Taier 介绍
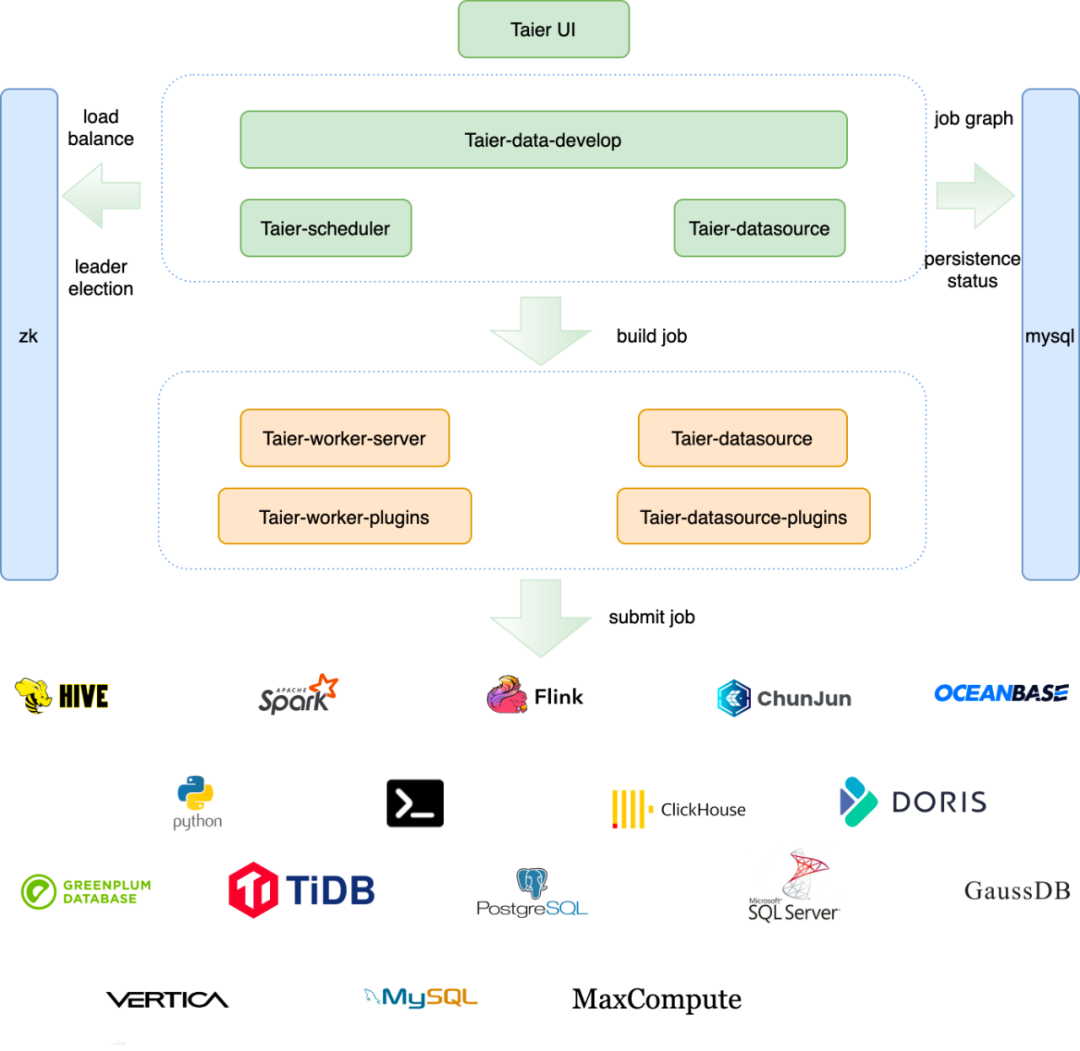
Taier 是袋鼠云开源项目之一,是一个分布式可视化的DAG任务调度系统。
旨在降低ETL开发成本、提高大数据平台稳定性,大数据开发人员可以在 Taier 直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
项目地址:https://github.com/DTStack/Taier
![file]()
Taier 资源判断
Taier 基于插件式架构设计,用户在界面开发任务并提交运行。提交运行插件又划分为worker-plugins、datasource-plugins双插件类型。
在任务提交的时候,Taier需要判断是否有足够的资源来执行,否则一股脑地提交任务,最终会拖垮环境,导致服务的不可用。根据环境资源的剩余情况来动态调整提交任务的速率是Taier必不可少的一项功能,那么Taier究竟是怎么来判断资源的呢?
什么是资源?
对一个系统而言,首先要定义出资源的种类,然后将每种资源量化,才能进行管理,这就是资源抽象的过程。那么,想回答上文中「Taier是如何判断资源」的这个问题,就需要先理清楚,在一个分布式、多环境的系统中,什么是资源,又为什么要有“资源”这个概念?
我们通常所说的“资源”都是硬件资源,包括CPU使用/内存使用/磁盘用量/IO/网络流量等等,这是比较粗粒度的。也可以是抽象层次更高的TPS/请求数之类的。
资源可以用来衡量系统的瓶颈。系统能否充分利用资源,什么时候可以持续提交任务,什么时候需要暂停提交任务,比如当总体资源充裕时,可以把对应的任务全部提交上去。
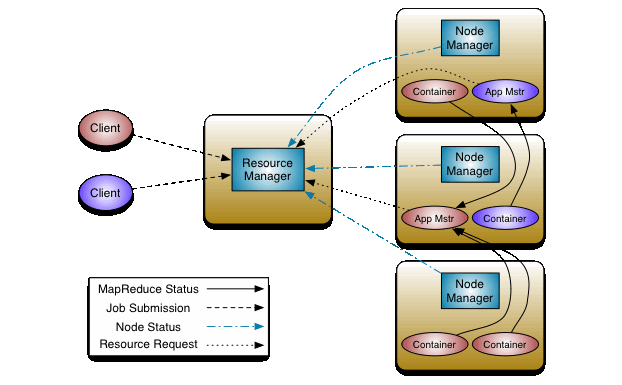
● 以Yarn框架介绍为例
![file]()
ResourceManager 是一个全局的资源管理器,负责整个系统的资源管理和分配,包括 scheduler 、Application Manager和 Node Manager。
对调度器来说,YARN 提供了多种直接可用的调度器, Fair Scheduler 和 Capacity Scheduler 等。调度器仅根据各个应用程序的资源需求进行资源分配,分配的基本单位是Container,而容器里面是将内存、CPU、网络、磁盘封装到一起。
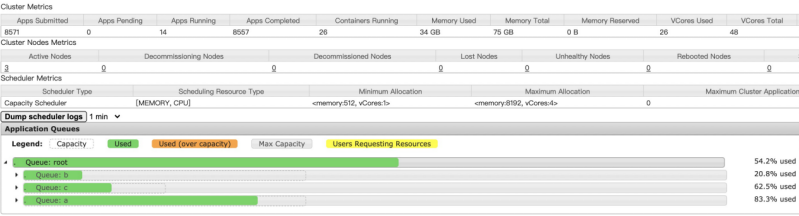
在Yarn的web 界面,我们可以直观的看到当前Yarn集群剩余的内存、CPU核数、运行的Container数量。对提交到yarn上的任务来说,资源就是:内存、CPU、磁盘等可用信息。
![file]()
所以在提交到Yarn上执行的任务,我们可以根据ResourceManager 获取Yarn集群当前剩余的内存、CPU核数来进行判断,任务能否满足提交条件等规则。其中,最基本的规则就是:
• Yarn集群剩余的内存 >= 当前任务所需的内存
• Yarn集群剩余的CPU核数 >= 当前任务所需的CPU核数
何时去判断资源?
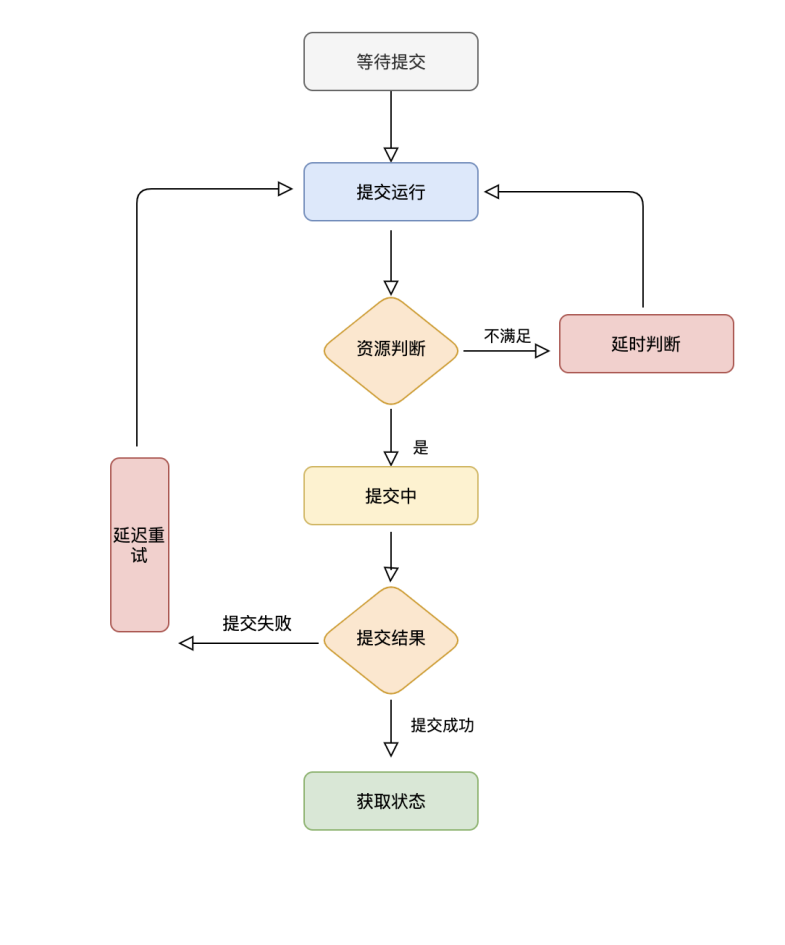
任务在界面开发完成之后,点击运行的按钮,开始从等待提交的状态切换。在提交运行的时候,任务组装好集群配置信息进入下一个阶段——资源判断。
在这个阶段开始判断资源是否满足任务提交。如果任务满足则进行提交,如果任务不满足,则定时、延时、重试直到资源满足任务执行条件。
![file]()
怎样去判断资源?
在worker-plugins提交的抽象类中,有一个通用的方法judgeSlots 去判断资源。
judgeSlots 的判断结果分为以下四种:
• OK: 资源判断满足,任务可以提交
• NOT_OK: 不满足任务所需资源,需要延时重试
• LIMIT_ERROR: 任务参数设置错误: CPU核数或内存为0等场景
• EXCEPTION: 任务资源判断异常: ResourceManager连接异常等场景
![file]()
● 以Spark任务为例
下文我们以Spark任务为例,看看Spark的提交插件是如何获取对应的ResourceManager信息并进行资源判断的。
![file]()
可以看到根据Yarn集群信息获取了以下信息:
• 根据Yarn集群信息初始化YarnClient
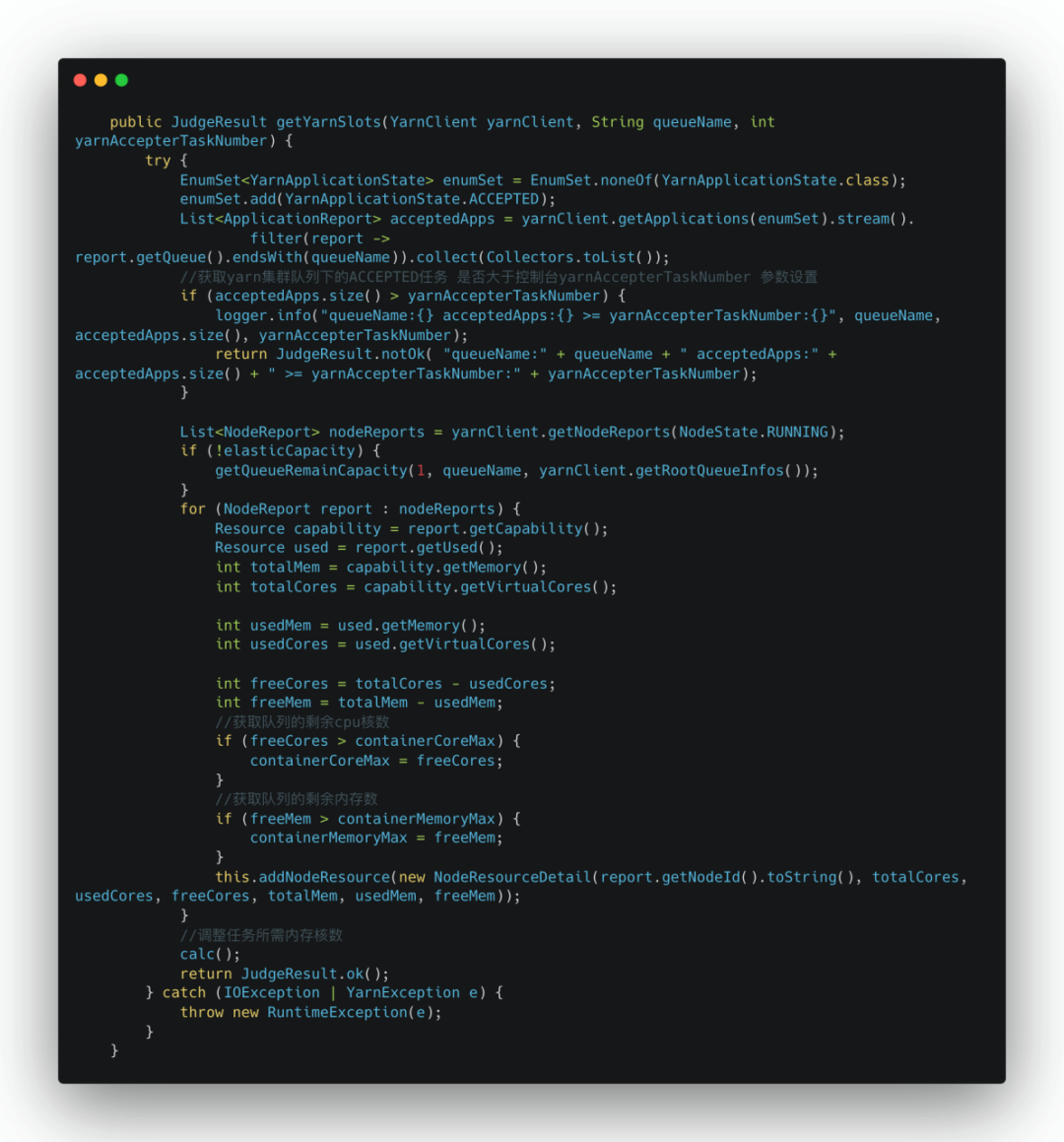
• 获取Yarn集群队列下的ACCEPTED状态任务,是否大于控制台yarnAccepterTaskNumber 参数设置
• 获取Yarn集群队列的剩余CPU核数和内存信息
![file]()
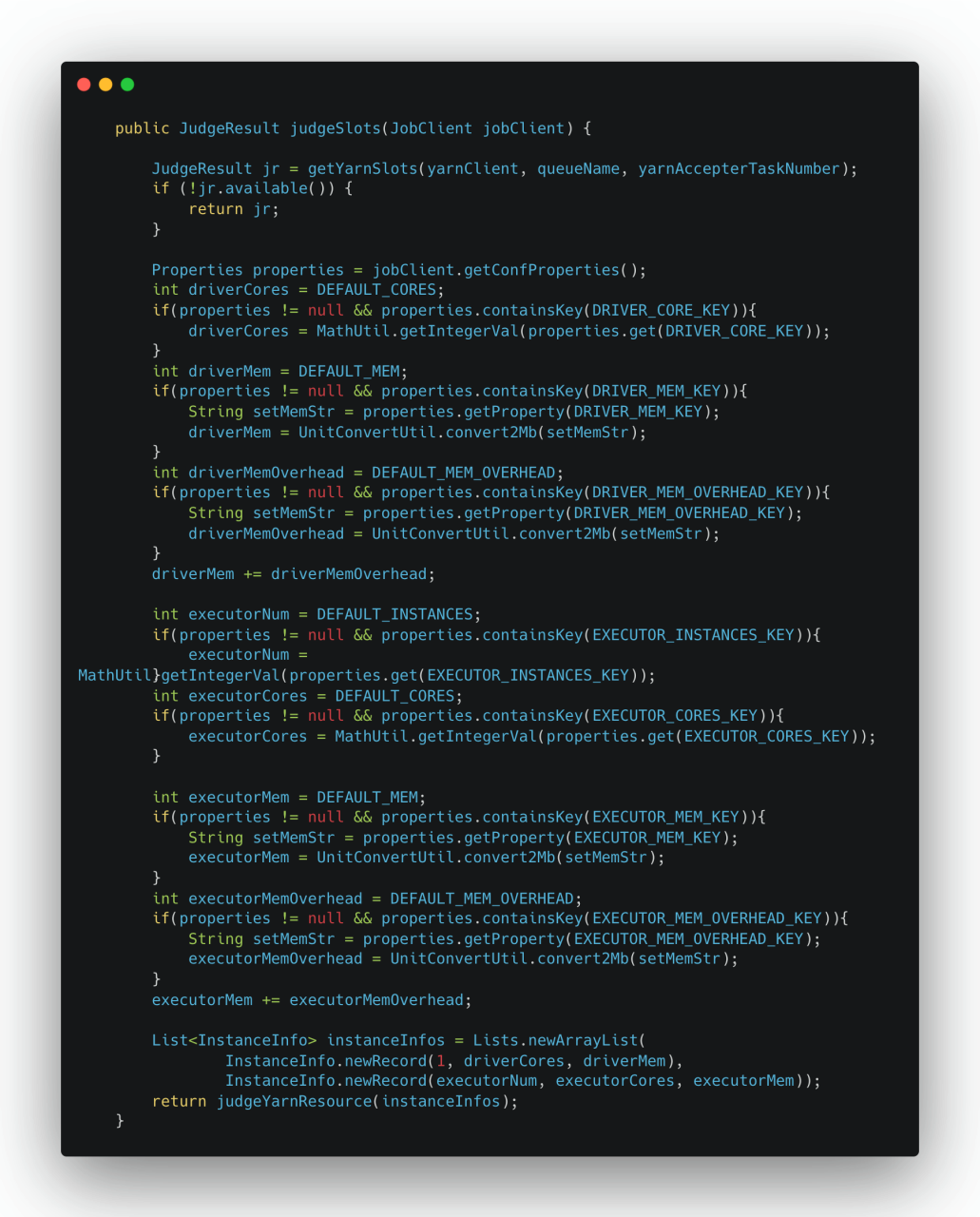
然后根据JobClient所携带的任务参数信息,获取了Driver、Executor 的相关内存和CPU信息并进行计算。
![file]()
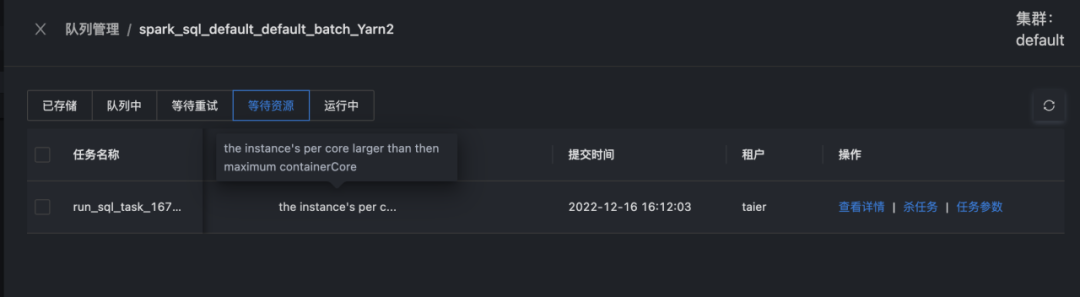
最后将获取到的Yarn集群信息和任务所需的资源信息按照固定规则进行比对,返回对应的资源判断结果。资源判断的结果将会实时在 Taier 的界面上展示,所以在任务处于等待提交状态的时候,可以去控制台->队列,管理并查看该任务资源判断信息。
![file]()
Taier 未来规划
展望未来,为进一步提升Taier的使用场景,同时也为了减少Hadoop生态在Taier中的依赖,Taier后续会扩展更多的任务类型。除了支持对接Hadoop集群外,Taier也会陆续支持相关类型的local模式运行,完善更多的场景使用。
Taier团队非常期待得到每一个人的反馈,能够和其他优秀开发者共同合作,进一步推动Taier的技术发展。
如果您对Taier有兴趣,希望可以参与到我们的建设中来,一起交流,一起进步,为 Taier变得更好贡献一点你的代码和意见,这将是我们,同时也是 Taier莫大的荣幸。
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szkyzg
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack