作者介绍
侯阳
SphereEx 中间件研发工程师,Apache ShardingSphere Contributor。
目前专注于 ShadowDB 及全链路压测相关的设计和研发。
什么是全链路压测
随着互联网行业的快速发展,业务也进入了快速扩张阶段,多变的用户需求对整个系统的稳定性冲击可想而知。比如外卖平台大量用户产生的订单集中分布在中午和傍晚两个时间段,再比如电商平台的购物节、秒杀活动等。
每种业务都由一系列不同的业务系统来提供服务,每个业务系统都分布式地部署在不同的机器上。“流量规划” 既能保障系统稳定性、又能节约成本对于技术团队来说是一重大难题,为了精准地获取到单台机器的服务能力,压力测试要在生产环境进行。既能保证环境的真实性,也能保证流量的真实性,大大提高“流量规划”的准确性。
影子库与全链路压测
但在线上业务系统做压测,风险不言而喻,比如数据污染问题或是性能问题。试想一下,如果压测结束后用户发现自己订单丢失了或是凭空多出一批待支付的订单,是否极大影响用户体验?
全链路在线压测是一项复杂而庞大的工作,需要各个微服务、中间件之间配合完成。Apache ShardingSphere 关注于全链路在线压测场景下数据库层面的解决方案,推出压测影子库功能。借助于 ShardingSphere 强大的 SQL 解析能力,对执行 SQL 进行影子判定,同时结合影子算法灵活的配置,满足复杂业务场景的在线压测需求;压测流量路由到影子库,线上正常流量路由到生产库,从而帮助用户对压测数据进行隔离,解决数据污染问题。
影子库功能升级
影子库功能最早实现于 v4.1.0 时期,通过添加一个逻辑的影子列,Apache ShardingSphere 通过解析执行 SQL,对其进行路由并改写,删除逻辑的影子列与列值。用户无需关注具体过程,使用时仅对 SQL 进行相应改造,添加影子字段与相应的配置即可。
添加影子列的方式有两个痛点:
-
用户在进行压力测试前需要根据实际的业务需求,对压测相关 SQL 进行相应改造。
-
SQL 改写操作会增加执行损毁,降低压测结果的准确性。
经过 ShardingSphere 社区的讨论,决定对影子库功能进行重构。
Apache ShardingSphere 4.1.1 GA 版影子库 API,总体上功能较为简单,根据逻辑列对应的值判断是否开启影子库。
rules:
- !SHADOW
column: # 影子字段名称名称
shadowMappings:
ds: shadow_ds # 生产数据源名称列表:影子数据库名称列表
5.0.0 GA 重构以后的影子库 API 更加强大。 用户可以通过 enable 属性控制是否开启影子库功能,可配置影子表可以按照表的维度控制需要进行压测的范围,并支持多种不同的影子算法,例如:列值匹配算法、列正则表达式匹配算法以及 SQL 注释匹配算法。
rules:
- !SHADOW
enable: true # 影子库开关。 可选值:true/false,默认为false
dataSources:
shadowDataSource:
sourceDataSourceName: ds # 生产数据源名称
shadowDataSourceName: shadow_ds # 影子数据源名称
tables:
<shadow-table-name>:
dataSourceNames: shadowDataSource # 影子表关联影子数据源名称列表(多个值用","隔开)
shadowAlgorithmNames:
- <shadow-algorithm-name> # 影子表关联影子算法名称列表
shadowAlgorithms:
<shadow-algorithm-name>:
type: # 影子算法类型
props:
xxx: xxx # 影子算法属性配置
影子库实战
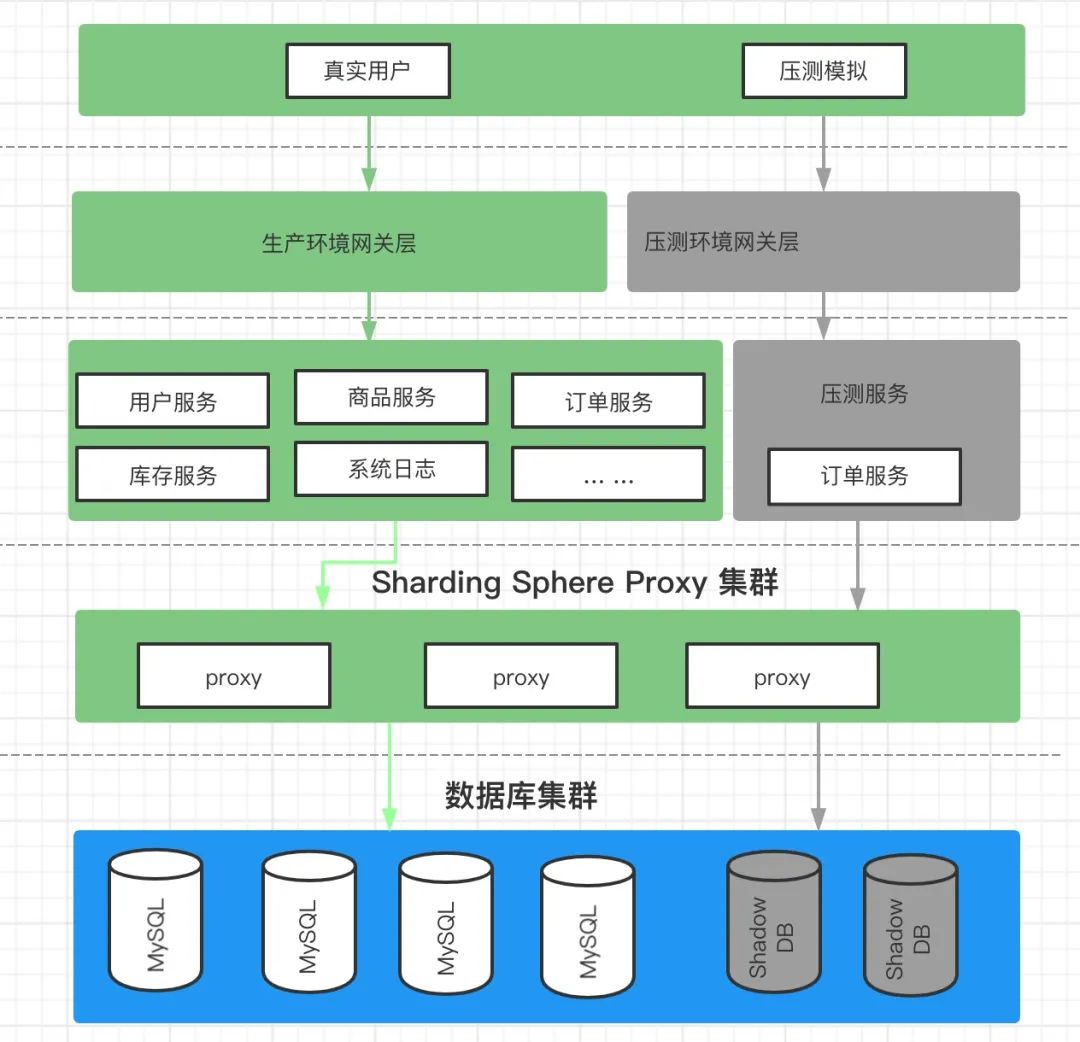
在线全链路压测架构图:
![]()
准备压测环境
假设一个电商网站要对下单业务进行在线压测。(演示使用单机部署方式)
假设压测相关表 t_order 订单表,测试用户的 ID 为 0。测试用户下单产生的数据执行到 ds_shadow 影子库,生产数据执行到 ds 生产数据库。
测试环境准备:
-
下载 ShardingSphere-Proxy 5.0.0 GA Download Page,安装配置详情参考ShardingSphere-Proxy-Quick-Start
-
配置 ShardingSphere-Proxy 以上文假设压测场景为例:
server.yaml
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: NATIVE
- !TRANSACTION
defaultType: XA
providerType: Atomikos
props:
max-connections-size-per-query: 1
executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
proxy-opentracing-enabled: false
proxy-hint-enabled: false
sql-show: true
check-table-metadata-enabled: false
lock-wait-timeout-milliseconds: 50000 # The maximum time to wait for a lock
show-process-list-enabled: false
# Proxy backend query fetch size. A larger value may increase the memory usage of ShardingSphere Proxy.
# The default value is -1, which means set the minimum value for different JDBC drivers.
proxy-backend-query-fetch-size: -1
check-duplicate-table-enabled: false
sql-comment-parse-enabled: true
proxy-frontend-executor-size: 0 # Proxy frontend executor size. The default value is 0, which means let Netty decide.
# Available options of proxy backend executor suitable: OLAP(default), OLTP. The OLTP option may reduce time cost of writing packets to client, but it may increase the latency of SQL execution
# if client connections are more than proxy-frontend-netty-executor-size, especially executing slow SQL.
proxy-backend-executor-suitable: OLAP
config-shadow.yaml
schemaName: shadow_poc_database
dataSources:
ds:
url: jdbc:mysql://127.0.0.1:3306/ds?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
ds_shadow:
url: jdbc:mysql://127.0.0.1:3306/ds_shadow?serverTimezone=UTC&useSSL=false
username: root
password:
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
rules:
- !SHADOW
enable: true
dataSources:
shadowDataSource:
sourceDataSourceName: ds
shadowDataSourceName: ds_shadow
tables:
t_order:
dataSourceNames:
- shadowDataSource
shadowAlgorithmNames:
- user-id-insert-match-algorithm
- simple-note-algorithm
shadowAlgorithms:
user-id-insert-match-algorithm:
type: COLUMN_REGEX_MATCH
props:
operation: insert
column: user_id
regex: "[0]"
simple-note-algorithm:
type: SIMPLE_NOTE
props:
foo: bar
- 订单服务
这里不讨论订单相关业务,以最简单的收请求直接插入订单表为例。订单表结构如下:
CREATE TABLE `t_order` (
`id` INT(11) AUTO_INCREMENT COMMENT '订单ID',
`user_id` VARCHAR(32) NOT NULL COMMENT '下单用户ID',
`sku` VARCHAR(32) NOT NULL COMMENT '订单商品sku',
PRIMARY KEY (`id`)
)ENGINE = InnoDB COMMENT = '订单表';
模拟压测过程
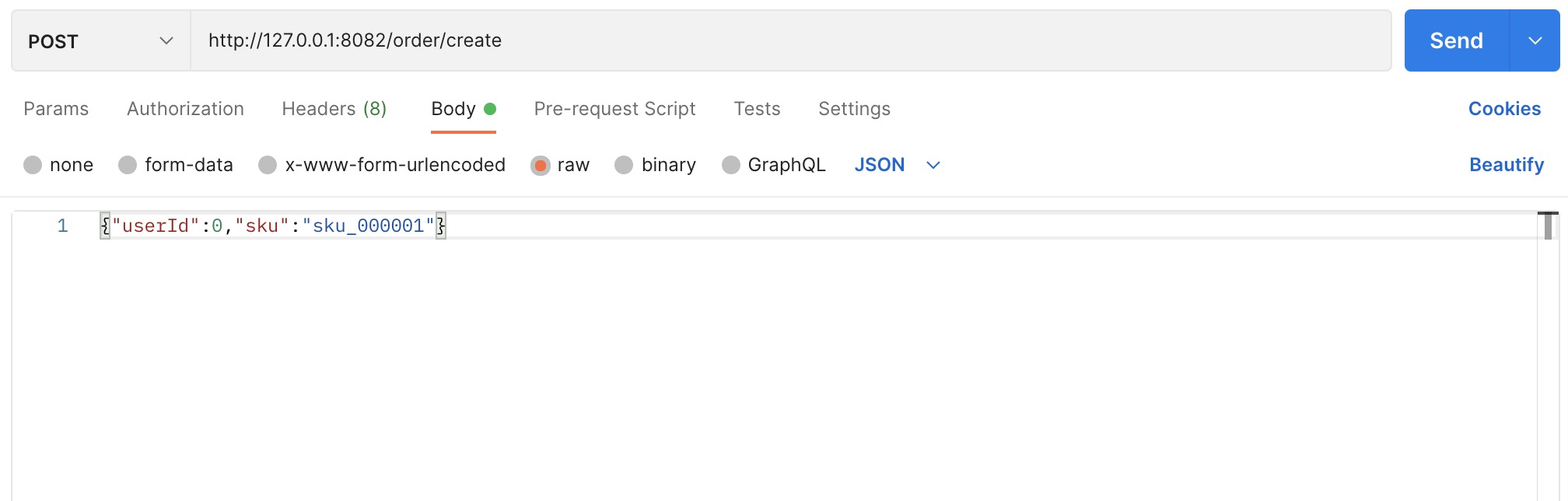
- 使用
postman 模拟测试用户创建订单请求如下图:
![]()
- ShardingSphere-Proxy 中执行日志可以看到 执行 SQL 被路由到影子库执行
![]()
验证压测结果
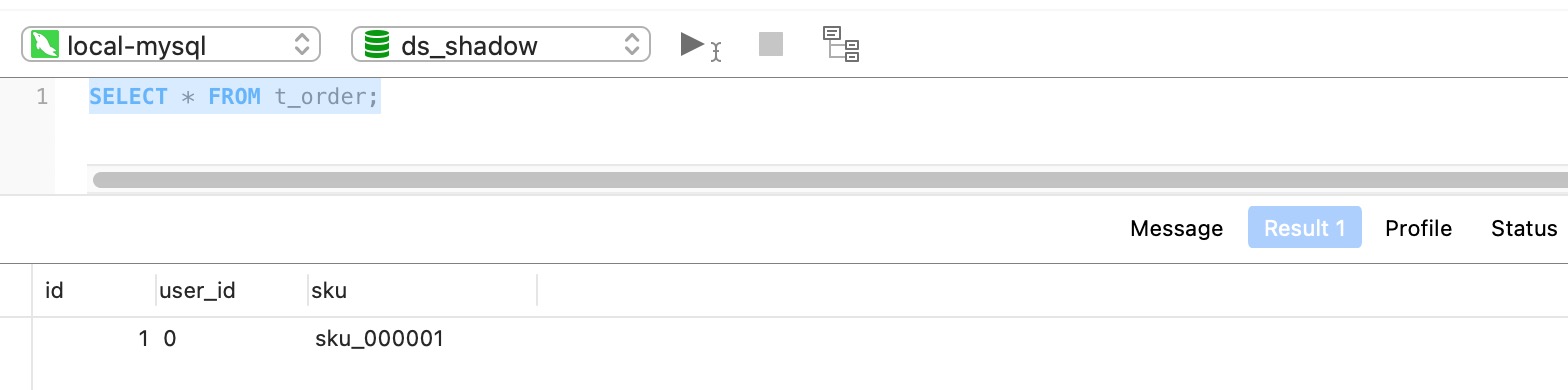
SELECT * FROM t_order;
查询结果:
![]()
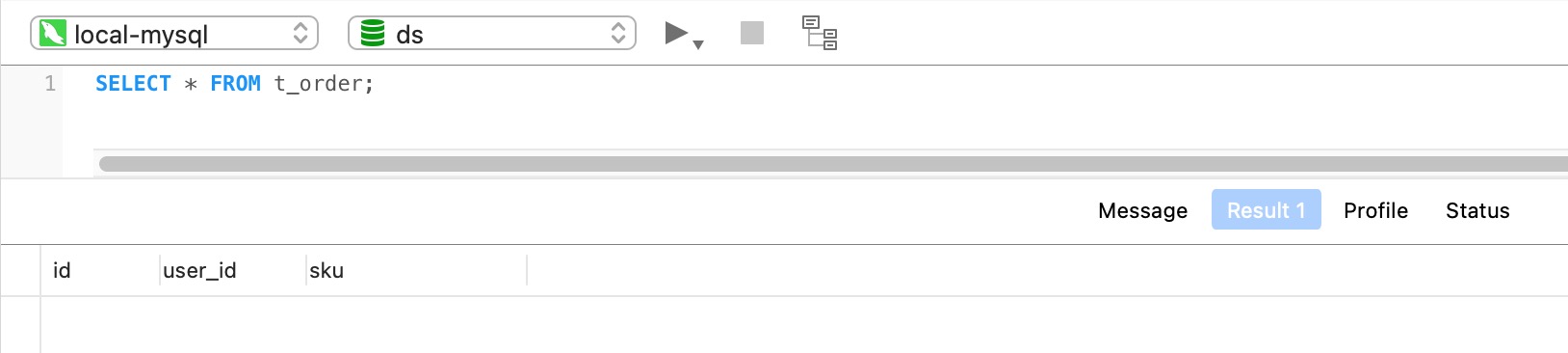
SELECT * FROM t_order;
查询结果:
![]()
测试用户创建订单产生的数据会路由到影子库中。更多复杂配置请参考 ShardingSphere 官方文档影子库压测。
全链路在线压测完整解决方案-CyborgFlow
前文中也提到全链路在线压测是一项复杂而庞大的工作,需要各个微服务、中间件之间配合与调整,以应对不同流量以及压测标识的透传,而且要做到测试服务无状态并且开箱即用。
由 Apache ShardingSphere 联合 Apache APISIX、Apache SkyWalking 共同维护的项目 CyborgFlow 提供开箱即用 (OOTB) 解决方案来在您的在线系统上执行负载测试。
Apache APISIX 负责在网关层对测试数据进行标记,并由 Apache SkyWalking 负责在整个调用链路上进行传递,最后交由 Apache ShardingSphere-Proxy 做数据隔离,压测数据路由到影子库中。
项目已发布 0.1.0 版本,欢迎下载使用: https://github.com/SphereEx/CyborgFlow/releases
欢迎添加社区经理微信(ss_assistant_1)加入微信交流群,与更多 ShardingSphere 爱好者一同交流讨论。
![]()