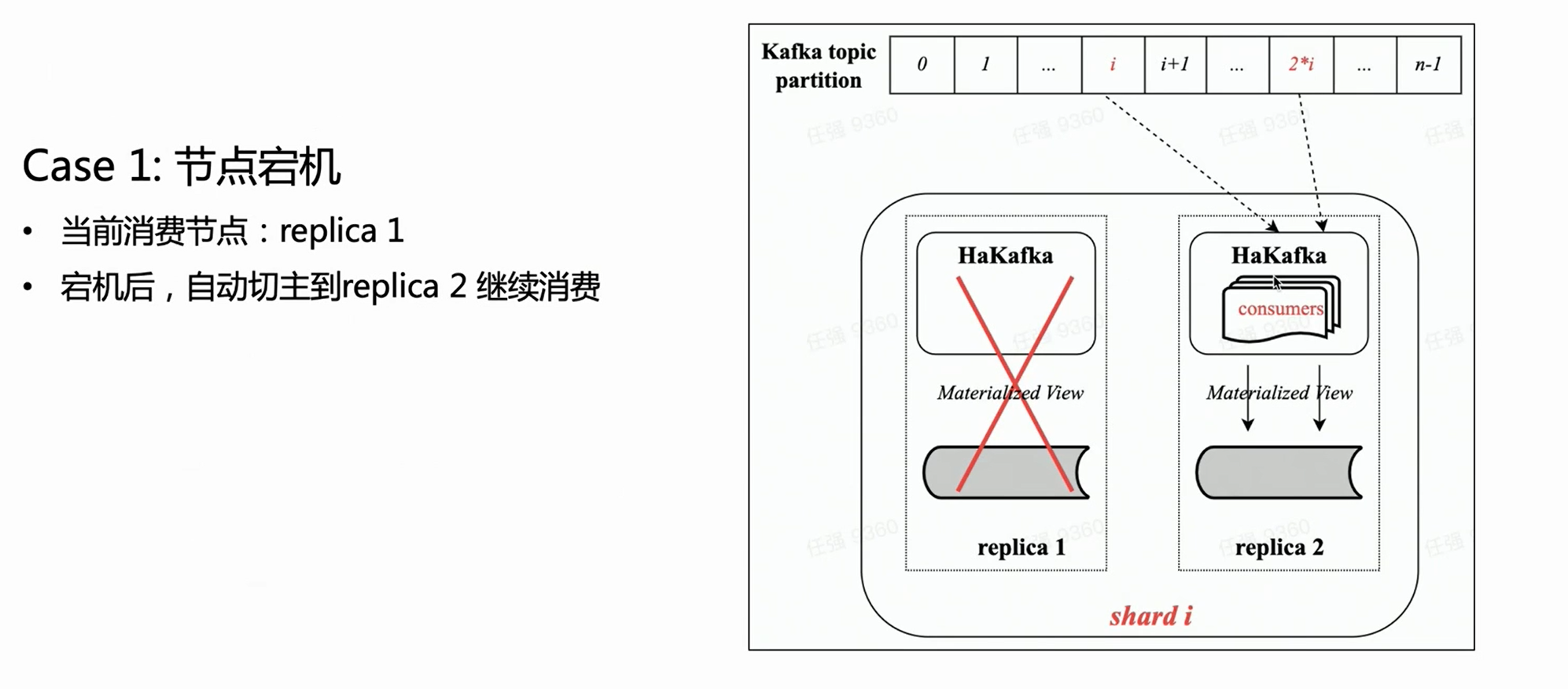
场景一:
基于上图可见,假设有一个双副本的 Shard,每个副本都会有一张相同的 HaKafka 表处于 Ready 的状态。但是只有通过 ZK 选主成功的 leader 节点上,HaKafka 才会执行对应的消费流程。当这个 leader 节点宕机以后, 副本 Replica 2 会自动再被选为一个新的 Leader,继续消费,从而保证高可用。
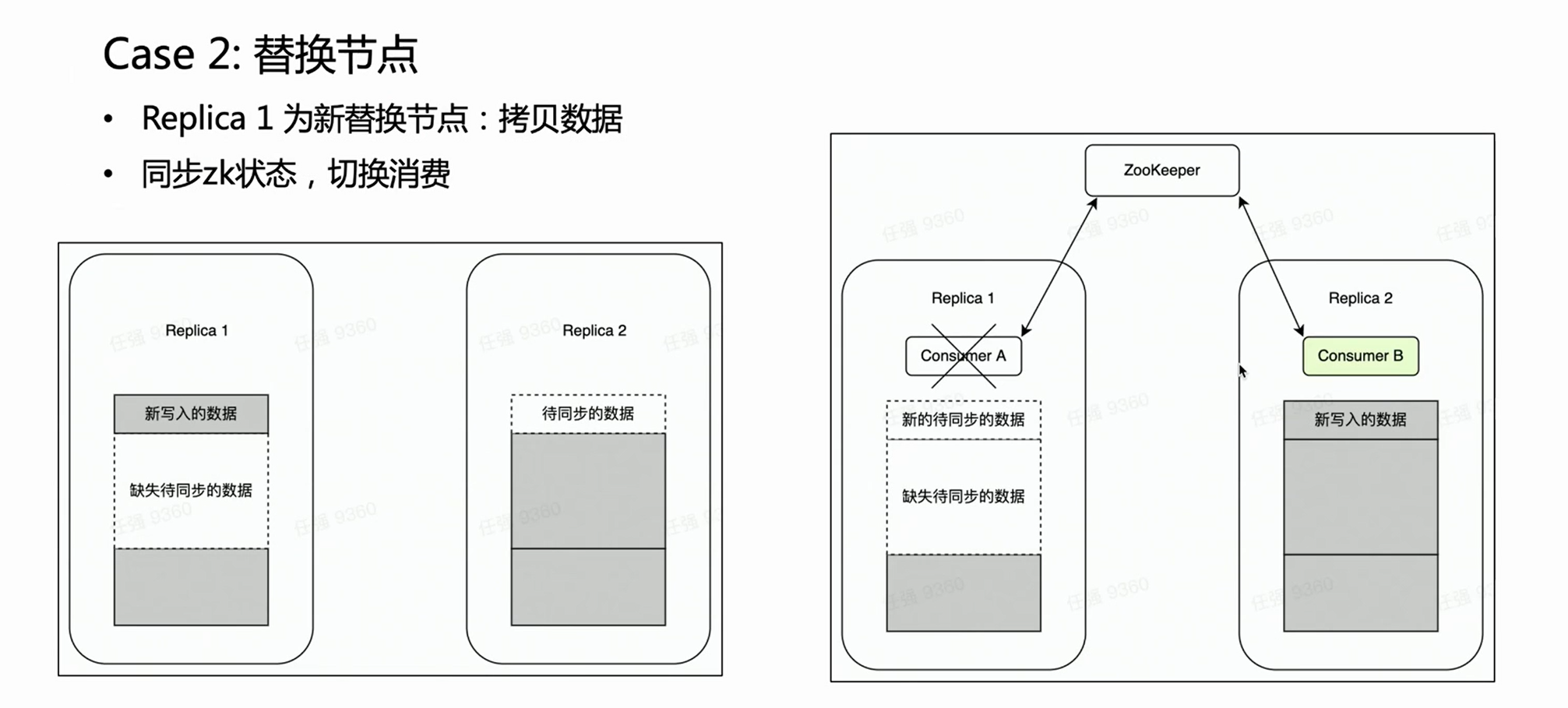
场景二:
在节点故障场景下,一般需要执行替换节点流程。对于分布式节点替换有一个很繁重的操作——拷贝数据。
如果是一个多副本的集群,一个副本故障,另一个副本是完好的。我们很自然希望在节点替换阶段,Kafka 消费放在完好的副本 Replica 2 上,因为其上旧数据是完备的。这样 Replica 2 就始终是一个完备的数据集,可以正常对外提供服务。这一点 HaKafka 是可以保证的。HaKafka 选主的时候,如果确定有某一个节点在替换节点流程当中,会避免将其选为 Leader。
导入性能优化:Memory Table
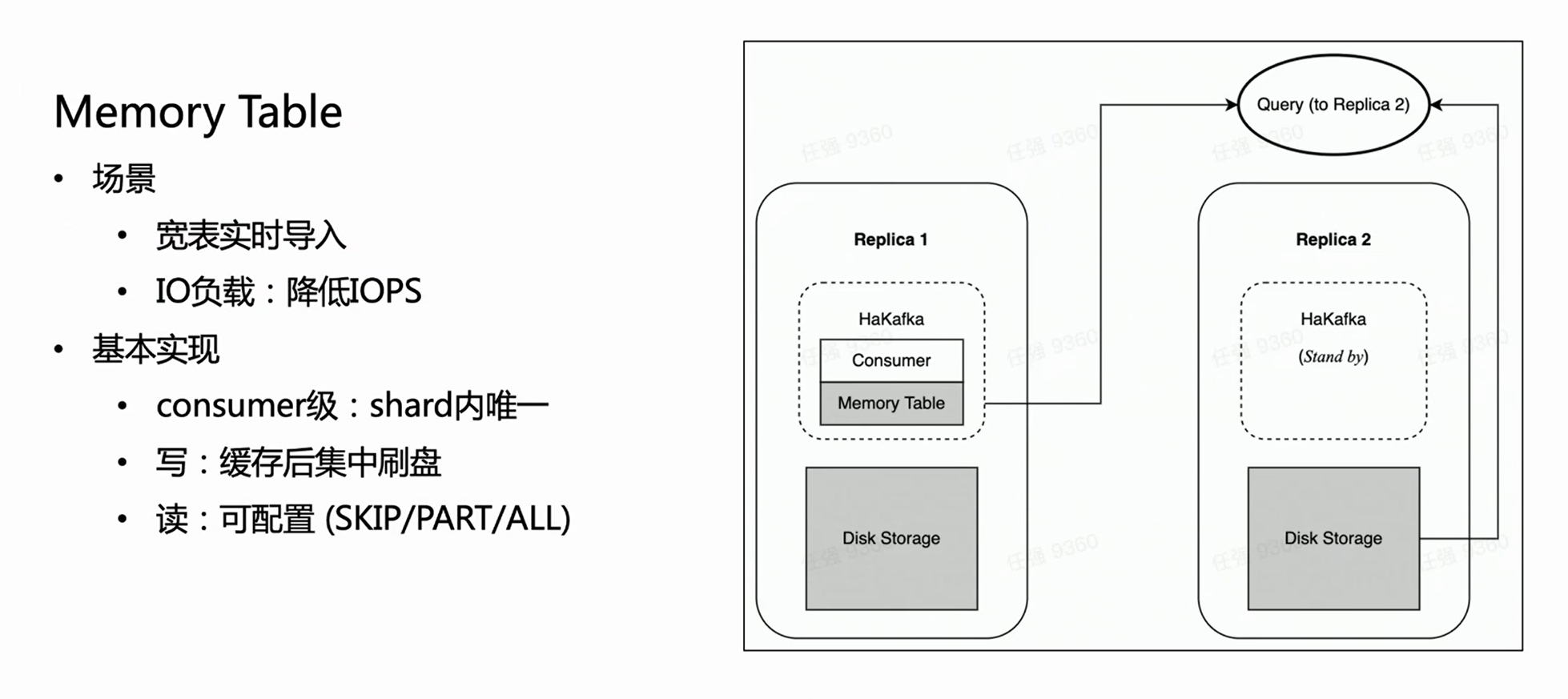
HaKafka 还做到了 Memory Table 的优化。
考虑这样一个场景:业务有一个大宽表,可能有上百列的字段 或者上千的 Map-Key。由于 ClickHouse 每一个列都会对应落盘为一个具体的文件,列越多,每次导入写的文件也就越多。那么,相同消费时间内,就会频繁地写很多的碎文件,对于机器的 IO 是很沉重的负担,同时给 MERGE 带来很大压力;严重时甚至导致集群不可用。为了解决这种场景,我们设计了 Memory Table 实现导入性能优化。
Memory Table 的做法就是每一次导入数据不直接刷盘,而是存在内存中;当数据达到一定量以后,再集中刷盘,减少 IO 操作。Memory Table 可以提供对外查询服务的,查询会路由到消费节点所在的副本去读 memory table 里边的数据,这样保证了不影响数据导入的延时性。从内部使用经验来看,Memory Table 不仅很好地解决了部分大宽表业务导入需求,而且导入性能最高可以提升 3 倍左右。
云原生新架构
鉴于上文描述的分布式架构的天然缺陷,ByteHouse 团队一直致力于对架构进行升级。我们选择了业务主流的云原生架构,新的架构在 2021 年初开始服务字节内部业务,并于 2023 年初进行了代码开源(ByConity)。
云原生架构本身有着很天然的自动容错能力以及轻量级的扩缩容能力。同时,因为它的数据是云存储的,既实现了存储计算分离,数据的安全性和稳定性也得到了提高。当然,云原生架构也不是没有缺点,将原来的本地读写改为远端读写,必然会带来一定的读写性能损耗。但是,以一定的性能损耗来换取架构的合理性,降低运维成本,其实是利大于弊的。
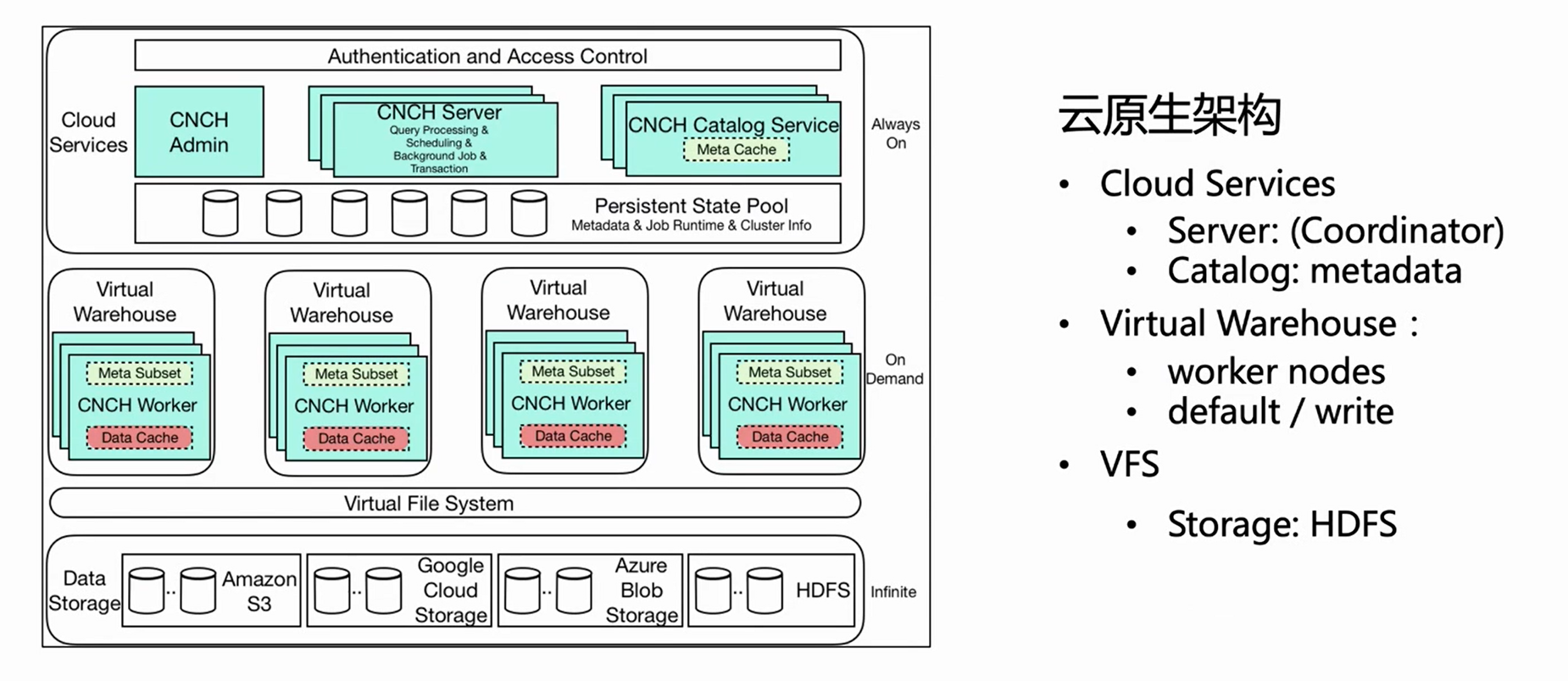
上图是 ByteHouse 云原生架构的架构图,本文针对实时导入这块介绍几个重要的相关组件。
首先,总架构分为三层,第一层是 Cloud Service,主要包含 Server 和 Catlog 两个组件。 这一层是服务入口,用户的所有请求包括查询导入都从 Server 进入。 Server 只对请求做预处理,不具体执行;在 Catlog 查询元信息后,把预处理的请求和元信息下发到 Virtual Warehouse 执行。
Virtual Warehouse 是执行层。不同的业务,可以有独立的 Virtual Warehouse,从而做到资源隔离。现在 Virtual Warehouse 主要分为两类,一类是 Default,一类是 Write,Default 主要做查询,Write 做导入,实现读写分离。
最底层是 VFS(数据存储),支持 HDFS、S3、aws 等云存储组件。
基于云原生架构的实时导入设计
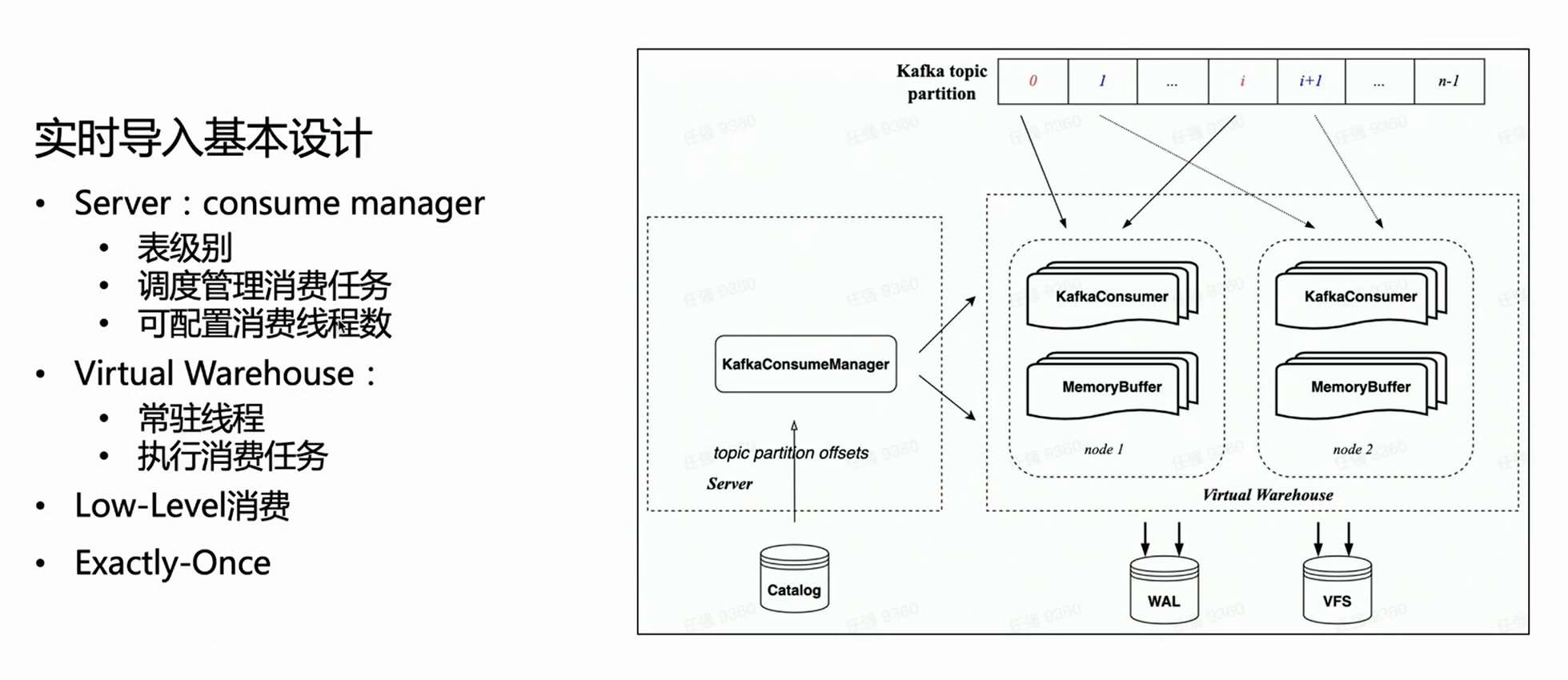
在云原生架构下,Server 端不做具体的导入执行,只做任务管理。因此在 Server 端,每个消费表会有一个 Manager,用来管理所有的消费执行任务,并将其调度到 Virtual Warehouse 上执行。
因为继承了 HaKafka 的 Low Level 消费模式,Manager 会根据配置的消费任务数量,将 Topic Partition 均匀分配给各个任务;消费任务的数量是可配置的,上限是 Topic Partition 数目。
基于上图,大家可以看到左边是 Manager ,从 catalog 拿到对应的 Offset,然后根据指定的消费任务数目,来分配对应的消费 Partition、并调度到 Virtual Warehouse 的不同节点来执行。
新的消费执行流程
因为云原生新架构下是有事务 Transaction 保证的,所有操作都希望在一个事务内完成,也更加的合理化。
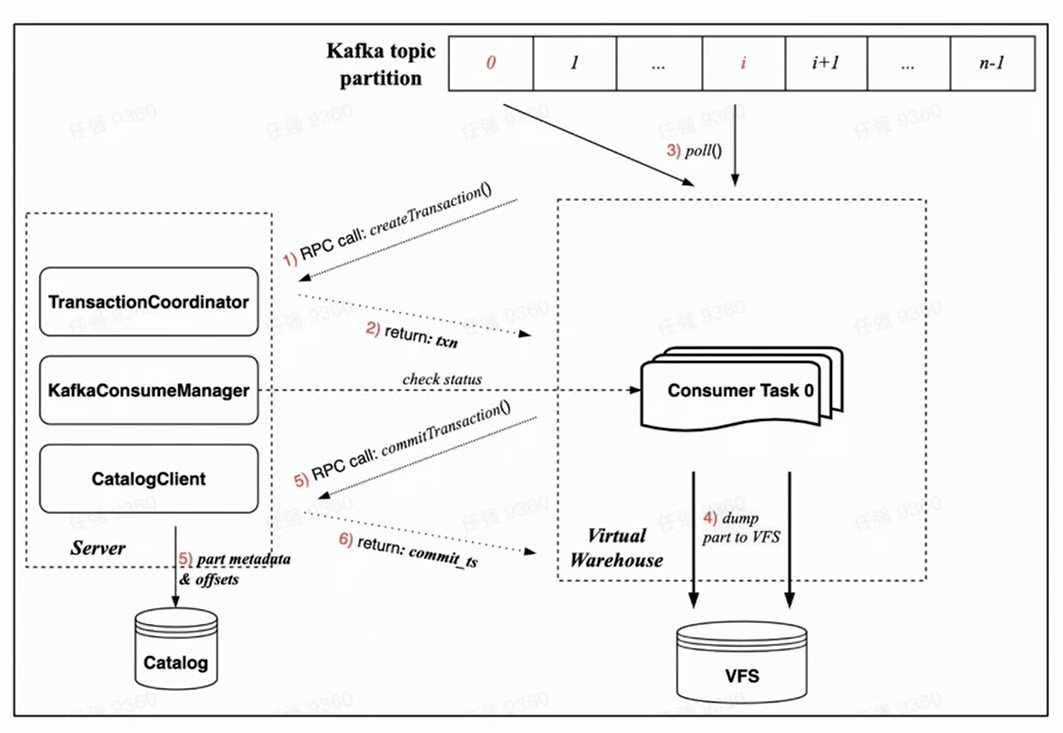
依托云原生新架构下的 Transaction 实现,每个消费任务的消费流程主要包括以下步骤:
消费开始前,Worker 端的任务会先通过 RPC 请求,向 Server 端请求创建一个事务;
执行 rdkafka::poll(),消费一定时间(默认 8s)或者足够大的 block;
将 block 转化为 Part 并 Dump 到 VFS(此时数据不可见);
通过 RPC 请求向 Server 发起事务 Commit 请求
(事务中 Commit 的数据包括:dump 完成的 part 元数据以及对应 Kafka offset)
事务提交成功(数据可见)
容错保证
从上述消费流程里可以看到,云原生新架构下的消费,容错保证主要是基于 Manager 和 Task 的双向心跳以及快速失败策略:
Manager 本身会有一个定期的探活,通过 RPC 检查调度的 Task 是否在正常执行;
同时每个 Task 会在消费中借助事务 RPC 请求来校验自己的有效性,一旦校验失败,它可以自动 kill;
而 Manager 一旦探活失败,则会立即拉起一个新的消费任务,实现秒级的容错保证。
消费能力
关于消费能力的话,上文提到它是一个可扩展性的,消费任务数量可以由用户来配置,最高可以达到 Topic 的 Partition 数目。如果 Virtual Warehouse 中节点负载高的话,也可以很轻量地扩节点。
当然,Manager 调度任务实现了基本的负载均衡保证——用 Resource Manager 来做任务的管理和调度。
语义增强:Exactly—Once
最后,云原生新架构下的消费语义也有一个增强——从分布书架构的 At-Least-Once 升级到 Exactly—Once。
因为分布式架构是没有事务的,只能做到一个 At-Least-Once,就是任何情况下,保证不丢数据,但是一些极端情况可能会有重复消费发生。到了云原生架构,得益于 Transaction 的实现,每一次消费都可以通过事务让 Part 和 Offset 实现原子性提交,从而达到 Exactly—Once 的语义增强。
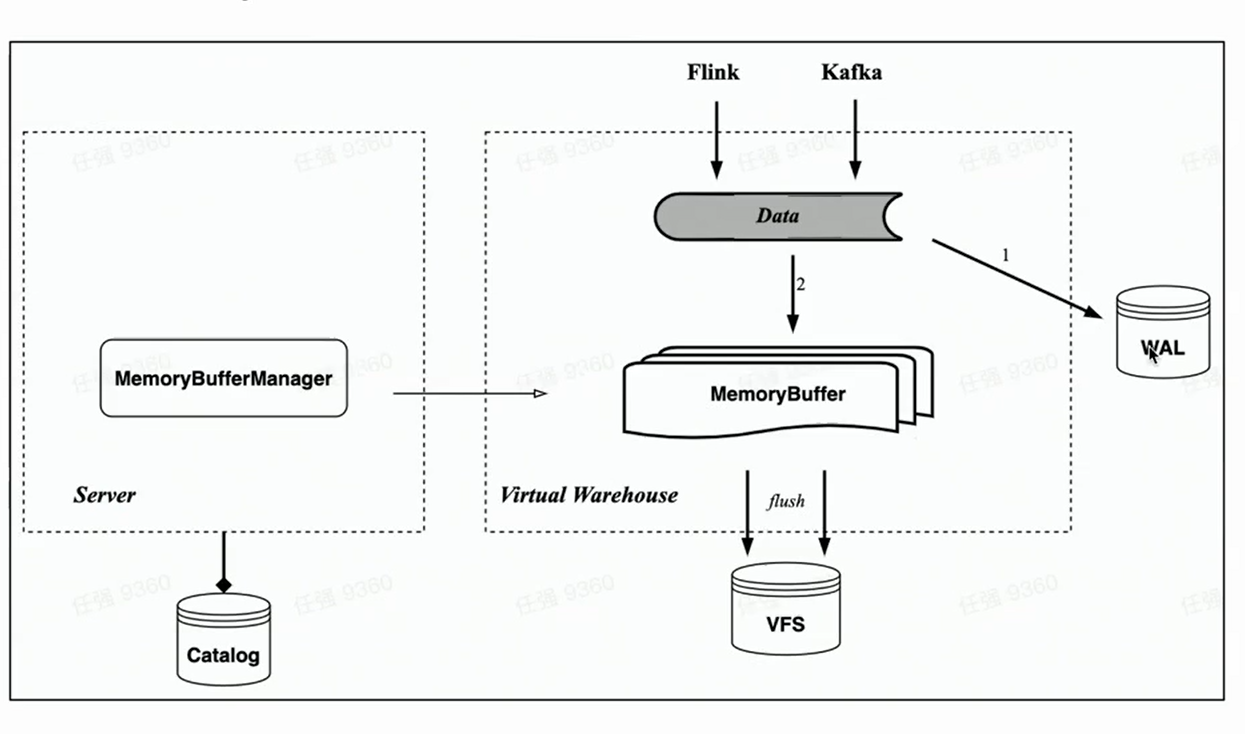
Memory buffer
对应 HaKafka 的 memory table,云原生架构同样实现了导入内存缓存 Memory Buffer。
与 Memory Table 不同的是,Memory Buffer 不再绑定到 Kafka 的消费任务上,而是实现为存储表的一层缓存。这样 Memory Buffer 就更具有通用性,不仅是 Kafka 导入可以使用,像 Flink 小批量导入的时候也可以使用。
同时,我们引入了一个新的组件 WAL 。数据导入的时候先写 WAL,只要写成功了,就可以认为数据导入成功了——当服务启动后,可以先从 WAL 恢复未刷盘的数据;之后再写 Memory buffer,写成功数据就可见了——因为 Memory Buffer 是可以由用户来查询的。Memory Buffer 的数据同样定期刷盘,刷盘后即可从 WAL 中清除。
业务应用及未来思考
最后简单介绍实时导入在字节内部的使用现状,以及下一代实时导入技术的可能优化方向。
ByteHouse 的实时导入技术是以 Kafka 为主,每天的数据吞吐是在 PB 级,导入的单个线程或者说单个消费者吞吐的经验值在 10-20MiB/s。(这里之所以强调是经验值,因为这个值不是一个固定值,也不是一个峰值;消费吞吐很大程度上取决于用户表的复杂程度,随着表列数增加,导入性能可能会显著降低,无法使用一个准确的计算公式。因此,这里的经验值更多的是字节内部大部分表的导入性能经验值。)
除了 Kafka,字节内部其实还支持一些其他数据源的实时导入,包括 RocketMQ、Pulsar、MySQL(MaterializedMySQL)、 Flink 直写等。
关于下一代实时导入技术的简单思考:
点击跳转 ByteHouse云原生数据仓库 了解更多