在 2022 年最后一个工作日迎来了 Zadig v1.16.0 开发者福利版。该版本主要针对开发者体验做了深度优化,并提供大量日常开发协作过程中实用的小功能,帮助开发者提高生产效率。
支持 i18n,开源无界,开放更易用
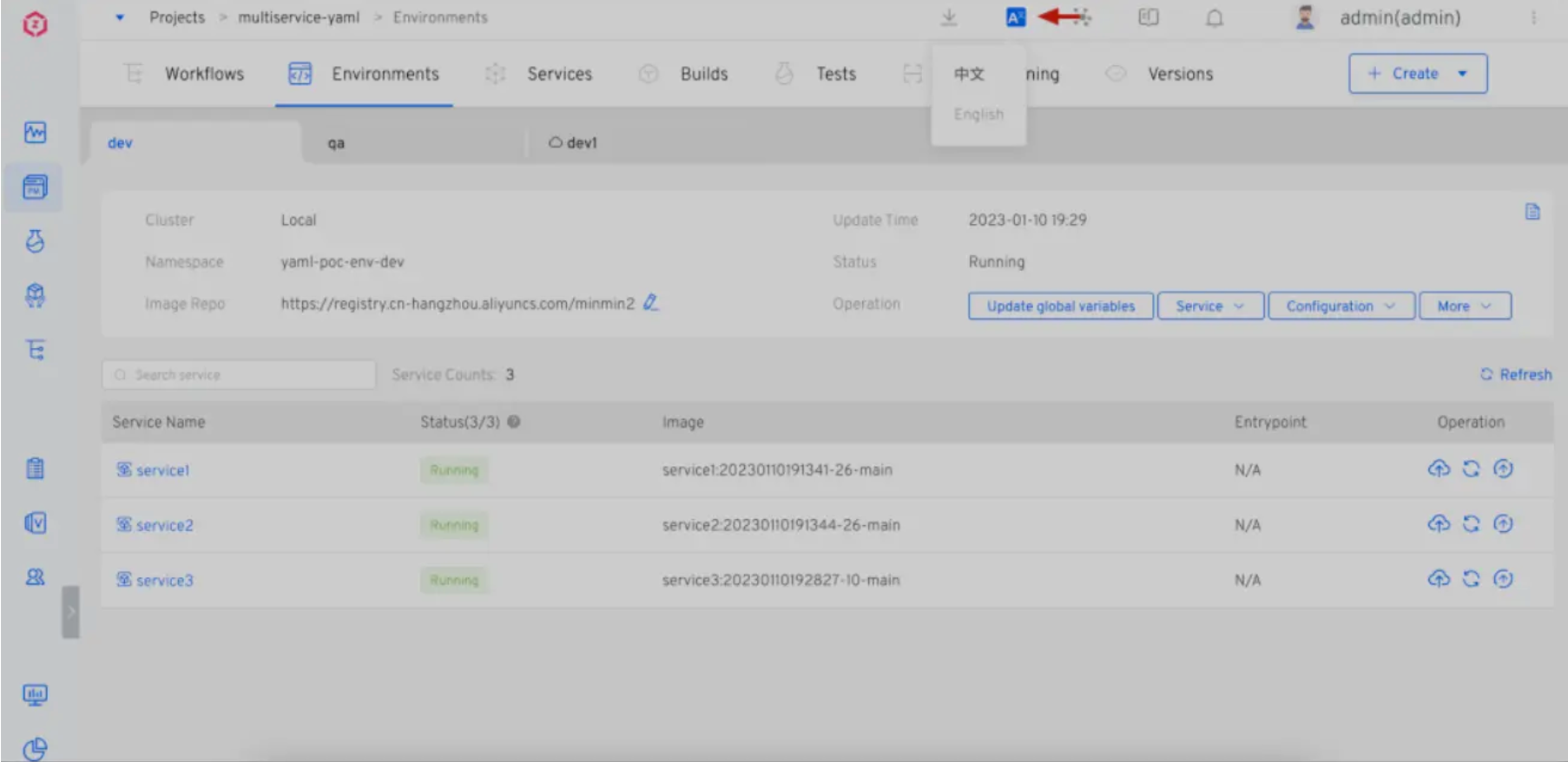
越来越多海内外用户接触 Zadig,为了满足跨国跨境企业的研发协作需求,Zadig 支持了 i18n,支持一键切换成常用界面语言,目前提供中文和英文选择。
![]()
工作流多个 PR/MR 合并构建
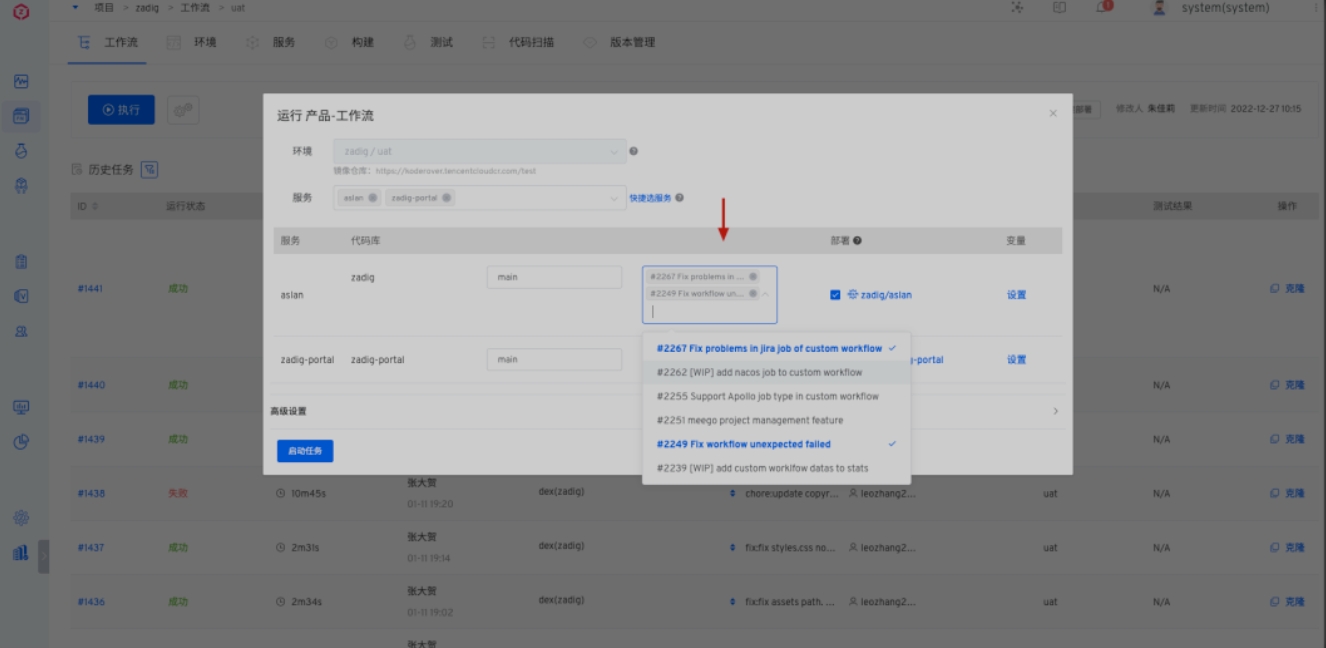
日常研发过程中,两个开发者在同一个服务上开发两个独立功能的情况,这时候开发环境不够用怎么办?只能等其中一个人自测完后才能再占用环境进行自测,大大影响研发的进度。当两个功能同时提测,如何快速做集成验证?Zadig 多 PR 合并构建的能力可以很方便高效地解决这个问题,帮助开发者减少不必要的等待时间,提高交付效率。
![]()
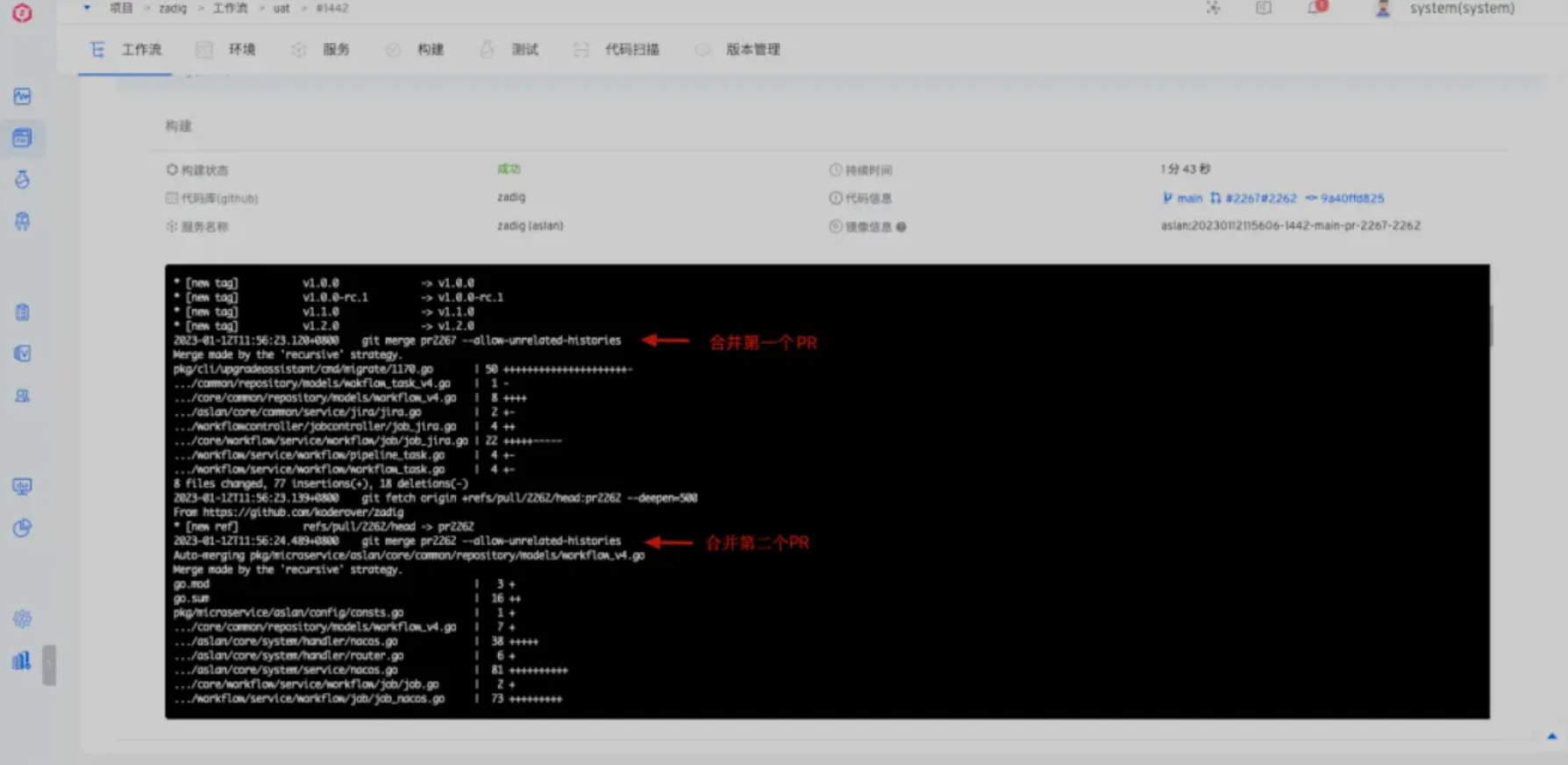
执行产品工作流、自定义工作流构建、测试、代码扫描等任务均支持选择多个 PR/MR 合并构建,任务执行过程会将多个 PR/MR 在容器中预合并到目标分支上,然后再执行后续的脚本。
![]()
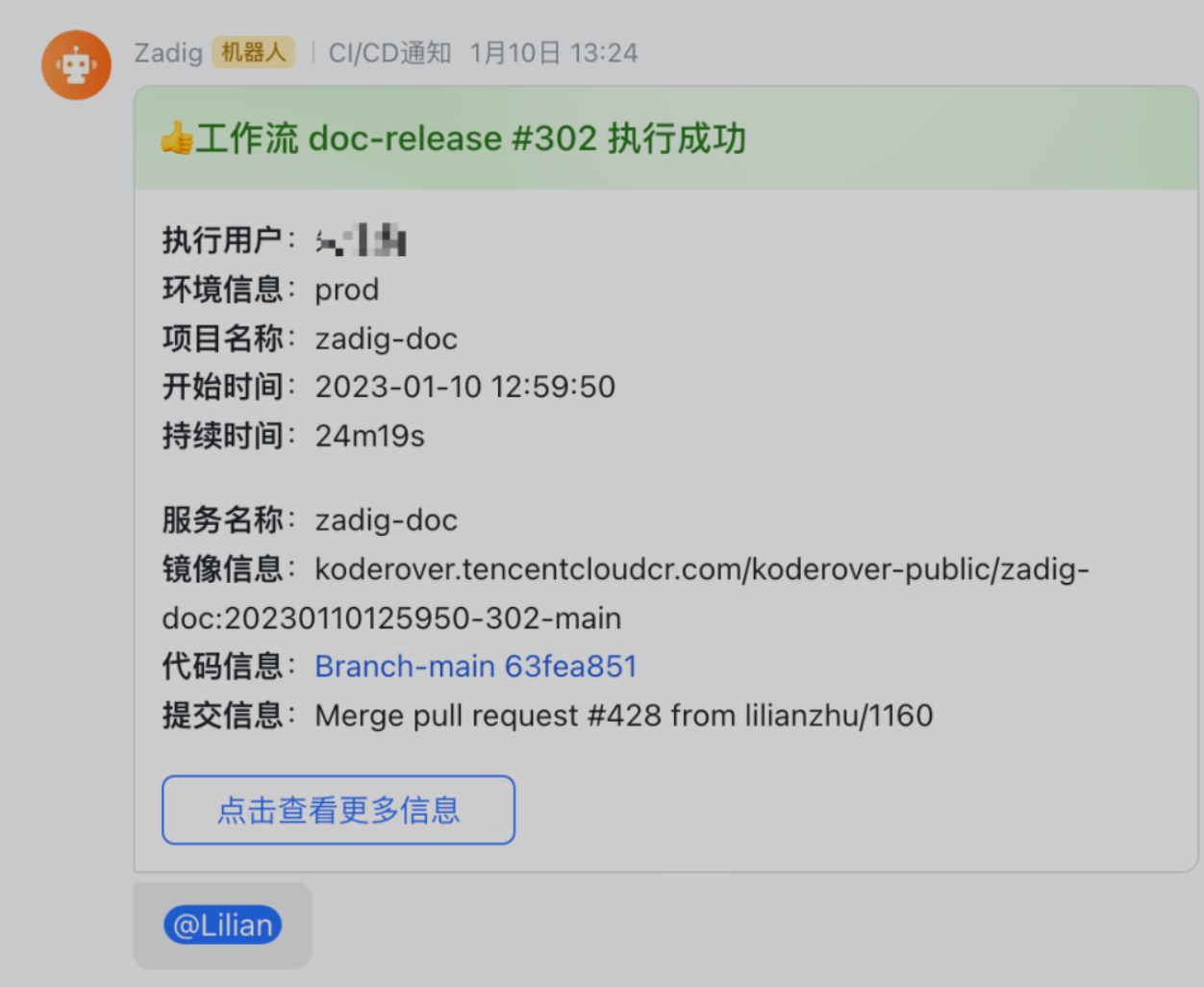
工作流 IM 通知支持指定成员
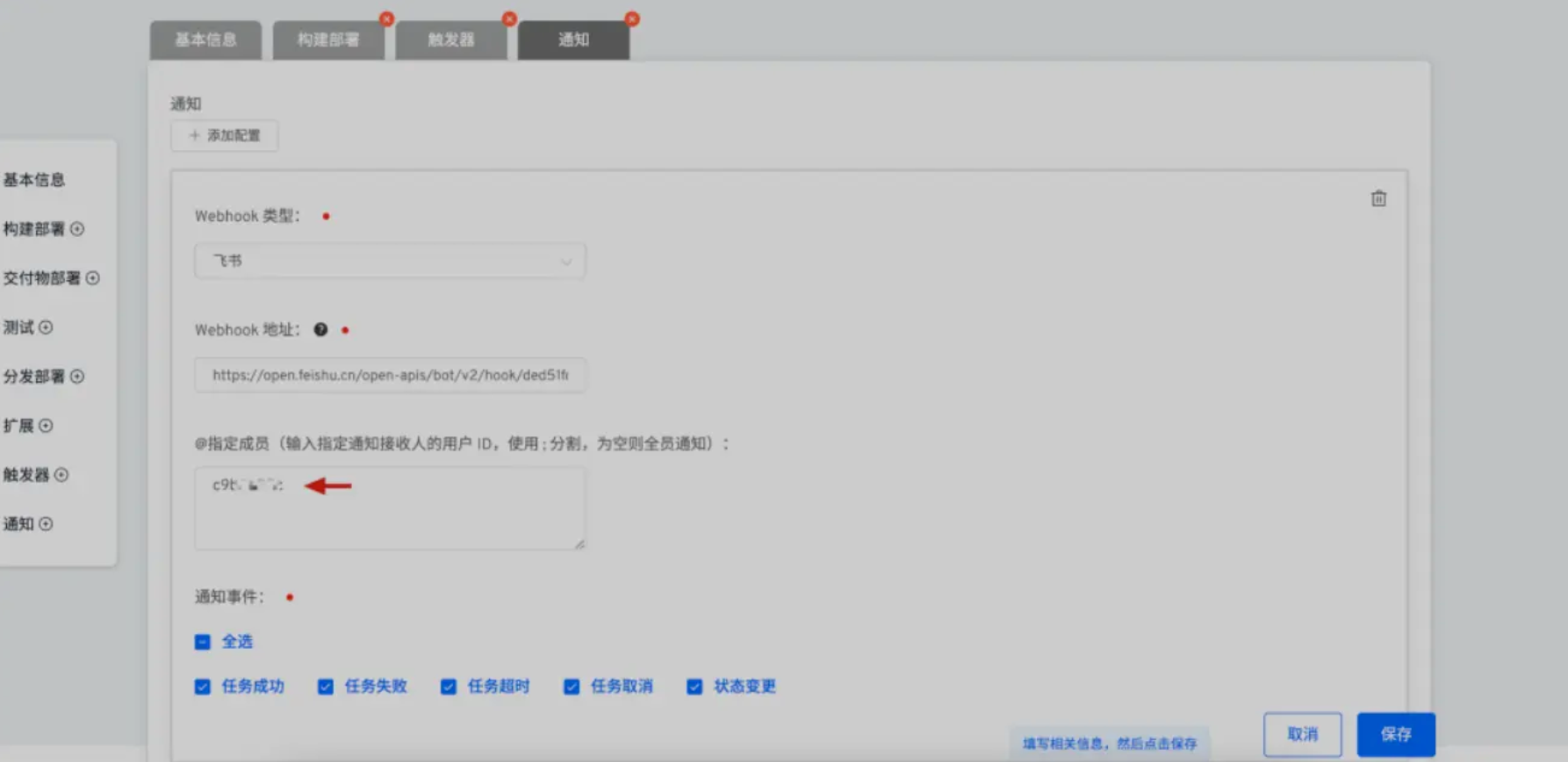
Zadig 之前的版本支持 IM 通知到群,可能会造成消息的干扰,因为不是所有人都需要关注工作流任务的执行状况,为了可以精准的通知,v1.16.0 支持 IM 通知到指定成员。
以飞书为例,通过配置工作流通知-指定成员,输入用户的 ID。
![]()
执行工作流后,可以飞书上收到对应工作流任务通知,效果如下:
![]()
开发者仪表盘
Zadig 开发者仪表盘旨在提供用户一个平面,让用户聚焦在个人关注的事情上,也可以作为日常工作的一个快捷入口,简化操作。提供了三张卡片:
运行中的工作流:显示系统中运行中的工作流列表。通过这张卡片,用户可以了解自己关注的工作流任务在什么阶段,可以有一个心理预期。
我的工作流:显示个人关注的工作流相关信息。可以自定义个人日常使用频繁的工作流。通过这张卡片,查看工作流的当前的状态,并且可以一键执行任务。
我的环境:显示个人关注的环境及服务信息。可以自定义个人日常负责的环境和服务。通过这张卡片,可以获得环境最近一次更新信息、当前服务运行状态以及镜像版本信息。
![]()
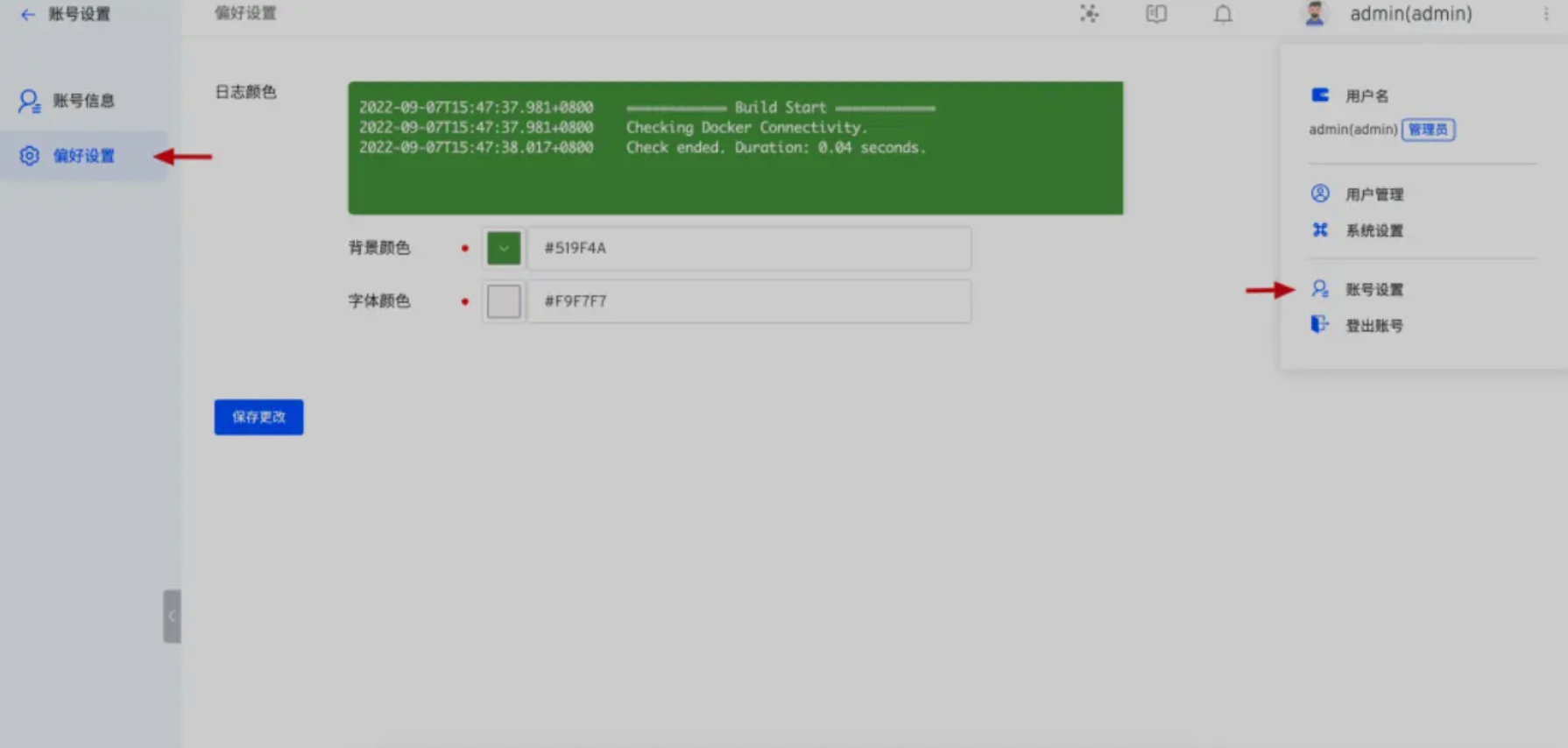
工作流/服务日志支持自定义颜色
Zadig 工作流任务详情中的日志、环境中服务日志、调试的背景颜色和字体颜色可以根据自己的喜好自定义,避免长时间使用 Zadig 产生视觉疲劳。
![]()
![]()
说到这里是不是有点心动了呢?赶紧下载安装用起来吧~
Zadig v1.16.0 完整的功能列表和升级过程详情见
https://docs.koderover.com/zadig/v1.16.0/release-notes/v1.16.0
Zadig,让工程师更加专注创造。
说到这里是不是有点心动了呢?赶紧下载安装用起来吧~
Zadig v1.16.0 完整
说到这里是不是有点心动了呢?赶紧下载安装用起来吧~
Zadig v1.16.0 完整的功能列表和升级过程详情见 https://docs.koderover.com/zadig/v1.16.0/release-notes/v1.16.0
的功能列表和升级过程详情见 https://docs.koderover.com/zadig/v1.16.0/release-notes/v1.16.0
说到这里是不是有点心动了呢?赶紧下载安装用起来吧~
Zadig v1.16.0 完整的功能列表和升级过程详情见 https://docs.koderover.com/zadig/v1.16.0/release-notes/v1.16.0
日常研发过程中,两个开发者在同一个服务上开发两个独立功能的情况,这时候开发环境不够用怎么办?只能等其中一个人自测完后才能再占用环境进行自测,大大影响研发的进度。当两个功能同时提测,如何快速做集成验证?Zadig 多 PR 合并构建的能力可以很方便高效地解决这个问题,帮助开发者减少不必要的等待时间,提高交付效率。
越来越多海内外用户接触 Zadig,为了满足跨国跨境企业的研发协作需求,Zadig 支持了 i18n,支持一键切换成常用界面语言,目前提供中文和英文选择。