- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
- GreatSQL是MySQL的国产分支版本,使用上与MySQL一致。
-
- 什么是MVCC
- 三个隐藏字段
- Undo Log回滚日志
- MVCC版本链
- ReadView读视图
- 不同隔离级别下MVCC分析
- READ-COMMITTED隔离级别
- REPEATABLE-READ隔离级别
前情提要
事务有四大特性ACID分别是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
其中隔离性是通过数据库的锁加上MVCC(多版本并发控制)来保证的。
在介绍MVCC之前先来了解一下当前读和快照读。
当前读
当前读读取的是记录的最新版本。同时在读取的时候还要保证其他的并发事务不能更改当前记录,那么当前读会对它要读取的记录进行加锁。不同的操作会加上不同类型的锁,如:SELECT ... LOCK IN SHARE MODE(共享锁),SELECT ... FOR UPDATE、UPDATE、INSERT、 DELETE(排他锁)。
快照读
简单的不加锁的SELECT就是快照读,快照读读取的是快照生成时的数据,不一定是最新的数据,它是不加锁的非阻塞读。而不同隔离级别下,创建快照的时机也不同:
READ-COMMITTED(读已提交):事务每次SELECT时创建ReadViewREPEATABLE-READ(可重复读):事务第一次SELECT时创建ReadView,后续一直使用
在MySQL默认隔离级别(REPEATABLE-READ)下,快照读保证了数据的可重复读。
什么是MVCC
MVCC全称Multi-Version Concurrency Control,即多版本并发控制。它是一种并发控制的方法,它可以维护一个数据的多个版本,用更好的方式去处理读写冲突,做到即使有读写冲突也能不加锁。MySQL中MVCC的具体实现,还需要依赖于表中的三个隐藏字段、Undo Log日志以及ReadView。
三个隐藏字段
mysql> SHOW CREATE TABLE stu \G;
*************************** 1. row ***************************
Table: stu
Create Table: CREATE TABLE `stu` (
`id` int NOT NULL,
`name` varchar(10) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> SELECT * FROM stu;
+----+--------+
| id | name |
+----+--------+
| 1 | m |
| 2 | f |
+----+--------+
当创建了上述这张表后,我们在查看表结构时只能看到id、name字段,实际上除了这两个字段外,InnoDB引擎还自动为我们添加了三个隐藏字段,见下表:
| 字段 |
含义 |
| DB_TRX_ID |
最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID。 |
| DB_ROLL_PTR |
回滚指针,指向这条记录的上一个版本,用于配合Undo Log,指向上一个版本。 |
| DB_ROW_ID |
隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段。 |
我们可以使用ibd2sdi工具来从表空间文件中提取序列化的字典信息(SDI),来验证一下这三个隐藏字段是否存在。
["ibd2sdi"
,
{
"type": 1,
"id": 402,
"object":
{
"mysqld_version_id": 80025,
"dd_version": 80023,
"sdi_version": 80019,
"dd_object_type": "Table",
"dd_object": {
"name": "stu",
"mysql_version_id": 80025,
"created": 20220919023413,
"last_altered": 20220919023413,
"hidden": 1,
"options": "avg_row_length=0;encrypt_type=N;explicit_encryption=0;key_block_size=0;keys_disabled=0;pack_record=1;stats_auto_recalc=0;stats_sample_pages=0;",
"columns": [
{
"name": "id",
"type": 4,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 1,
···省略
},
{
"name": "name",
"type": 16,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 1,
···省略
},
{
"name": "DB_TRX_ID", #最近修改事务ID
"type": 10,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 2,
···省略
},
{
"name": "DB_ROLL_PTR", #回滚指针
"type": 9,
"is_nullable": false,
"is_zerofill": false,
"is_unsigned": false,
"is_auto_increment": false,
"is_virtual": false,
"hidden": 2,
···省略
}
],
注意:因为这张表里已经指定了主键为id列,所以不会生成隐藏主键DB_ROW_ID列。
Undo Log回滚日志
回滚日志,在增、改、删操作的时候产生的便于数据回滚的日志。当INSERT操作的时候,产生的回滚日志在事务提交后可被立即删除。而UPDATE和DELETE操作的时候,产生的Undo Log日志不仅在进行数据回滚时需要,在进行快照读时也需要,所以不会立即被删除。
Undo Log详情可见文章:待浩源Undo Log文章发表后添加
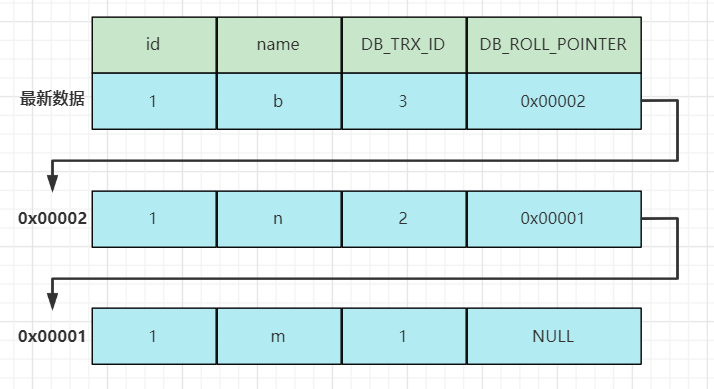
MVCC版本链
当有多个并发事务操作一行数据时,对这行数据的修改会产生多个版本,多个版本通过上述的一个隐藏字段DB_ROLL_PTR回滚指针指向Undo Log数据地址形成一个链表,即MVCC版本链。
![]()
ReadView读视图
ReadView读视图是快照读SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)id。
上面讲过Undo Log和MVCC版本链,一条数据经过多次修改会产生多个版本,而快照读是根据不同时机创建的快照获取数据的,那么快照读SQL在执行时该读取那个版本的数据就是靠ReadViw读视图来决定的。
ReadView读视图中包含了四个核心字段,也是读取数据的判断依据: | 字段 | 含义 | | -------------- | ---------------------------------------------------- | | m_ids | 当前活跃的事务ID集合 | | min_trx_id | 最小活跃事务ID | | max_trx_id | 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的) | | creator_trx_id | ReadView创建者的事务ID |
ReadView一共有四种匹配规则: | 条件 | 能否访问 | 说明 | | ---------------------------------- | ----------------------------------------- | -------------------------------------------- | | trx_id == creatro_trx_id | 可以访问该版本 | 成立,说明数据是当前这个事务更改的。 | | trx_id < min_trx_id | 可以访问该版本 | 成立,说明数据已经提交了。 | | trx_id > max_trx_id | 不可以访问该版本 | 成立,说明该事务是在ReadView生成后才开启的。 | | min_trx_id <= trx_id <= max_trx_id | 如果trx_id不在m_ids中,那么可以访问该版本 | 成立,说明数据已经提交。 |
不同隔离级别下MVCC分析
READ-COMMITTED隔离级别
前面有提到过在READ-COMMITTED隔离级别下事务在每次快照读SQL执行时创建ReadView,每次创建的ReadView的四个字段对应的值也是不同的,所以在READ-COMMITTED隔离级别下每次快照读SQL获取的数据可能也是不同的。
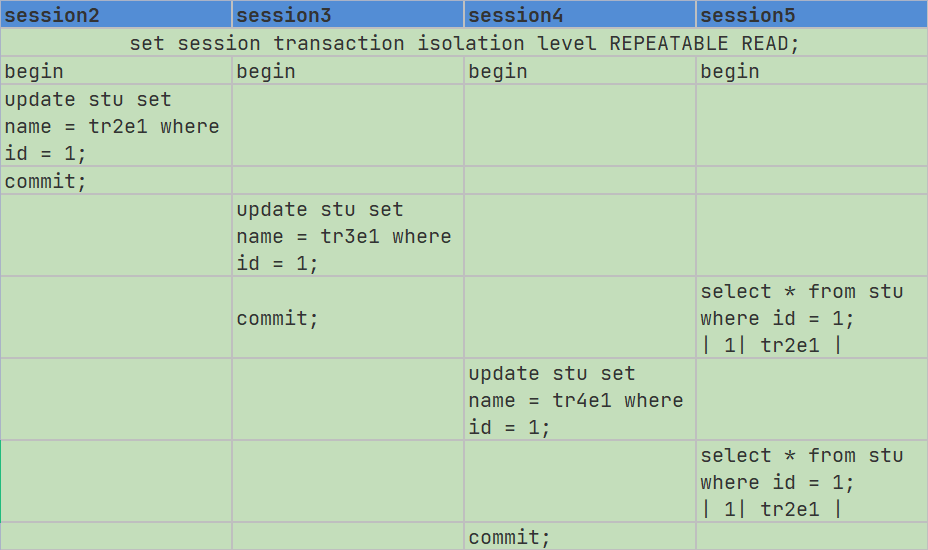
下面通过一个READ-COMMITTED隔离级别下并发事务的案例来详细看看:
现有四个并发事务同时访问一条数据:
![]()
![]()
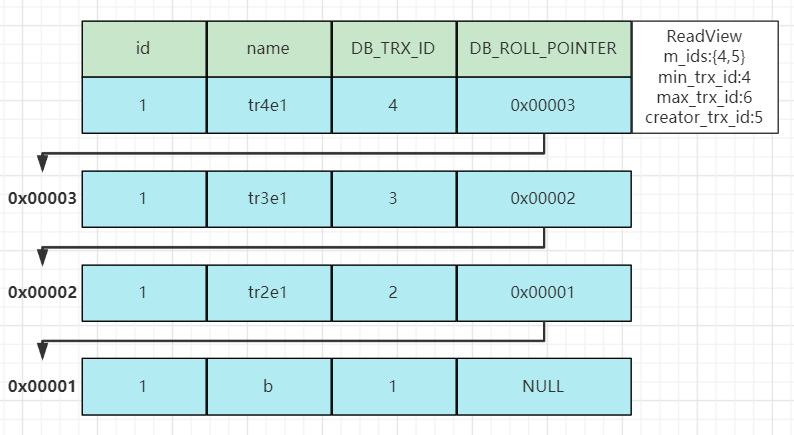
在上述并发事务中,事务5查询了两次id为1的数据,因为当前的隔离级别设置为了READ-COMMITTED,事务在每次快照读SQL执行时创建一个ReadView,每次生成的ReadView中的四个字段值都不同。那么三次快照读都会根据生成的ReadView中的字段进行规则匹配,从而决定返回的数据。接下来看看流程:
事务5第一次快照读解读
事务5第一次进行查询时生成的ReadView以及原数据如下图:
![]()
在匹配版本数据前,先与表中数据进行匹配:
该数据对应的DB_TRX_ID为3,此时MVCC就会通过ReadView带着这条数据去进行规则匹配:
首先是第一条规则db_trx_id == creator_trx_id,db_trx_id(3)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id < min_trx_id,db_trx_id(3)不小于min_trx_id(3)故不成立;
第三条规则db_trx_id > max_trx_id,db_trx_id(3)小于max_trx_id(6)故不成立;
第四条规则min_trx_id <= db_trx_id <= max_trx_id,db_trx_id(3)在min_trx(3)与max_trx_id(6)之间,但是同时处于m_ids(3,4,5)集合之中故也不成立。
经过这次匹配,表中最新的数据无法匹配,故要与MVCC版本链中最上面的数据进行规则匹配
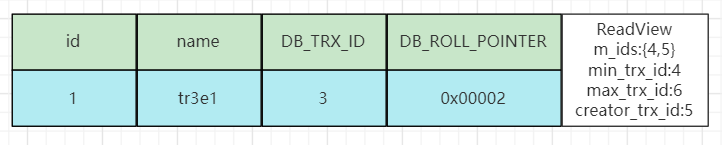
与MVCC版本链中最上方的版本进行匹配:
![]()
第一条规则db_trx_id(2)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(2)小于min_trx_id(3),该版本的数据满足匹配规则中的第二条,说明数据已经提交,此时匹配将终止并返回这个版本对应的数据。
事务5第二次快照读
因为当前事务的隔离级别为READ-COMMITTED(读已提交),所以在每次快照读的时候都会创建一个ReadView,所以事务5第二次进行查询时生成的ReadView以及原数据如下图:
![]()
在匹配版本数据前,先与表中数据进行匹配:
该数据对应的DB_TRX_ID为4,此时MVCC就会通过ReadView带着这条数据去进行规则匹配:
首先是第一条规则db_trx_id == creator_trx_id,db_trx_id(4)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id < min_trx_id,db_trx_id(4)不小于min_trx_id(4)故不成立;
第三条规则db_trx_id > max_trx_id,db_trx_id(4)小于max_trx_id(6)故不成立;
第四条规则min_trx_id <= db_trx_id <= max_trx_id,db_trx_id(4)在min_trx(4)与max_trx_id(6)之间,但是同时处于m_ids(4,5)集合之中故也不成立。
经过这次匹配,表中最新的数据无法匹配,故要与MVCC版本链中最上面的数据进行规则匹配
与MVCC版本链中最上方的版本进行匹配:
![]()
第一条规则db_trx_id(3)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(3)小于min_trx_id(4),该版本的数据满足匹配规则中的第二条,说明数据已经提交,此时匹配将终止并返回这个版本对应的数据。
REPEATABLE-READ级别
现在来看看REPEATABLE-READ可重复读隔离级别有什么不同的地方。同样,有四个并发事务同时访问一条数据:
![]()
![]()
在上述并发事务中,事务5查询了两次id为1的数据,因为当前的隔离级别设置为了REPEATABLE-READ,事务在第一次快照读SQL执行时创建ReadView,后续该事务所有的快照读都复用该ReadView。接下来看看流程:
事务5第一次快照读解读
事务5第一次进行查询时生成的ReadView以及原数据如下图:
![]()
在匹配版本数据前,先与表中数据进行匹配:
该数据对应的DB_TRX_ID为3,此时MVCC就会通过ReadView带着这条数据去进行规则匹配:
首先是第一条规则db_trx_id == creator_trx_id,db_trx_id(3)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id < min_trx_id,db_trx_id(3)不小于min_trx_id(3)故不成立;
第三条规则db_trx_id > max_trx_id,db_trx_id(3)小于max_trx_id(6)故不成立;
第四条规则min_trx_id <= db_trx_id <= max_trx_id,db_trx_id(3)在min_trx(3)与max_trx_id(6)之间,但是同时处于m_ids(3,4,5)集合之中故也不成立。
经过这次匹配,表中最新的数据无法匹配,故要与MVCC版本链中最上面的数据进行规则匹配
与MVCC版本链中最上方的版本进行匹配:
![]()
第一条规则db_trx_id(2)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(2)小于min_trx_id(3),该版本的数据满足匹配规则中的第二条,说明数据已经提交,此时匹配将终止并返回这个版本对应的数据。
事务5第二次快照读解读
因为当前事务的隔离级别为REPEATABLE-READ(可重复读),所以第二次快照读也会沿用第一次快照读时创建的ReadView,如下:
![]()
在匹配版本数据前,先与表中数据进行匹配:
该数据对应的DB_TRX_ID为4,此时MVCC就会通过ReadView带着这条数据去进行规则匹配:
首先是第一条规则db_trx_id == creator_trx_id,db_trx_id(4)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id < min_trx_id,db_trx_id(4)不小于min_trx_id(3)故不成立;
第三条规则db_trx_id > max_trx_id,db_trx_id(4)小于max_trx_id(6)故不成立;
第四条规则min_trx_id <= db_trx_id <= max_trx_id,db_trx_id(4)在min_trx(4)与max_trx_id(6)之间,但是同时处于m_ids(4,5)集合之中故也不成立。
经过这次匹配,表中最新的数据无法匹配,故要与MVCC版本链中最上面的数据进行规则匹配
与MVCC版本链中最上方的版本进行匹配:
![]()
第一条规则db_trx_id(3)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(3)不小于min_trx_id(4)故不成立;
第三条规则db_trx_id小于max_trx_id(6)故不成立;
第四条规则db_trx_id(3)在min_trx(3)与max_trx_id(6)之间,但是同时处于m_ids(3,4,5)集合之中故也不成立。
经过第二次匹配,MVCC版本链中最上层的数据版本也无法匹配,故要与第二条版本进行匹配
与MVCC版本链中第二条版本进行匹配:
![]()
第一条规则db_trx_id(2)不等于creator_trx_id(5)故不成立;
第二条规则db_trx_id(2)小于min_trx_id(3),该版本的数据满足匹配规则中的第二条,说明数据已经提交,此时匹配将终止并返回这个版本对应的数据。
Enjoy GreatSQL :)
关于 GreatSQL
GreatSQL是由万里数据库维护的MySQL分支,专注于提升MGR可靠性及性能,支持InnoDB并行查询特性,是适用于金融级应用的MySQL分支版本。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
欢迎来GreatSQL社区发帖提问 https://greatsql.cn/
![20221008151816]()
技术交流群:
微信:扫码添加GreatSQL社区助手微信好友,发送验证信息加群。
![图片]()