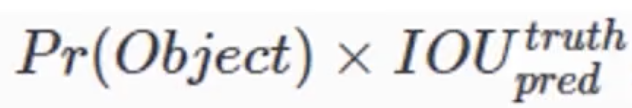YOLOV1
YOLO(You Only Look Once: Unified, Real-Time Object Detection)是Joseph Redmon和Ali Farhadi等于2015年首次提出,在2017年CVPR上,Joseph Redmon和Ali Farhadi又提出的YOLOV2,后又再次提出YOLOV3,它是一个标准的One-stage目标检测算法。
相对于Faster RCNN系列和SSD系列,它能够更好的贯彻采用直接回归的方法获取到当前需要检测的目标以及目标类别问题的思想。YOLO算法的核心点在于输入图像,采用同时预测多个Bounding box的位置和类别的方法来检测位置和类别的分类。它是一种更加彻底的端到端的目标检测识别的方法。相比于Faster RCNN和SSD而言,能够达到一个更快的检测速度,但是相对于这两个系列的算法而言,YOLO算法整体检测的精度会低一些。
YOLO算法采用直接回归功能的CNN来完成整个目标检测的过程。这个过程不需要额外,设计复杂的过程。SSD算法在对目标检测的过程中,一方面用到了Anchor机制,另一方面需要针对多个不同的feature map来进行预测。Faster RCNN算法需要通过一个RPN网络来获取到我们需要的候选Bounding box,再通过后续的预测模型来完成最终的预测结果。YOLO算法相比于这两种算法而言,没有Anchor机制,多尺度等等设计的过程。YOLO直接采用一个卷积网络,最终通过直接回归的方法,来获取多个Bounding box的位置以及类别。直接选用整图来进行模型的训练并且能够更好的区分目标和背景区域。
![]()
YOLOV1算法的核心思想就在于一方面它通过将图像分成S*S的格子。对于每一个格子(区域)去负责预测相应的物体。即包含GT物体中心的格子,由它来预测相应的物体。在上图中有一个带红点的格子,它包含了狗的一部分,因此我们就需要用这样一个格子来检测狗这种物体。又比如说包含了自行车的格子就用来预测自行车这种物体。
在实际使用的时候,每个格子都会预测B(超参值,通常为2)个检测框Bounding box及每个检测框的置信度(表明了当前的格子所包含物体的概率),对于每个检测框,要预测C个类别概率(含有待检测物体的可能性)。对于一个格子,它最终预测出来的向量的长度为5*B+C,这里5包含了每一个Bounding box的(x,y,w,h,c),c是置信度,而整个图所回归的向量长度为(5*B+C)*S*S。
Bounding box信息(x,y,w,h)为物体的中心位置相对格子位置的偏移及宽度和高度,这些值均被归一化。换句话说,实际上我们预测的值是一个相对的值。置信度反映是否包含物体以及包含物体情况下位置的准确性,定义为
![]()
其中![]()
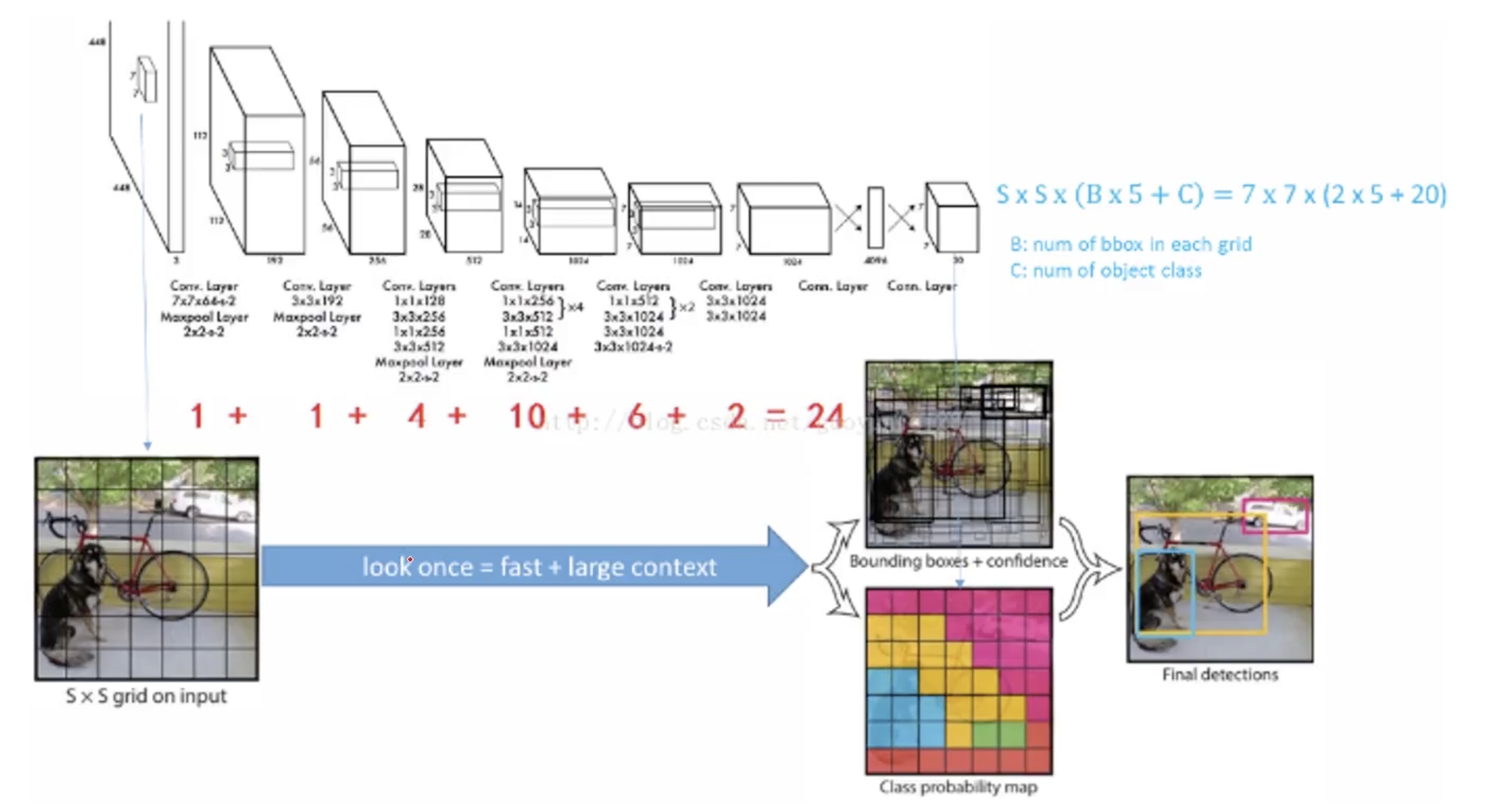
YOLOV1的网络结构图
![]()
YOLO的网络结构采用直接回归的方式来获取到图片中所需要检测到的图片的位置和类别。从上图中我们可以看到,它只包含了CNN的网络结构,从最开始的原始的输入图像,经过多层卷积之后,最终通过一个FC层,最终输出的向量为S*S*(B*5+C)的长度。对于YOLOV1来说,通常S会定义为7*7,B会定义为2,C定义为20,也就是20个类别。通过这样一个回归,我们最终就能够得到对于每一个格子,它所包含的Bounding box的置信度以及是否包含待检测物体。如果包含待检测物体,当前这样一个物体,它的偏移量是多少以及它的长宽是多少,并且我们能够得到相应概率的分布。
通过对FC输出向量的解码,解码之后就能够得到
![]()
这样两幅图,对于第一幅图虽然每个格子预测了很多Bounding box,但是我们只选择IoU最高的Bounding box作为物体检测的输出。也就是说对于每个格子,我们最终只预测当中的一个物体,实际上这也是YOLO算法的一个缺陷。图像中可能会包含多个小的目标,此时由于每个格子只预测一个物体,如果一个格子同时出现多个物体的时候,对于小目标预测效果就会变得非常差。这也是YOLOV1算法主要的一个缺陷。通过NMS来进行Bounding box的合并、筛选和过滤之后,我们就能得到最终的检测结果。
![]()
YOLO算法强调网络使用小卷积,即:1*1和3*3(GoogleNet),能够一方面减少计算量,另一方面减少模型的大小。网络相比VGG16而言,速度会更快,但准确度稍差。
包含了三种Loss,坐标误差 、IoU误差和分类误差。这里每一种Loss也对应到了每一个网格所预测的信息对应的三种Loss。其中坐标误差对应到了S*S*(B*5+C)中的B,也就是Bounding box预测的信息之间的偏差。IoU的Loss对应到了坐标的误差。分类误差对应到了当前的格子所包含的groud true(gt,物体类别)所产生的误差。
![]()
通过对这三种误差的结合,最终通过加权方式进行权重考量来得到最终的loss,通过均方和误差的方式来进行最终的考量用于后续的网络模型的训练。
![]()
对于YOLOV1的具体使用的时候会用到下面一些技巧
首先在网络进行目标检测的时候,会采用预训练模型来对模型的参数进行初步的训练,对模型参数进行初始化。这里采用ImageNet 1000类来对模型进行预训练。对于分类任务和回归任务而言,会存在最后几重的差异。对于分类任务ImageNet 1000类的FC层的输出应该是1000,而YOLOV1的FC层最终输出为S*S*(B*5+C)这样一个值,因此我们在使用预训练模型的时候会去掉后面的几个FC层。
这里实际上采用了预训练模型前20个卷积层,并且用这前20个卷积层来初始化YOLO,用于后续的目标检测任务的训练,如VOC20数据集。由于ImageNet数据的输入图像为224*224,在YOLOV1中会将图像resize到448*448。对于预训练模型,如果我们仅仅是使用了它的卷积层,而卷积层对于feature map的大小实际上是不敏感的,它仅仅关注卷积核的参数(大小和通道数)。但是如果我们复用了FC层,FC层的参数量和我们输入的图像或者feature map的大小是相关的,如果图像的大小发生了变化,会影响到FC层的输入,此时FC层就没办法采用预训练模型来进行训练了。这里由于我们在YOLO预训练的时候只采用了前20个卷积层,去掉了FC层,此时就可以改变图像的大小,并且能够保证预训练模型能继续使用。
在训练B个Bounding box的时候,它的GT(真值)的设置是相同的。
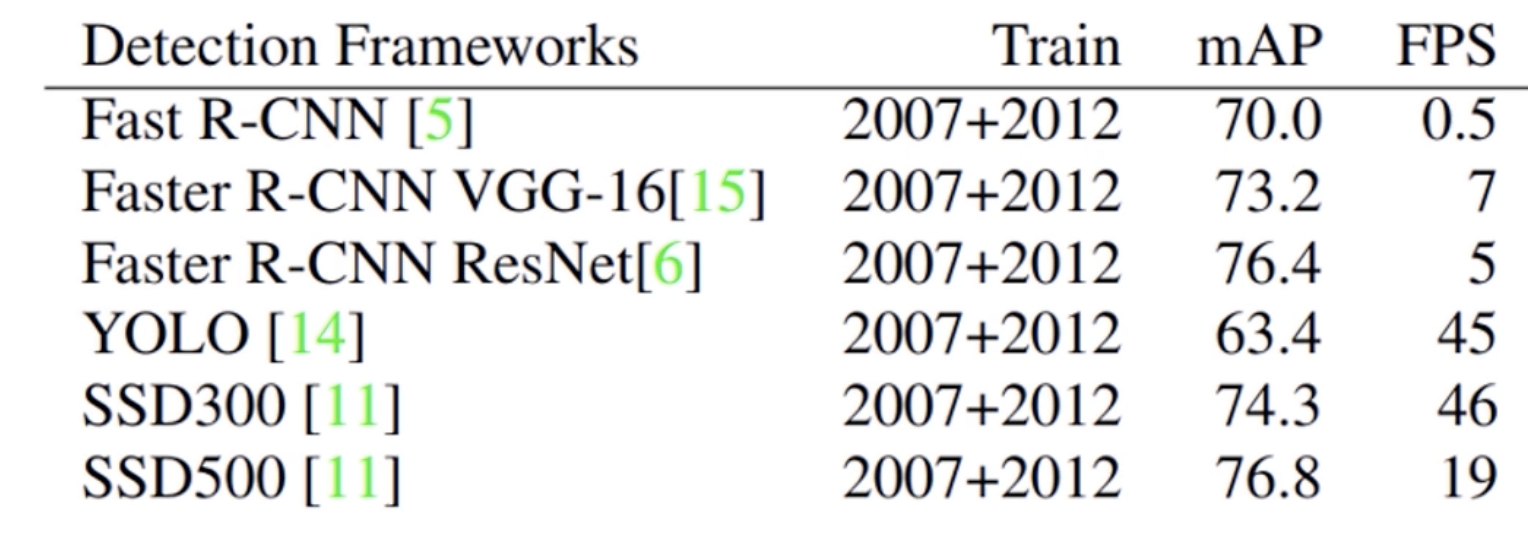
相对于SSD算法和Faster RCNN算法的效果有一定的差距,
- 在进行YOLO最后检测的时候,输入尺寸固定,没有采用多尺度的特征的输入。这是相对SSD算法对6个尺度来进行Prio box的提取以及最终的预测。而YOLO算法是一个完整的卷积网络,没有提取多尺度的feature map。因此YOLOV1算法在特征提取的时候通过多个下采样层学到的最终物体的特征并不精细,因此也会影响到检测的效果。
- YOLOV1在进行小目标检测的时候效果差。在同一个格子中包含多个目标时,仅预测一个目标(IoU最高),会忽略掉其他目标,此时就必然会有漏检的情况产生。
- 在YOLOV1的损失函数中关于IoU的loss,实际上并没有去区分大物体的IoU和小物体IoU的误差对于网络训练loss贡献值的影响。这里它们的贡献值基本上是接近的,实际上对于小物体而言,小物体的IoU的误差会对网络优化造成更大的影响,进而降低物体检测定位的准确性。因此YOLOV1算法在loss设计上也没有特别多的技巧,这也是后续YOLO算法的改进点。
- 如果同一个物体出现新的不常见的长宽比和一些其他情况的时候,YOLOV1算法的泛化能力也较差。
![]()
上图是不同尺度训练的精度与其他网络的精度对比,我们不难发现YOLOV1在相同的数据集中,他的mAP(精度)下降了很多。但是在检测速度上,如果只考虑相同尺度的条件下(448*448),YOLO算法能够达到45FPS,相对于Faster RCNN而言,检测速度是非常快的。相比于SSD500(即图像尺寸500*500)的速度也是非常快的,相比于SSD300(图像尺寸300*300)的速度是非常接近的。也就是说YOLOV1在较大尺寸上的图像检测速度能够保持跟SSD较小图像检测速度相同的检测速度。
YOLOV2
基于YOLOV1存在的问题,作者在2017年提出了YOLOV2的算法,并基于YOLOV2提出了YOLO9000这样两种模型。YOLOV2相对于YOLOV1改进的几个核心的点在于
- 引入了Anchor box的思想,改进直接回归这样一种比较粗糙的方式
- 在输出层使用卷积层替代YOLOV1的全连接层(FC层),能够带来一个比较直观的好处就是能够减少对于输入图像尺寸的敏感程度。因为FC层的参数量同图像大小是息息相关的,而卷积层同图像大小是不存在关联的。
- 对于YOLO9000而言,在最终训练的时候,实际上是采用了ImageNet物体分类以及coco物体检测这样的两种数据集来对模型进行训练。用检测中的数据集中的数据来学习物体的准确的位置信息。用分类数据集来学习分类的信息。通过这种多任务来提高最终网络的鲁棒性。
- 相比于YOLOV1而言,YOLOV2不仅在识别物体的种类上,以及精度、速度、和物体的定位上都得到了大大的提升。
YOLOV2算法成为了当时最具有代表性的目标检测算法的一种,YOLOV2/YOLO9000的改进之处:
![]()
在上图中,我们可以看到主干网络采用了DarkNet的网络结构,在YOLOV1算法中,作者采用了GoogleNet这样一种架构来作为主干网络,它的性能要优于VGGNet的。DarkNet类似于VGGNet,采用了小的3*3的卷积核,在每次池化之后,整个通道的数量都会增加一倍,并且在网络结构中采用Batch Normalization来进行归一化处理,进而让整个训练过程变得更加的稳定,收敛速度变得更快,达到模型规范化的效果。
由于使用卷积层来代替FC层,因此输入的图像尺寸就可以发生变化,因而整个网络的参数同feature map的大小是无关的。因此我们可以改变图像的尺寸来进行多尺度的训练。对于分类模型采用了高分辨率的分类器。
YOLOV1算法只采用了一个维度上的特征,因此它学到的特征因此相对来说不会太精细,而YOLOV2采用了一个跳连的结构,换句话说在最终的预测的阶段,实际上采用了不同粒度上的特征,通过对不同粒度上特征的融合,来提高最终检测的性能。在最终预测的时候同样采用了Anchor的机制,Anchor机制也是Faster RCNN或者SSD算法一个非常核心重要的元素,这个元素能够带来模型在性能上的提升。
- V1中也大量用了BN,但是在定位层FC层采用了dropout来防止过拟合。
- V2中取消了dropout,在整个网络结构中均采用BN来进行模型的规范化,模型更加稳定,收敛速度更快,
- V1中使用224*224的预训练模型,但是实际上采用了448*448的图像来用于网络检测。这个过程实际上会存在一定的偏差,必然带来分布上的差异,
- V2直接采用448*448的分辨率微调最初的分类网络。保证了分类和检测这样的两个模型在分布上的一致性。
- 在预测Bounding box的偏移,使用卷积代替FC。我们知道在V1中FC层输出的向量的大小为S*S*(B*5+C),而V2中直接采用卷积来代替的话,卷积之后的feature map的大小为S*S,(B*5+C)则对应了通道的数量,此时同样能够达到V1的FC层相同的效果。
- 在V2中输入的图像尺寸为416*416,而不是448*448,主要原因就在于图片中的物体倾向于出现在图片的中心位置,特别是比较大的物体,因此就需要有一个单独位于物体中心的位置用来预测这个物体。而YOLO通过卷积层之后,会进行32倍的下采样。对于416*416的图像,下采样32倍之后就会得到一个13*13的feature map。对于448*448的图像进行32倍下采样之后得到一个14*14的feature map,此时就不存在这样一个网格位于图像的正中心。为了保证feature map必然会存在一个网格位于图像的正中心,此时我们只需要将经过下采样之后的feature map的大小定义为13*13,就能保证一定会存在中心的一个Cell,能够预测位于中心的物体。因此我们要保证最终得到的feature map的大小为13*13,反推过来,进行32倍的上采样,就能够得到输入的尺寸为416。这也是为了后面产生的卷积图的宽高比为奇数,就能产生一个中心的Cell。主要原因是作者通过观察发现大物体通常占据图像的中间位置,就需要一个位于中间的Cell来预测位于中间的物体的位置。如果不采用奇数的长宽的话,就需要用到中间的4个Cell来预测中间的物体。通过奇数输出的技巧就能够提高总体的效率。
- V2加入了Anchor机制之后,对于每一个Cell,会预测多个建议框。相比于之前的网络仅仅预测B个(B通常为2)建议框而言,采用Anchor Box之后,结果的召回率得到了显著的提升。但是mAP却有了一点点的下降。在作者看来准确率只有小幅度的下降,但是召回率提高了非常大,这也反映了Anchor Box确实能够在一定程度上带来整个模型性能上的提升。当然我们也需要去进一步优化准确度下降的缺陷,在V2中采用了max pooling的方法来进行下采样。
- 加入了Anchor机制之后,整个Bounding box的预测数量超过了1000个。比如说经过下采样之后的feature map为13*13的话,每个Anchor需要预测9个Bounding box的话,那么整个feature map需要预测13*13*9=1521个Bounding box。相比于之前的7*7*2=98个而言,整体需要预测的框的数量就得到了提高。进而也会带来模型在性能上的提高。但是作者在使用Anchor Box之后也遇到了两个问题,一个是对于Anchor Box而言,它的宽高维度往往是精选先验框,虽然在训练的过程中网络也会调整Box的宽高维度,最终得到准确的Bounding box的位置,但是作者希望在最开始选择的时候就选择那些最具代表性的先验的Bounding box的维度,这样就能够通过网络更容易的学习到准确的预测的位置。因此作者采用了K-means方法来对Bounding box进行回归,自动找到那些更好的Bounding box的宽高维度比。在使用K-means方法来对Bounding box聚类的时候,同样作者也遇到了一个问题,就是传统的K-means方法来进行Bounding box聚类的时候,主要采用欧式距离的方法来度量两个Bounding box之间的相似度,这样也就意味着较大的Bounding box会比较小的Bounding box产生更多的误差,因此作者在训练的时候就采用了IoU得分作为距离的度量。此时所得到的误差也就和Bounding box的尺寸无关了。经过聚类之后,作者也确定了预测的Anchor Box数量为5的时候比较合适。作者最终选择了5种大小的Bounding box的维度来进行定位预测。在这样一个聚类的结果中,作者也发现扁长的框较少,而瘦高的框会较多一点,这实际上也符合了行人的特征。有关K-means聚类的内容可以参考聚类 。