2022年 5月26日,蚂蚁BizStack云原生开发和治理平台在“阿里云-云栖号”线上进行新品发布会。
在数字化转型大背景下,企业如何解决业务敏捷交付、科技持续治理难题? 本次新品发布会由蚂蚁集团产品专家耿柳带来基于蚂蚁科技的实践和思考,分享蚂蚁BizStack产品能力和解决方案。 速记集合了BizStack云原生开发和治理平台新品发布会核心内容,干货满满。
中国人民银行印发《金融科技发展规划(2022-2025年)》 文件中指出金融机构应加快数字化转型,强化金融科技审慎监管为主线的战略方针。该文件同时在重点任务中强调了健全金融科技治理体系,打造新型数字基础设施,激活数字化经营新动能,夯实可持续化发展基础等监管趋势和行业要求。
在落地过程中,企业(金融机构)如何提升业技协同效能,加速业务创新和持续架构优化这类问题是业内面临的通用难题,具体表现在两个层面:
第一层:科技缺乏持续治理和运营优化能力
•架构规范靠文档,设计和最终实现不匹配
•资产分析靠人工,头痛医头脚痛医脚
•依赖关系错综复杂,排查全靠研发翻代码
第二层:业务、架构、技术难以形成合力
•一句话需求,业务和技术沟通有鸿沟
•系统烟囱竖井林立,重复造轮子协同难
•人员水平层次不齐,项目质效无保障
针对以上业内痛点挑战问题,第二章将会展开聊聊蚂蚁架构治理和云原生应用开发的实践和思考。
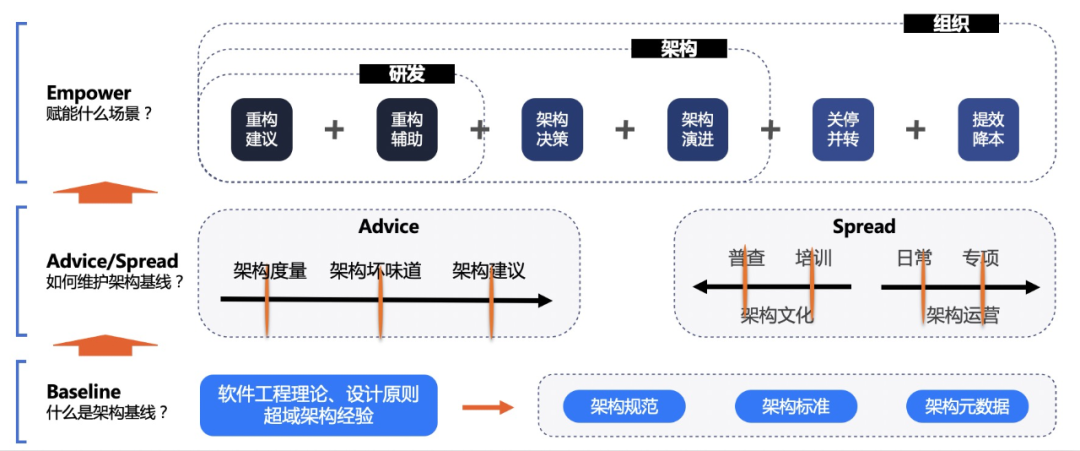
BASE(Baseline、Advice、Spread、Empower),即蚂蚁架构治理体系,用于维护组织架构标准、传播架构文化的机制和方法论。也具有蚂蚁架构底盘的含义。
![]()
什么是Baseline?架构基线即软件工程理论、设计原则以及超域架构经验所沉淀的一套架构规范、架构标准、架构元数据。
如何维护架构基线?主要有软硬两层面的做法:
•在硬性(Advice)层面通过技术手段建立架构度量机制,识别架构坏味道。
•在软性(Spread)层面通过文化宣导和运营机制,建立架构优化专项,培养架构师文化。
如何实现对场景的赋能?对一线研发人员,赋予重构建议和重构辅助;对架构师,提供架构决策和架构演进建议;对组织层面,支撑系统关停并转和提效降本。
![]()
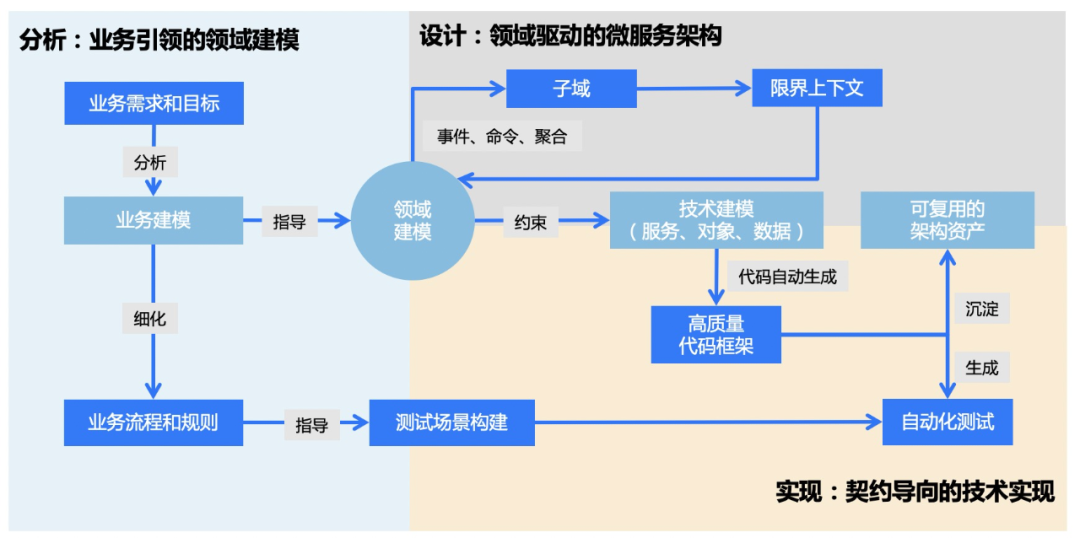
1.需求分析阶段,业务引领的领域建模,以业务需求和目标为导向,进行流程建模和业务规则细化。
2.架构设计阶段,领域驱动的微服务架构,通过事件、命令、聚合等方式,梳理限界上下文,定义微服务边界。
3.代码实现阶段,契约导向的技术实现,通过构建技术模型,自动生成高质量代码框架,形成可复用的架构资产,辅助自动化测试。
•横向来看,面向云原生应用的全生命周期,提供需求、设计、研发三个阶段的产品能力,提供一站式开发和治理解决方案。集成蚂蚁业务与技术最佳实践。
•纵向来看,向下衔接分布式架构基础设施,向上支撑中台及业务应用,集成蚂蚁业务和技术最佳实践。
•产品能力包含业务建模、架构资产结构化、架构巡检治理、低代码开发、中台可扩展等。
•解决客户云原生转型过程中的业务建模分析、架构规划治理、研发提效扩展等问题。
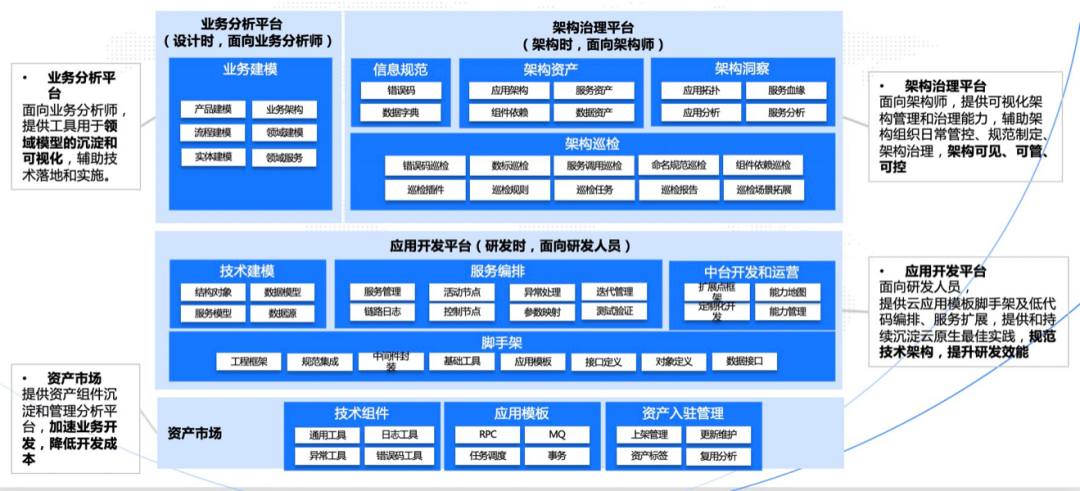
接下来详细介绍一下BizStack 的4大产品模块和5大核心能力
4大产品模块包括:
1.需求时,面向业务分析师的业务分析平台
2.设计时,面向架构师的架构治理平台
3.研发时,面向研发人员的应用开发平台
4.提供组件持续沉淀和管理分析能力的资产市场。
![]()
5大核心能力包括:
核心能力1:应用全流程打通和覆盖,建立云原生一体化实施工艺
实现从需求、设计、研发、运行的全流程覆盖,从业务模型、领域模型、技术模型到代码实现的全链路打通
核心能力2:一体化架构管理和治理平台,使架构可视可管可控
架构资产可视化,结构化自动保鲜;架构巡检平台化,支持场景自定义拓展;架构洞察智能化,辅助架构优化持续演进。
核心能力3:组件化开发,流程化编排,实现资产复用,提升研发效率
通过研发体系组件化、标准化、规范化,可减少30%代码量,有效提升研发效率。通过服务流程的可复用可扩展,能解决80%的共性流程问题,支撑业务快速迭代。
核心能力4:基于扩展点框架的中台开发和持续运营能力
平台化架构下,随着业务的扩展和复杂度提升,面临业务和平台耦合、业务和业务冲突的问题。为了解决这两类问题,在业务中台方法论指导下,BizStack 提供了一套基于扩展点框架的中台开发和持续运营的能力。
在技术层面,中台应用通过扩展点框架开放定制化能力,业务应用基于开放的扩展点实现差异化需求,同时针对不同的业务应用,提供业务身份的机制进行业务隔离。在运营层面,实现商业能力和扩展点的可视化,支持需求的结构化分析和业务接入流程。
核心能力5:基于可视化服务编排的后端低代码能力
在盘活架构资产的基础上,通过低代码托拉拽的方式,快速组合不同服务节点类型,同时支持图灵完备的逻辑表达和节点间的参数自动映射能力,提供完备的事务一致性和稳定性保障,以及测试能力验证支撑,通过传统开发和低代码融合的方式,提升后端研发效能。
![]()
BizStack 面向业务和科技的不同角色,通过业务分析平台、架构治理平台、应用开发平台和资产市场等核心产品能力,构建一体化、可视化、标准化、可复用的企业级云原生架构体系,助力金融机构持续提升业务交付效能和科技治理能力。
视频回顾观看:
https://yqh.aliyun.com/live/detail/28555
更多意向快速了解蚂蚁BizStack,欢迎扫码提交问卷!