![]()
Alluxio线程池结构与吞吐量调优
导语
Alluxio 是一个开源的数据编排系统,致力于解决解决大数据分析及 AI 场景下的一些痛点问题,它可以加速数据查询和AI模型训练的速度,提升系统在高并发场景下的高可用能力。这些应用场景决定了 Alluxio 需要具备大吞吐量特性,本文首先介绍 Alluxio Master 的线程池结构,基于线程池分析结果提出 Alluxio 吞吐量调优方案。
业务背景
本次线程池结构分析与调优的对象是 Alluxio 的开源版本,且 Alluxio 的配置项均为默认配置项,分析的场景是游戏 AI 的特征计算阶段。特征计算需要大量读取用户数据分析用户操作,然后针对计算结果进行游戏环境的还原。特征计算任务初期会有数千至上万的进程同时对底层分布式存储节点发起访问,产生流量洪峰。在这种读密集场景下,Alluxio 的高吞吐可以有效缓解存储端压力。
Alluxio 默认线程池结构与 JVM 参数
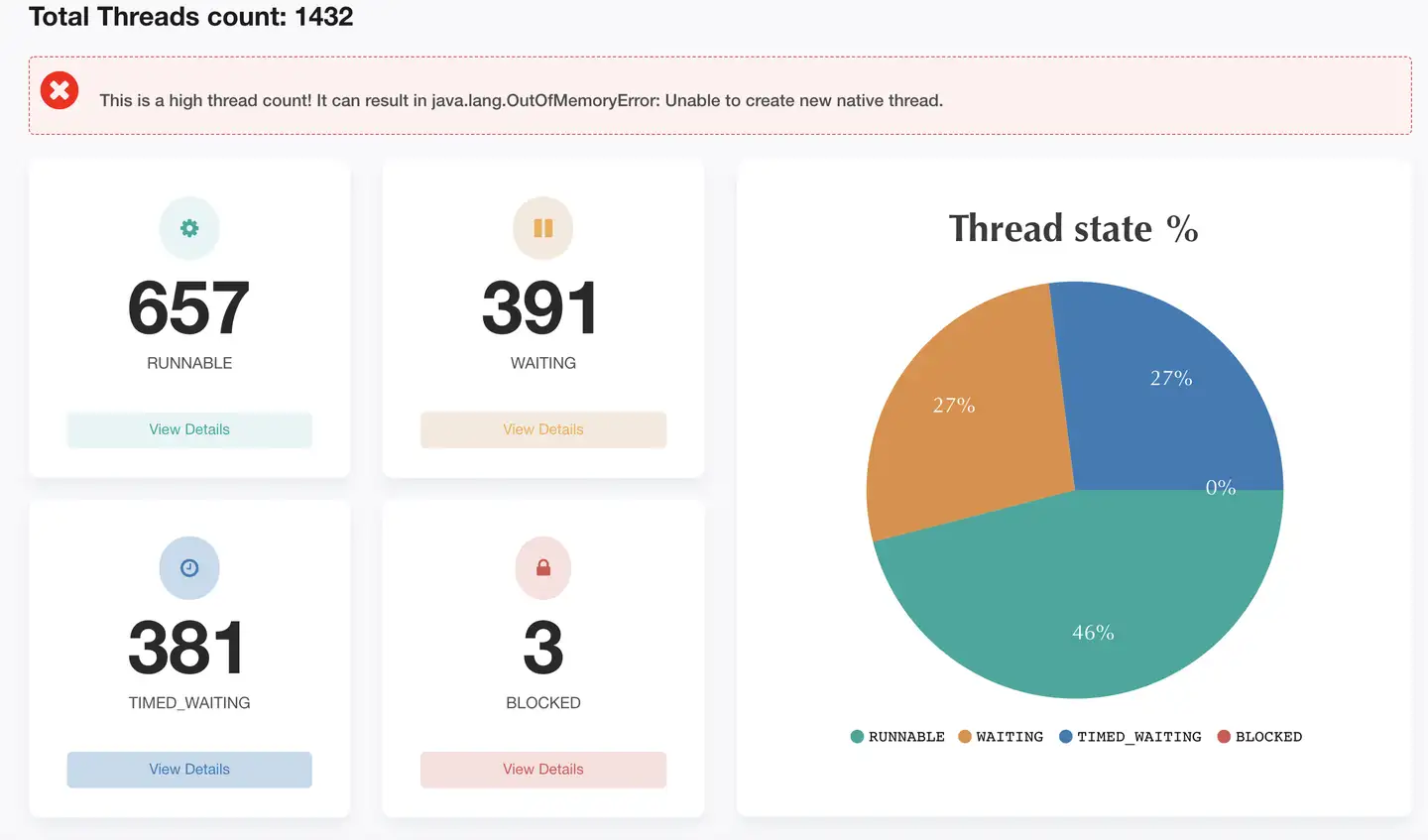
在业务运行过程中,通过 jstack 生成系统线程信息,导入FastThread分析。分析结果如下:
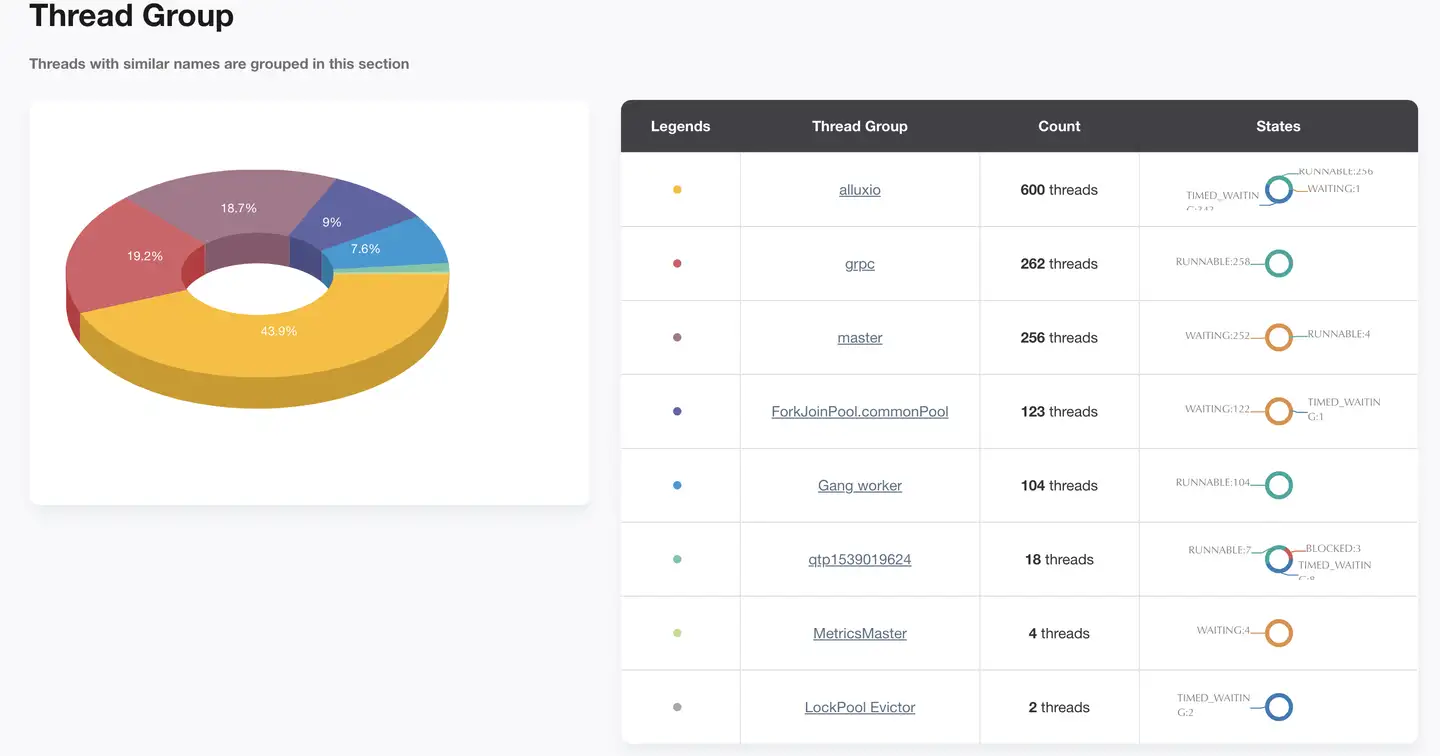
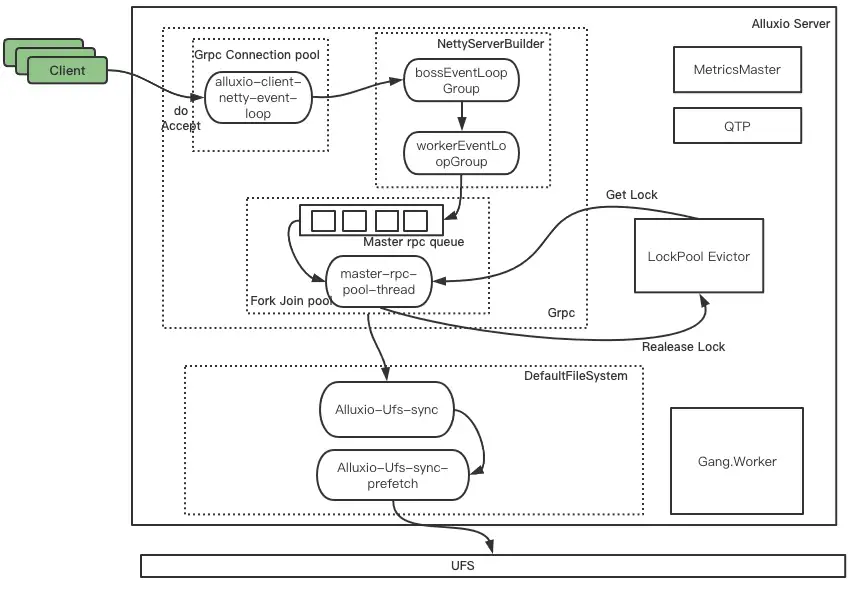
Alluxio Master 节点有 1432 个线程,其中 RUNABLE 状态的线程数仅占46%,有大量线程处于 WATING 和 TIME_WAITING 状态,Master 节点线程数较多,容易发生 OOM,需要根据线程池工作与线程间的调用关系,适当调整线程数量。 Alluxio Master 上有八个线程组,分别为:Alluxio、master、grpc、ForkJoinPool.commonPool、Gang.worker、qtpXXX、MetricsMaster、LockPool Evictor。它们之间的工作与线程调用关系如下图所示。接下来将结合线程模型和 Alluxio 源码分析这些线程组的作用及调优方向。
Alluxio 线程组
Alluxio 线程组共600个线程,它们的状态如下:
| Name |
Status |
Count |
| Alluxio-client-netty-event-loop-RPC-* |
Runnable |
256 |
| alluxio-ufs-sync-prefetch-* |
Time_Wating |
211 |
| alluxio-ufs-sync-* |
Time_Wating |
128 |
| alluxio-master-* |
Time_Wating |
4 |
| alluxio-master-*-StateMachineUpdater |
Wating |
1 |
由上表可知,Alluxio 线程组中共有5种线程,其中,负责client的线程均处于 RUNNABLE 状态,其余线程处于 TIME_WATING 和 WATING 状态,下面将介绍每个线程的功能。
- Alluxio-client-netty-event-loop-RPC
这是 Netty 框架的线程池,属于 NioEventLoopGroup 类型。在这次采样数据中,该线程池256个线程均处于 RUNNABLE 状态,该线程用于 client 端与 server 端建立连接时使用,可以通过下列配置项进行配置,它的默认值为0。
alluxio.user.network.netty.worker.threads
该线程池主要用于并发地执行元数据同步操作,它是 ThreadPoolExecutor 类型。具体的元数据同步操作由 Alluxio-ufs-sync-prefetch 线程组完成。在本次采样中,线程全部处于 TIME_WATING 状态。该线程池的核心线程数与最大线程数相等,它的默认值为系统当前的核心数,可以通过下列配置项修改。
alluxio.master.metadata.sync.executor.pool.size
- Alluxio-ufs-sync-prefetch
该线程池主要在一个元数据同步操作内,并发地从 UFS 中获取元数据。在本次采样中,线程全部处于 TIME_WAITING 状态。该线程池的核心线程数与最大线程数相等,默认值为系统当前的线程数的 10 倍,可以通过下列配置项修改。
alluxio.master.metadata.sync.ufs.prefetch.pool.size
这个线程组有5个线程:
| Name |
Status |
| Alluxio-master-1_19200-*-alluxio-master-2_19200-GrpcLogAppender-LogAppenderDaemon |
TIME_WAITING |
| Alluxio-master-1_19200-*-alluxio-master-0_19200-GrpcLogAppender-LogAppenderDaemon |
TIME_WAITING |
| Alluxio-master-1_19200-*-LeaderStateImpl |
TIME_WAITING |
| Alluxio-master-1_19200-*-SegmentedRaftLogWorker |
TIME_WAITING |
| Alluxio-master-1_19200-*-StateMachineUpdater |
WAITING |
本次提取的堆栈信息是从 Alluxio-master-1 节点中取出的,它是 Leader 节点。这五个线程用于支持 Alluxio-master 的具体工作:上表的前两个线程是 master-1 与两个 raft follower 节点进行通信的守护线程,用于 raft 集群中追加日志时进行通信。第三个线程为 Leader 节点特有的,主要用于 Leader 选举的相关操作。第四个线程为 RaftLog 相关的线程,这个线程会处理与 Raft log 相关的 I/O OPS 相关的操作。第五个线程与 StateMachine 相关,它是 Ratis 用于状态机更新的线程。
master 线程组
Master 线程组共256个线程,均处于 WATING 状态。它们组成了一个 ForkJoinPool 类型的线程池,ForkJoinPool 是ExecutorService 的补充,它采用分而治之的思想,比较适合计算密集型任务。Alluxio 用该线程池处理 RPC 请求,它从 RPC Queue 不断取出积压的任务,然后进行处理,这个线程池的创建源码为:
ExecutorServiceBuilder#executorService = new ForkJoinPool(parallelism,
ThreadFactoryUtils.buildFjp(threadNameFormat, true), null, isAsync, corePoolSize,
maxPoolSize, minRunnable, null, keepAliveMs, TimeUnit.MILLISECONDS);
GRPC 线程组
GRPC 线程组由4种线程构成,在本次采样中共262个线程。这四种线程属于 GRPC 框架,它们为 Alluxio 提供 RPC 通信服务。
| Name |
Status |
Count |
| grpc-default-worker-* |
RUNNABLE |
256 |
| grpc-default-boss-* |
RUNNABLE |
2 |
| grpc-default-executor-* |
TIME_WAITING |
3 |
| grpc-shared-destroyer |
WAITING |
1 |
MetricsMaster 线程组
该线程组共4个线程,它们是一个 FixedThreadPool 类型的线程池,即该线程池的核心线程数与最大线程数相等。该线程池主要用于并行获取从 worker 或者 client 提交的 Metric 数据,并根据数据更新集群的指标信息,这些信息可以通过 Grafana 与Prometheus 相结合地方式直观地检查系统状态。该线程池的核心线程数是可配置的,通过下列配置项完成。
alluxio.master.metrics.service.threads=5(默认值)
LockPool Evictor 线程组
LocakPool Evictor 线程组由2个 SingleThreadExecutor 类型的线程池组成,它们作为锁池使用。该线程池的源码如下:
private final LockPool<Long> mInodeLocks =
new LockPool<>((key) -> new ReentrantReadWriteLock(),
ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_INITSIZE),
ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_LOW_WATERMARK),
ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_HIGH_WATERMARK),
ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_CONCURRENCY_LEVEL));
private final LockPool<Edge> mEdgeLocks =
new LockPool<>((key) -> new ReentrantReadWriteLock(),
ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_INITSIZE),
ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_LOW_WATERMARK),
ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_HIGH_WATERMARK),
ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_CONCURRENCY_LEVEL));
其中,mInodeLocks 用于提供 inode 锁:要锁定一个 inode,必须在该池中得它的id然后获取它的读锁;mEdgeLocks 用于提供边锁,这里的边指的是 inode 树中的一条边,边从父 inode id 指向子 inode id。
这两种锁池中的锁均为可重入的读写锁,锁池的初始数量、最小锁数量、最大锁数量、并发度均可以配置。
| 配置项 |
含义 |
默认值 |
| alluxio.master.lock.pool.initsize |
初始值 |
1000 |
| alluxio.master.lock.pool.low.watermark |
锁池低水位 |
500000 |
| alluxio.master.lock.pool.high.watermark |
锁池高水位 |
1000000 |
| alluxio.master.lock.pool.concurrency.level |
并发度 |
100 |
qtpXXX 线程组
该线程组用于提供 Jetty 服务,Jetty 是一个开源的 Servlet 容器,对外提供 web 服务。它们属于 QueueThreadPool 类型的线程池。在本次采样结果中共14个线程,这个线程池的最大线程数为254个,最小线程数为8。
Gang.worker 线程组
Gang worker 线程组用于 JVM 的垃圾回收。该线程组的线程数可以通过修改 JVM 参数进行 -XX:ParallelGCThreads 进行修改。
调优原理与结果
审计日志
在吞吐量测试过程中,我们在编译器研发团队的帮助下,通过 Kona Profile 采样,并对采样结果进行分析,发现 Alluxio 在运行过程中,生成审计日志时存在明显的锁竞争,blocking queue 的 size 成为了瓶颈点。
基于这种现象,我们选择在非生产环境下关闭审计日志,在生产环境下调高审计日志的 blocking queue size 的方式调优性能。在调整后发现,系统吞吐量明显提升。
调整 UFS-SYNC-PREFETCH 线程池
在 Alluxio Master 运行业务时,大量的任务积压在 master rpc queue 中,ForkJoinPool 线程池的处理速度受限于物理机的资源成为了瓶颈点。Alluxio-UFS-SYNC-PREFETCH 线程池用于执行元数据的同步工作,这个线程数默认为系统 CPU 核数的10倍,在实际系统中并不需要这么多的线程数,因此这种配置存在线程浪费情况。因此,我们将该线程数调整为2倍的 CPU 核数,调整后发现没有出现性能下降的情况。
JVM GC 线程数调优
Alluxio 在腾讯自研的 KonaJDK 11 上作测试,使用 JDK 默认参数会出现集群 Full GC 时间过长的情况,Master 停顿时间过长会导致 Leader 切换,这种切换的成本很高。通过分析 GC 日志,我们发现默认的 GC 并行线程数较小,仅为30。考虑到我们使用的为64服务器,我们将 GC 并行线程数调整为40,发现 GC 停顿时间明显降低,系统的稳定性增强。
后续调优方向展望
Alluxio 作为存储引擎和计算框架之间的中间件,承载着数据缓存、访问加速、缓解存储压力等任务,这些功能都对 Alluxio 系统的吞吐量提出了较高的要求。在接下来工作中,我们将继续改进方案,不断提升系统吞吐量性能。为此,我们设计了几种方案。
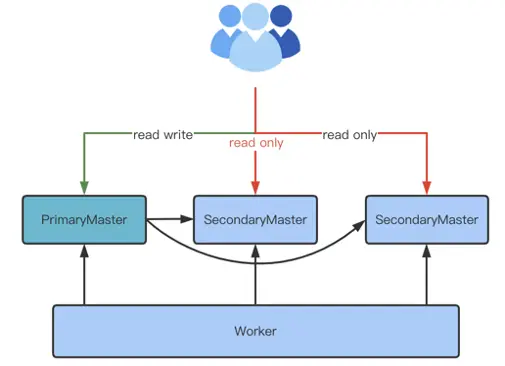
将 Follower Master 开启读服务
现阶段,Alluxio 仅有 Leader Master 接受 Client 端的读写请求,这限制了 Alluxio 吞吐量的提升。这会产生单点瓶颈效应,我们计划在后续将 Follower Master 接受 Client 端的读请求,这样会有效提升系统吞吐量。
这种架构的优势在于可以充分利用现有的节点,不需要有非常大的代码改动,但缺点为系统提升仍会有瓶颈,不具备无限扩展能力。
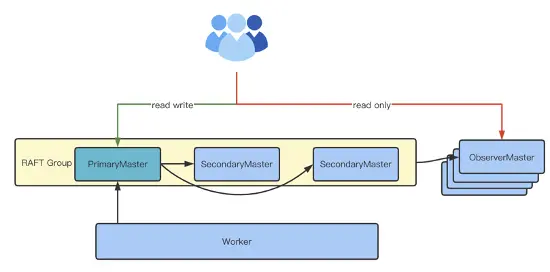
开发 Observer Master
为了使集群在理论上拥有无限扩展能力,可以借鉴 Zookeeper 的 Observer Node 思想,开发 Oberserver Master 节点,系统模型如下:
这种模型可以添加多个 Observer Master 节点,它们的元数据同步可以主动 tail raft group 中的 log,并回放到本地状态机上,worker 的 block 信息可以周期性地进行同步。这种架构的优势为理论上可以无限扩展,但劣势是需要额外的节点资源。且这种方案代码改动较多、开发难度大,block 位置信息的同步开销也比较大。
总结
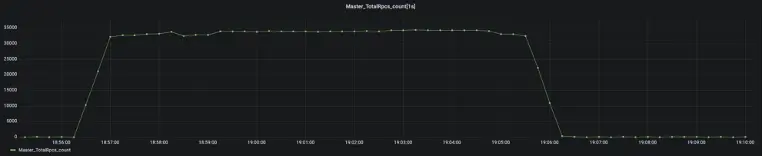
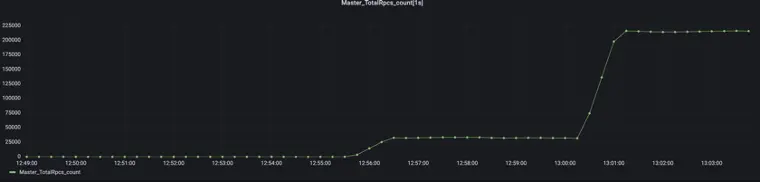
本次初衷是基于线程池结构对 Alluxio 吞吐量性能进行调优,根据本次测试采样结果分析了性能瓶颈点,调优相关瓶颈点后得到性能提升。
基于 Alluxio Master 的源码,本文介绍了 Alluxio Master 的线程池结构与每个线程的功能。在调优过程中,利用分析结果调整审计日志的 blocking queue,调整 UFS-SYNC-PREFETCH 线程数,调优 JVM 参数。通过实验证明,Alluxio 吞吐量提升7倍。
最后,本文提出了 Alluxio 吞吐量提升的未来优化方向。
想要获取更多有趣有料的【活动信息】【技术文章】【大咖观点】,请关注[Alluxio智库]:
![]()