![]()
前言
Drools是一款老牌的java规则引擎框架,早在十几年前,我刚工作的时候,曾在一家第三方支付企业工作。在核心的支付路由层面我记得就是用Drools来做的。
难能可贵的是,Drools这个项目在十几年后还依旧保持着开源和更新。
https://github.com/kiegroup/drools
而LiteFlow也是一款java规则引擎,于2020年开源。经过2年的迭代,现在功能和特性也非常棒,很适合用在高复杂度的核心业务上,同时又能保持业务的灵活性。
https://gitee.com/dromara/liteFlow
这篇文章我们就来深入比较下这两款框架,都适合用在什么样的场景,有什么异同点,以及在相同的场景下表现力如何。
(其中Drools基于7.6.0版本,LiteFlow基于2.9.0版本)
虽然题主就是开源项目LiteFlow的作者,但是我这几天也深入了解了下Drools,尽量从很客观的角度尝试去分析。很多比对的结果都是基于实际使用后的感受。不过题主难免会带有一些主观的心理以及了解的片面性,尤其是Drools现在已经更新到了8.X,说实话并没有使用过。所以说的不正确的地方也请指正。
规则引擎的定义
首先我想明确下规则引擎的定义,因为很多小伙伴容易把规则引擎和流程引擎的概念混在一起。
规则引擎通常是嵌入在应用程序组件中的,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
简单来说就是,规则引擎主要解决易变逻辑和业务耦合的问题,规则驱动逻辑。以前项目内写死在代码里的逻辑用规则引擎可以提出来,随时热变更。
而流程引擎实现了将多个业务参与者之间按照某种预定义的规则进行流转,通常需要涉及到角色信息。
简单来说就是,流程引擎主要解决业务在不同角色之间的流转问题,如请假流程,审批流程,往往要经过多个角色。规则驱动角色流转。
两款框架的异同点
Drools和LiteFlow都是优秀的开源框架,都能把业务中的逻辑给剥离出来。并且拥有自己表达式语法。
但是有所区别的是,Drools强调逻辑的片段规则化,你可以把核心易变部分写成一个规则文件,等同于原先写在java里的代码现在搬迁到了规则文件。规则文件里的代码全都是可以热变更的。
而LiteFlow是基于组件式的思想设计的,更强调组件的规则化,覆盖范围是整个业务。编排的最小单位是组件,规则文件用来串联组件间的流转。同时LiteFlow也支持片段式的代码规则化,因为LiteFlow也支持业务逻辑的脚本化。规则支持热变更。
所以评判一个规则引擎是否合格的主要因素有:
- 有没有灵活的规则表达式来支持
- 规则和Java之间能否非常方便的联动
- API调用是否方便,和各种场景系统的集成如何
- 侵入性耦合比较
- 规则的学习成本,是否容易上手
- 规则表达式是否有语言插件
- 规则能否和业务松耦合,存储于其他地方
- 规则的变更能否实时改变逻辑
- 是否有界面形态来支持非技术人员的使用
- 框架的性能表现
下面就从这几个方面来细细比较两款框架的表现力
规则表达式
Drools的规则表达式为Java量身定制的基于Charles Forgy的RETE算法的规则引擎的实现。
Drools的规则表达式贴近自然编程语言,拥有自己的扩展名文件drl,语法支持全,基本上自然编程语言有的语法drl全有。所以,完全可以把java的逻辑写在drl文件中。
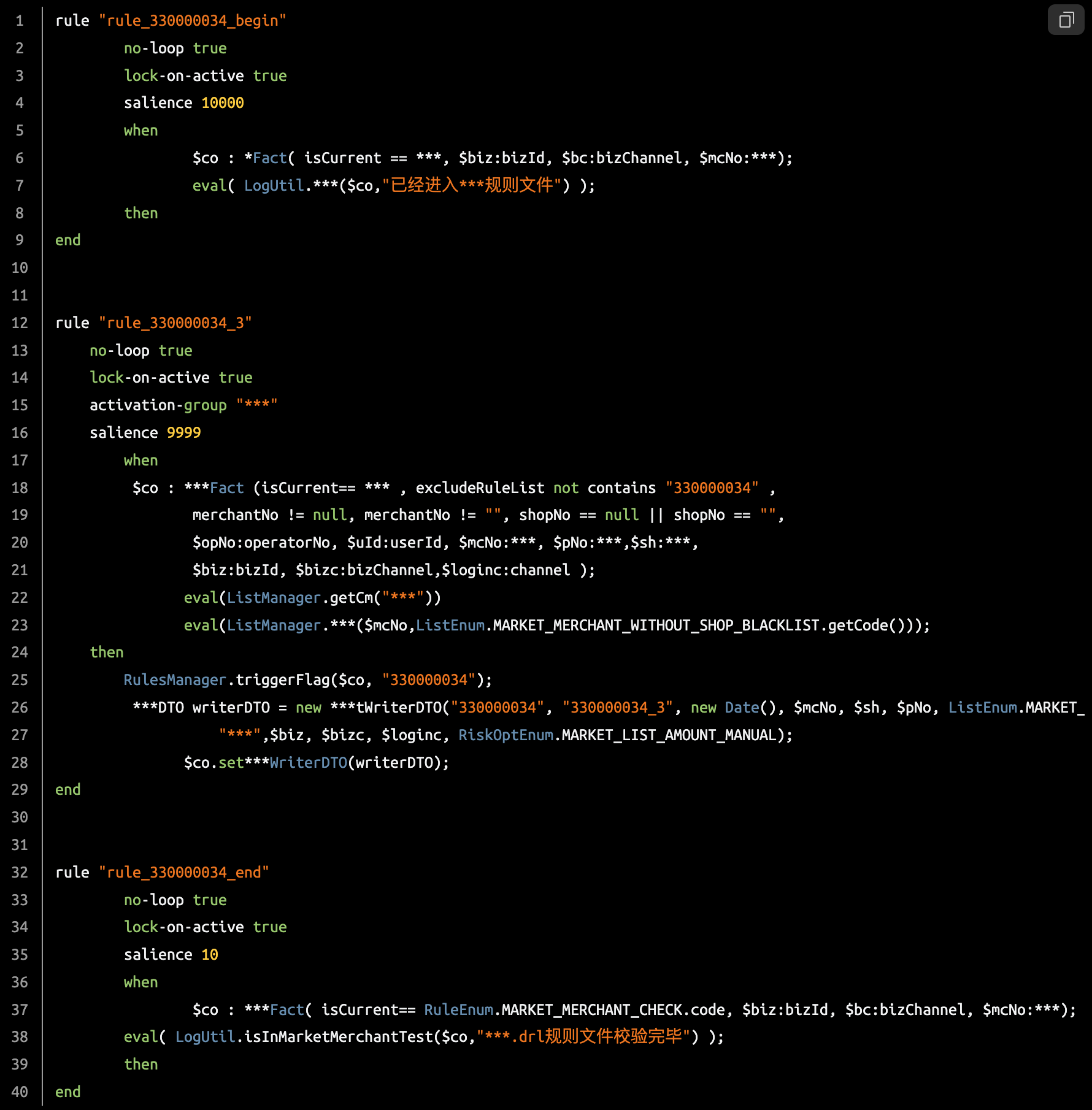
来看下drl文件的大体样子:
![]()
可以看到,Drools定义规则的方式是一个规则一段,有明确的when...then,表示当满足什么条件时,做什么。在触发规则时候,会自动判断该去执行哪一段rule,如果满足多个条件,是可以触发多个规则的then的。
LiteFlow编排表达式简单易懂,底层用EL表达式语言包装而成。用于组件的流转,支持异步,选择,条件,循环,嵌套等一些场景。
组件层面不仅可以是java组件,还可以用脚本语言来编写,目前支持了Groovy和QLExpress两种脚本语言。所有能用java实现的,用脚本语言都可以做到。
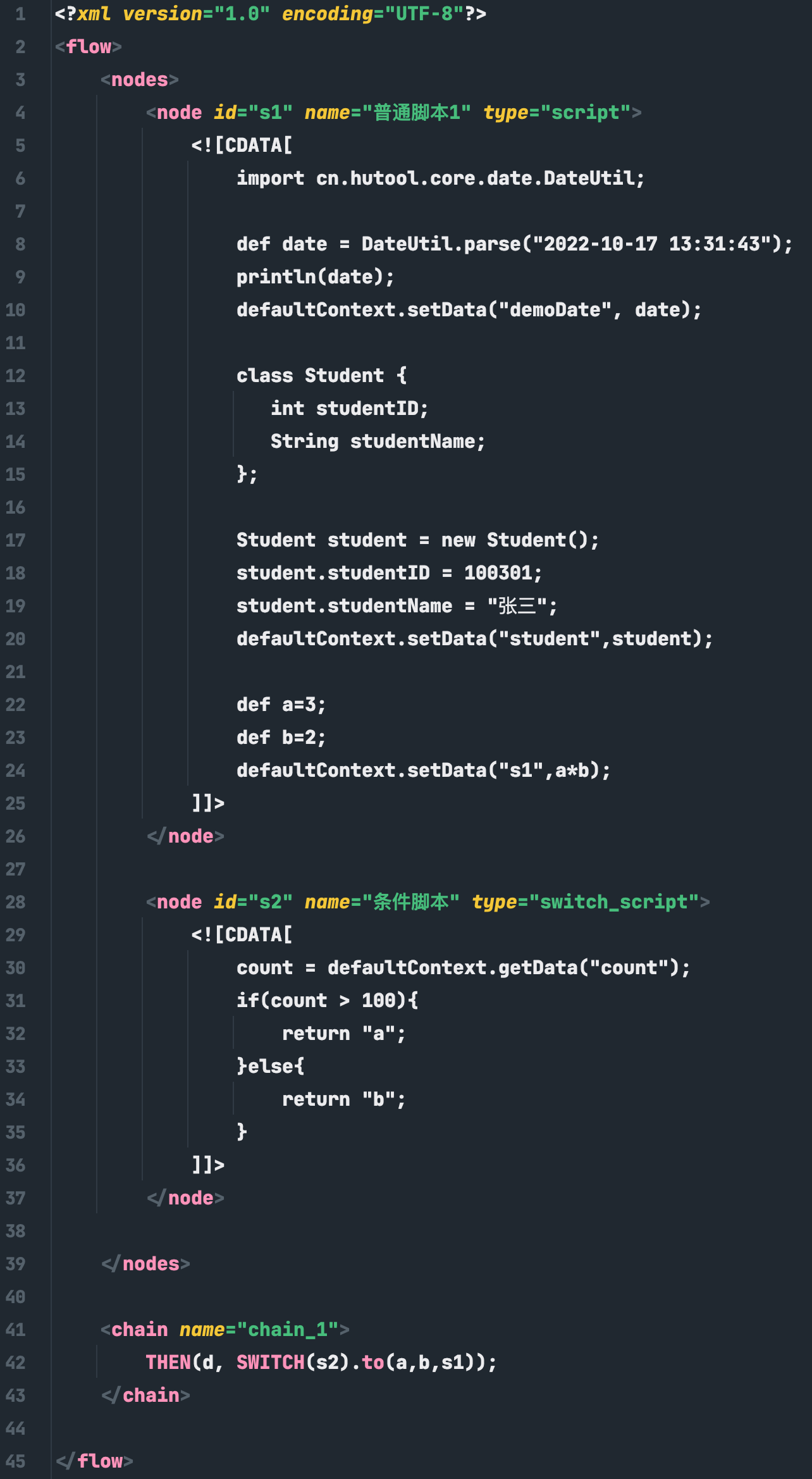
LiteFlow的规则文件大体长这个样子:
![]()
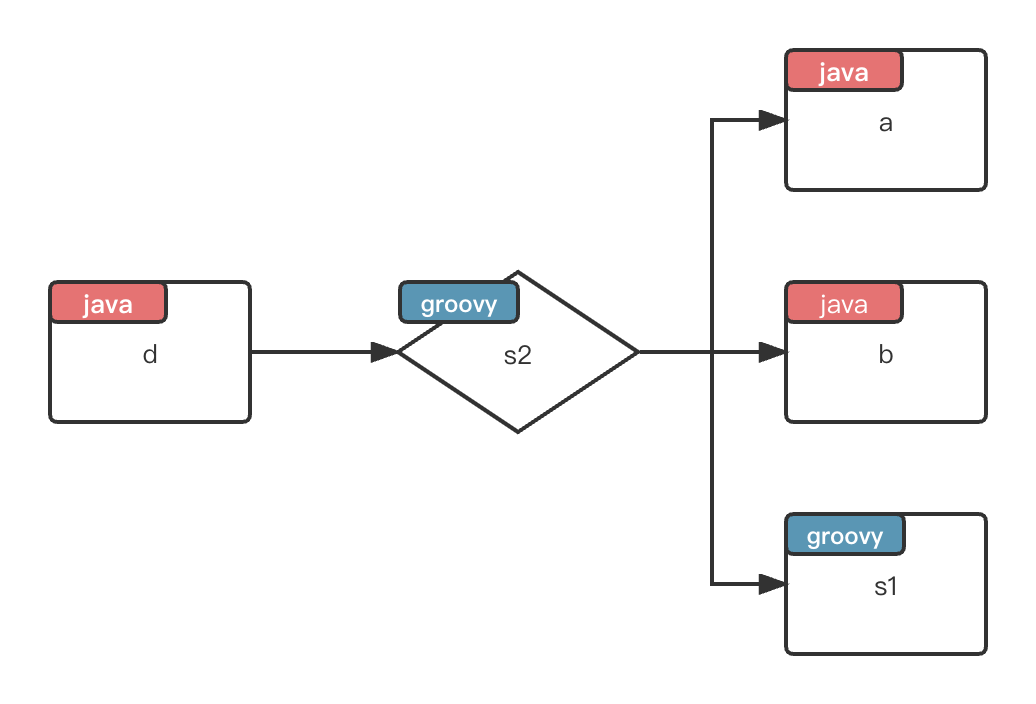
上述LiteFlow的编排表达式中,所表达的是下面一个逻辑流:
![]()
LiteFlow编排表达式支持THEN(同步),WHEN(异步),SWITCH(选择),IF(条件),FOR(次数循环),WHILE(条件循环)等大表达式,每个表达式又有许多扩展关键字可供选用。
脚本组件支持的Groovy基本和java语法差不多,Groovy语言支持的一切你均可使用。甚至可以在Groovy语法中额外定义类和方法。
结论
总的来说,两款框架都能用脚本来定义逻辑片段,在定义逻辑片段层面,Drools使用的是自研语法,LiteFlow使用的是插件式的Groovy,其实个人觉得Groovy更接近java语法,你甚至于可以在其中定义类和方法。Drools在高级应用中,也可以用规则定义方法,但是我觉得并不那么自然。
LiteFlow最大的特点是除了定义逻辑片段外,还可以进行全局组件的编排。而这正是LiteFlow称之为编排式规则引擎的由来。使用简单的编排语法可以设计出复杂的逻辑流。支持java和脚本混编。
和Java的数据交换
在Drools的规则中,你可以通过import关键字来引入java的一些类包类进行调用。
在LiteFlow的脚本组件中,Groovy也可以通过import 来引入java的任何包来调用。
Drools中,可以直接引用到fact对象。
LiteFlow中,可以直接引用到context对象,context上下文贯穿整个编排链路。
LiteFlow中,通过@ScriptBean注解,你甚至可以把spring上下文中的bean引入进来直接调用。利用这个特性,甚至于可以在脚本中调用rpc,调用数据库dao对象取数据。这个在Drools里面虽然也可以做到,但是要麻烦的多。
结论
基本都能满足和java的数据交换需求,但是LiteFlow在场景上支持的显然更加多一点。
API以及集成
在API调用层面,Drools需要去定义KieContainer,KBase,KSession一系列对象。LiteFlow框架只需要使用到LiteFlowExecutor对象。
Drools支持了编程式接入,但是在springboot中需要自己写很多配置类来去集成。
LiteFlow不仅支持了编程式接入,在springboot环境下更是提供了自动装配的starer接入方式,连定义LiteFlowExecutor都不需要,直接从上下文中就可以拿到自动装配后的对象进行调用。
结论
LiteFlow api更加简单,同Springboot集成度更加高。
侵入性耦合比较
Drools需要在java代码里需要用到规则的地方用KSession对象去匹配规则进行调用。规则和java是分离的。在调用层面耦合了KSession调用对象。
LiteFlow的规则和java也是分离的,但是LiteFlow多了组件这一概念,所以在组件层面是需要继承的,但是同时也提供声明式组件的选择,使用声明式的方式耦合相对要减少一些。在调用层面也需要去调用LiteFlowExecutor对象。
结论
在耦合度上面,由于LiteFlow提供编排特性,API耦合度相对稍高一些。Drools耦合少一些。
规则的学习成本
Drools的规则学习成本挺高的。由于是自研的规则语法,需要一个很全面的熟悉过程。而且文档全英文。
LiteFlow的编排规则极其简单,如果你不使用脚本组件的话,基本上10分钟即可上手。就算使用了groovy脚本,由于groovy非常类似于java,学习成本也非常少。况且有大量的学习资料可以参阅。
LiteFlow的文档中英文齐全,还有良好的中文社区可以答疑解惑。
结论
在规则学习成本上,Drools的规则学习曲线比LiteFlow高出不止一丁点。
是否有语言插件
Drools在Eclipse和IDEA上均有插件来做语法的高亮,预检查和提示。
LiteFlow在IDEA上有插件来做高亮,预检查和提示。Eclipse上没有。
结论
考虑到使用eclipse的人几乎很少了,基本上2款规则引擎在语言插件上都做到了。
规则的存储
Drools的规则理论上支持你的规则存于任何地方,但这一切都需要你手动去额外完成。自己去存,自己去取。
Drools还有款workbeanch的插件,可以将规则存于workbeanch中。只有这个是不需要自己存取的。
LiteFlow除了本地规则以外,原生支持将规则存储于任何标准SQL的数据库,还原生支持了Nacos,Etcd,zookeeper等注册中心。只需要配置一下即可。除此之外,还提供了扩展接口,方便你自己扩展成任意的存储点。
结论
LiteFlow的规则存储支持比Drools丰富的多。
规则的变更能否实时改变逻辑
Drools热刷新规则的方式现在看起来有点傻,它的规则是通过生成jar的方式。然后系统远程动态读取jar包来完成规则刷新的。
而且一定得通过workbench的方式进行规则的热变更。
LiteFlow在这个层面做的高级很多。如果你是用Nacos,Etcd,zookeeper等方式存储,不用做任何事,改变即自动刷新。如果你是SQL数据库存储,或者本地存储。在改变规则之后,需要调用LiteFlow框架提供的一个API进行热变更。2种方式均可热更新。并且在高并发情况下是平滑的。
结论
LiteFlow在热更新设计层面比Drools先进很多。
是否有界面形态来支持
Drools有workbench,workbench是一个独立的插件包,提供了web界面编写规则以及fact对象。并提供了检查和部署的能力。但因为Drools主要关心逻辑片段,并不需要提供编排层面的拖拽UI功能,只是提供了在界面上编写规则的能力。
LiteFlow并没有界面形态。目前只能通过第三方的Nacos,Etcd提供的界面来辅助完成界面的规则修改。
结论
Drools在UI形态生态上领先LiteFlow一截。
框架的性能表现
这里用Drools和LiteFlow实现了同样的一段逻辑Demo。
根据订单金额来加积分的Demo案例。
案例逻辑很简单,根据订单的金额来动态判断该加多少积分:
小于100元,不加积分。
100到500元,加100积分。
500到1000元,加500积分。
1000元以上,加1000积分。
其中Drools的规则如下:
package rules;
import com.example.droolsdemo.entity.Order;
rule "score_1"
when
$order:Order(amount<100)
then
$order.setScore(0);
System.out.println("触发了规则1");
end
rule "score_2"
when
$order:Order(amount>=100 && amount < 500)
then
$order.setScore(100);
System.out.println("触发了规则2");
end
rule "score_3"
when
$order:Order(amount>=500 && amount < 1000)
then
$order.setScore(500);
System.out.println("触发了规则3");
end
rule "score_4"
when
$order:Order(amount>=1000)
then
$order.setScore(1000);
System.out.println("触发了规则4");
end
其中等价的LiteFlow规则如下:
<?xml version="1.0" encoding="UTF-8"?>
<flow>
<nodes>
<node id="w" type="switch_script">
<![CDATA[
def amount = defaultContext.getData("order").getAmount();
if (amount < 100){
return "a";
}else if(amount >= 100 && amount < 500){
return "b";
}else if(amount >= 500 && amount < 1000){
return "c";
}else{
return "d";
}
]]>
</node>
<node id="a" type="script">
<![CDATA[
def order = defaultContext.getData("order");
order.setScore(0);
println("执行规则a");
]]>
</node>
<node id="b" type="script">
<![CDATA[
def order = defaultContext.getData("order");
order.setScore(100);
println("执行规则b");
]]>
</node>
<node id="c" type="script">
<![CDATA[
def order = defaultContext.getData("order");
order.setScore(500);
println("执行规则c");
]]>
</node>
<node id="d" type="script">
<![CDATA[
def order = defaultContext.getData("order");
order.setScore(1000);
println("执行规则d");
]]>
</node>
</nodes>
<chain name="chain1">
SWITCH(w).TO(a, b, c, d);
</chain>
</flow>
两款框架都全用脚本来写的情况下,测试的过程中,去除所有的打印日志,执行10w次,得到的结果如下:
Drools 执行10w次,耗时0.7秒
LiteFlow全脚本组件执行10w次,耗时3.6秒
由于LiteFlow在全脚本组件的情况下,需要做脚本的执行和编排脚本的执行,所以花费的时间更长。
如果LiteFlow把组件更换成java,再进行执行,得到的结果如下:
LiteFlow 全Java组件执行10w次,耗时0.5秒
结论
如果LiteFlow采用全脚本的方式运行,耗时会比Drools更长。如果采用全java组件的方式运行,其性能能超越Drools一点。
所以对于LiteFlow而言,如果你希望更高的性能,则采用java组件,如果你希望更高的灵活性,则采用脚本组件。
其实在实际业务中,把容易更改的逻辑抽出来写成脚本组件,采用java+脚本混编的方式,是更为推荐的做法。
结语
为什么会拿Drools来作为比较,其一在题主心中,Drools一直是规则引擎界的标杆,drools有很多理念非常值得学习。其二也是因为题主也只熟悉Drools,其他的框架没有很好的使用过的缘故。
但是综合来看,作为国产规则引擎后起之秀LiteFlow显然在设计理念,支持度方面是要优于Drools的。编排式规则引擎作为规则引擎的一个新的方向,也会一直探索下去的。希望大家能多多支持这款国产的规则引擎。在编排方向,LiteFlow除了文中所提到的一些特性以外,还有很多其他各种各样的探索性的玩法和高级特性。是一款很值得深挖的框架。
官网地址: https://liteflow.yomahub.com/