自由构建 探索无限。10月13日,LigaAI受邀参加2022亚马逊云科技中国峰会,并发表了题为「利用亚马逊云科技AI/ML服务开启新一代智能研发协作的大门」的主题演讲。 聚焦数据驱动,本文将与大家分享「数据驱动+AI+研发协作」模式下的创新火花。
一、当前研发管理正在面临什么难题?
这个问题可以从开发团队、管理者和协作工具三个维度解读。
![]()
01 开发团队维度
- 很难与业务团队和管理者在目标上达成一致;
- 不认为进度上报、工时登记等属于本职工作,因此完成积极性通常不高;
- 与其他团队协作缺乏有效沟通机制。所有事情依靠人推动,一旦忘记或遗漏就会受到阻碍;
- 大量时间耗费在与开发本身无关的任务上,导致难以专注。
02 管理者维度
- 基于开发团队现状,难以获取真实进度数据。大部分进度数据滞后,或需依靠人工干预;
- 研发产出难以通过现有数据衡量。后补的数据失真严重,而原始数据的处理又十分依赖个人的分析和决策能力;
- 日常管理动作所需的进度跟进、沟通、任务分派、各方协同等微观管理,劳心劳力。
03 协作工具维度
- 灵活性较差。 团队只能按照工具本身的方式工作,不能随意适配现有的流程;
- 开放程度低。 没有丰富的API和数据同步机制,很难与其他系统打通;
- 自动化程度低。 所有的事情必须通过人力手工处理,增加了使用负担,也导致团队不愿意使用工具,进一步加剧数据失真。
以上三方面原因综合导致研发效能提升困难。
二、更好的研发协作方式是什么?
传统研发项目管理中,协作过程串行化严重,团队内部的大量空转造成了巨大浪费,同时也产生了很大的项目延期风险。
LigaAI认为未来更好的的协作形态应该是「赋能型管理+自驱型团队+智能化工具」的有机结合。
![]()
新一代研发协作模式具有业务导向、目标导向、全员参与等特点。要实现以上效果,需要组织文化与团队成员配合作战;
此外,合适的工具也能帮助团队更快地实现目标,二者缺一不可;而风险预警、智能协作等场景也非常适合通过 AI 提效。
让机器处理机器擅长的事情,让人回归到更有创造力的本职工作,这就是 「数据+AI」驱动的下一代研发协作。
三、为什么要构建数据驱动型企业?
01 对内全面提效
从企业内部看,数据驱动的研发协作等于全面提效。通过数据驱动,LigaAI希望达成以下目标:
![]()
· 提高组织内部透明度。 让各个部门可以随时了解其他部门在做什么、进度如何;保证各部门可以顺畅协作,减少信息损耗,提高流转效率。
· 培养数据人才和数据意识,让大家养成关心数据、使用数据的习惯。
· 提高研发团队的业务参与度。 缩短研发团队与业务的距离,让研发成员了解用户对自己研发的产品的使用情况和满意度。
· 提升开发人员的成就感。 与业务参与度相伴而生,要让大家更愿意主动地解决业务问题。
· 企业内部各部门在内部决策时,可以有所依据,降低决策难度和决策成本。
最后,全面提升业务敏捷性。
02 对外增强产品竞争力
ToB SaaS企业内部提效最终要表现在外部市场。从SaaS客户的视角看,数据驱动的研发协作意味着产品竞争力增强。
![]()
· 于SaaS产品而言,用户体验是重要指标。通过数据驱动,可以提升用户体验和客户满意。
· 提供个性化的服务支持。 采用「数据+AI」的模式,学习不同用户的使用习惯,推荐更适合的流程,为不同用户提供针对性的服务;还能降低上手成本,让产品陪伴用户成长。
· 传统工具常提供大量原始数据,需要用户自己进行分析解释;LigaAI以「数据+AI」的方式,为用户提供辅助的决策建议,实现数据洞察。
四、如何构建数据驱动型研发协作和企业?
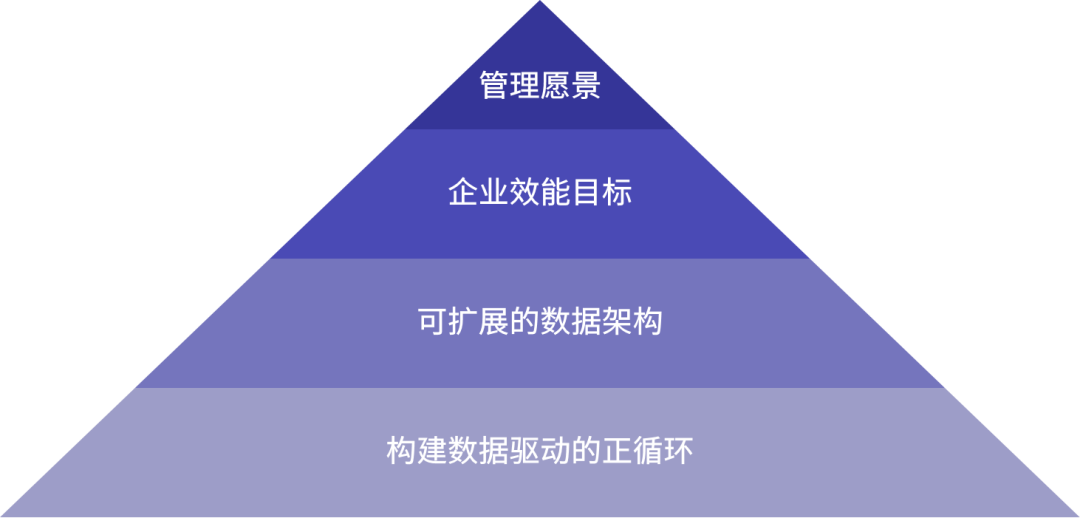
下图的金字塔自上而下是一个由虚转实的过程,四层内容分别代表愿景、目标、实施和数据利用。
![]()
下面以LigaAI为例,展开分享如何按照金字塔步骤,搭建数据驱动型企业。
01 管理愿景
数据驱动是一种理念、战略。企业需要先在内部达成统一的认识,形成自上而下的、一致的数据愿景。
02 企业效能目标
确定愿景后,定义阶段性目标。LigaAI聚焦研发协作,当前阶段最主要的目标就是企业效能提升,那么「企业效能提升」就是数据驱动的目标。
以下是一些推荐的效能目标。
![]()
03 可扩展的数据架构
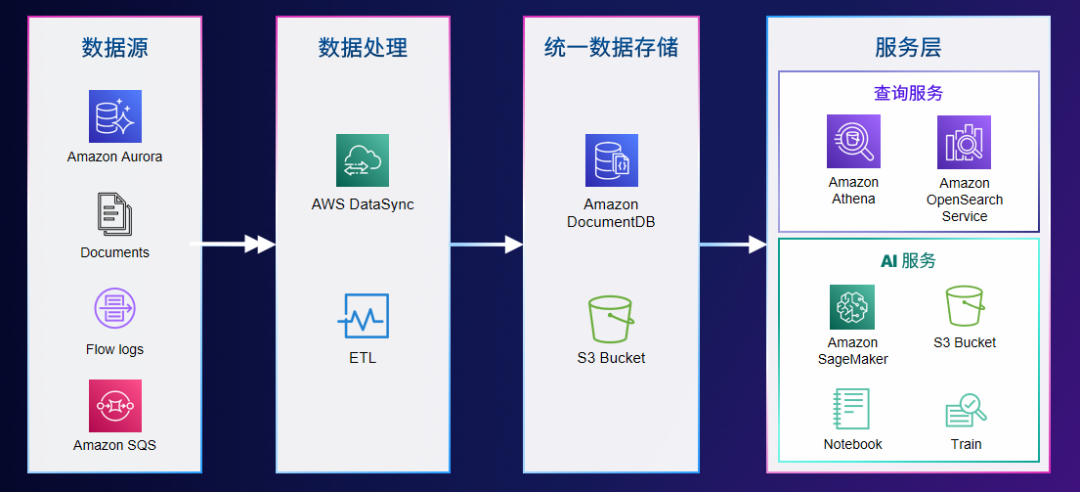
明晰目标后,就可以实施。LigaAI先搭建了一个最小化的可扩展数据架构(下图是简化版的核心架构图),从左至右分别是数据源、数据处理、数据存储和数据服务。
![]()
LigaAI的数据源包括Aurora关系型数据,以及非结构化的文档数据、日志数据、队列数据等;
根据业务情况,数据源处理分为实时和离线处理:实时数据处理一般使用DataSync服务,而非实时数据则采用传统的ETL程序进行处理;
所有处理好的数据会 统一放到基础的数据存储平台,LigaAI选择的是DocumentDB和S3 ;
最后,数据服务分为两个部分:已经处理好的数据,通过查询服务直接对内部、外部应用提供接口;
与AI相关的服务,LigaAI以SageMaker为核心,搭建了一套AI工作流程,并实现AI数据训练、模型发布、模型部署等自动化处理。
04 构建数据驱动的正循环
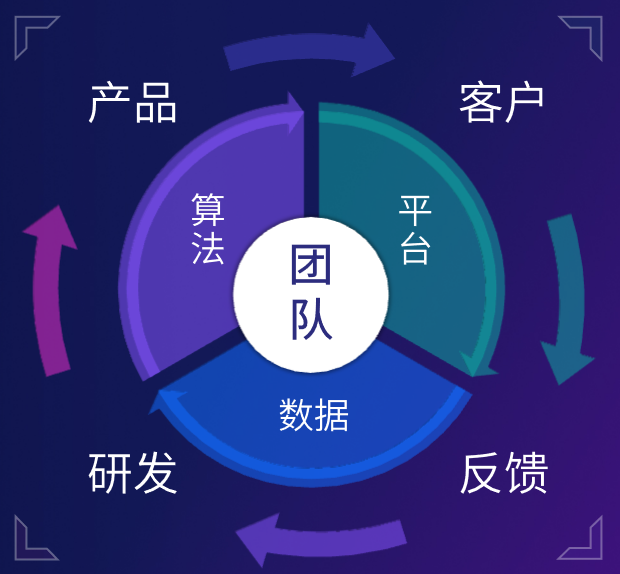
将架构和平台应用结合,构建数据驱动的正向循环。
![]()
LigaAI的数据驱动正循环以团队为核心,团队在LigaAI平台上使用产品并产生数据、数据驱动算法、算法改进平台。平台、数据、算法三者相互驱动,形成「效率提升内循环」,这是对平台客户的价值;
在企业内部,LigaAI形成了以产品、客户体验、反馈池、研发迭代为主体的「价值滚动外循环」。
内外两个循环共同组成我们的价值飞轮,最终提升产品竞争力。
五、 关于数据驱动提效的建议
构建数据驱动时,可以从价值比较高的具体场景,或比较容易出效果的场景切入,增强团队信心;
也可以利用云产品快速搭建合适的数据架构,实现快速启动;
启动后,需要关注数据生产、使用、改进的正循环。只有不断改进,才能走得更远;
最后,注重数据安全、隐私与合规,也非常重要。
六、如何衡量数据驱动为企业带来的效益?
下面是一组LigaAI构建数据驱动型企业的效益数据。
01 研发协作提效
- 简化需求排期流程
- 更有效的研发工作衡量方法
- 超过 40% 的任务实现自动流转及通知
- 新模型上线,从 2 周变成了 2 天
02 价值交付
- 提高了产研对业务的参与度
- 快速反馈,提高业务的敏捷性
- 更高的客户评价与市场竞争力
整体而言,LigaAI帮助诸多企业成功实现了业务协同、降本增效的大目标。
# Liga总结
以「数据+AI」为核心的下一代研发协作,能够帮助企业完成更多的任务:让机器做繁琐重复的工作,将人回归到本职角色专注创造。
减少琐事和干扰事项的打扰,让开发者体验沉浸式工作,让专注激发、释放更多的创造力和生产力。
关于 LigaAI
LigaAI是新一代智能研发协作平台。我们以人工智能技术为核心,致力于通过AI场景化繁为简,提升协作效率,赋能广大研发团队。
从开发者的具体工作场景出发,LigaAI通过人工智能将开发者们从繁杂琐事中抽离出来,为其提供简洁、智能的协作体验,也为不同类型的组织提供数字化、个性化、智能化的项目协作平台。
了解更多敏捷开发、项目管理、行业动态等消息,关注我们 [LigaAI@oschina](https://my.oschina.net/u/5057806) 或点击LigaAI - 新一代智能研发协作平台,在线申请体验我们的产品。