![]()
好消息!Apache DolphinScheduler 2.0.1 版本今日正式发布!
本版本中,DolphinScheduler 经历了一场微内核+插件化的架构改进,70% 的代码被重构,一直以来备受期待的插件化功能也得到重要优化。此外,本次升级还有不少亮点,如一键升级至最新版本、注册中心“去 ZK 化”、新增任务参数传递功能等。
Apache DolphinScheduler 2.0.1 下载地址:
https://dolphinscheduler.apache.org/zh-cn/download/download.html
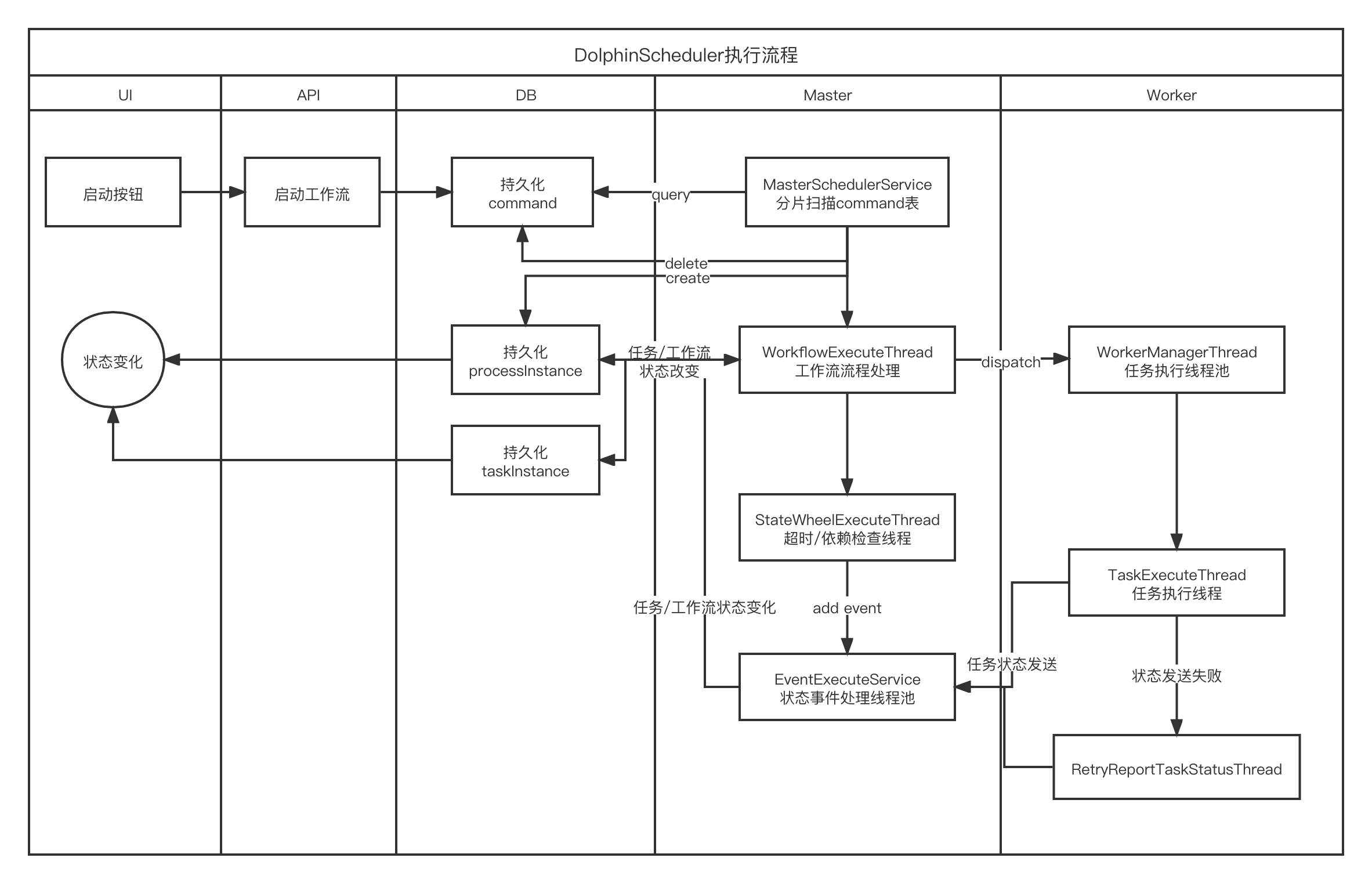
Apache DolphinScheduler 2.0.1 的工作流执行流程活动如下图所示:
![]()
启动流程活动图
2.0.1 版本通过优化内核增强了系统处理能力,从而在性能上得到较大提升,全新的 UI 界面也极大地提升了用户体验。更重要的是,2.0.1 版本还有两个重大变化:插件化和重构。
01 插件化
此前,有不少用户反馈希望 Apache DolphinScheduler 可以优化插件化,为响应用户需求,Apache DolphinScheduler 2.0.1 在插件化上更进了一步,新增了告警插件、注册中心插件和任务插件管理功能。利用插件化,用户可以更加灵活地实现自己的功能需求,更加简单地根据接口自定义开发任务组件,也可以无缝迁移用户的任务组件至 DolphinScheduler 更高版本中。
DolphinScheduler 正在处于微内核 + 插件化的架构改进之中,所有核心能力如任务、告警组件、数据源、资源存储、注册中心等都将被设计为扩展点,我们希望通过 SPI 来提高 Apache DolphinScheduler 本身的灵活性和友好性。
相关代码可以参考 dolphinscheduler-spi 模块,相关插件的扩展接口也皆在该模块下。用户需要实现相关功能插件化时,建议先阅读此模块代码。当然,也建议大家阅读文档以节省时间。
我们采用了一款优秀的前端组件 form-create,它支持基于 json 生成前端 UI 组件,如果插件开发涉及到前端,我们会通过 json 来生成相关前端 UI 组件。
org.apache.dolphinscheduler.spi.params 里对插件的参数做了封装,它会将相关参数全部转化为对应的 json。这意味着,你完全可以通过 Java 代码的方式完成前端组件的绘制(这里主要是表单)。
1 告警插件
以告警插件为例,我们实现了在 alert-server 启动时加载相关插件。alert 提供了多种插件配置方法,目前已经内置了 Email、DingTalk、EnterpriseWeChat、Script 等告警插件。当插件模块开发工作完成后,通过简单的配置即可启用。
2 多注册中心组件
在 Apache DolphinScheduler 1.X 中,Zookeeper 组件有着非常重要的意义,包括 master/worker 服务的监控发现、失联告警、通知容错等功能。在 2.0.1 版本中,我们在注册中心逐渐“去 ZK 化”,弱化了 Zookeeper 的作用,新增了插件管理功能。
在插件管理中,用户可以增加 ETCD 等注册中心的支持,使得 Apache Dolphinscheduler 的灵活性更高,能适应更复杂的用户需求。
3 任务组件插件
新版本还新增了任务插件功能,增强了不同的任务组件的隔离功能。用户开发自定义插件时,只需要实现插件的接口即可。主要包含创建任务(任务初始化、任务运行等方法)和任务取消。
如果是 Yarn 任务,则需要实现 AbstractYarnTask。目前,任务插件的前端需要开发者自己使用 Vue 开发部署,在后续版本中,我们将实现由 Java 代码的方式完成前端组件的自动绘制。
重构
迄今为止,Apache DolphinScheduler 已经重构了约 70% 的代码,实现了全面的升级。
1. Master 内核优化
2.0.1 版本升级包括重构了 Master 的执行流程,将之前状态轮询监控改为事件通知机制,大幅减轻了数据库的轮询压力;去掉全局锁,增加了 Master 的分片处理机制,将顺序读写命令改为并行处理,增强了 Master 横向扩展能力;优化工作流处理流程,减少了线程池的使用,大幅提升单个 Master 处理的工作流数量;增加缓存机制,优化数据库连接方式,以及简化处理流程,减少处理过程中不必要的耗时操作等。
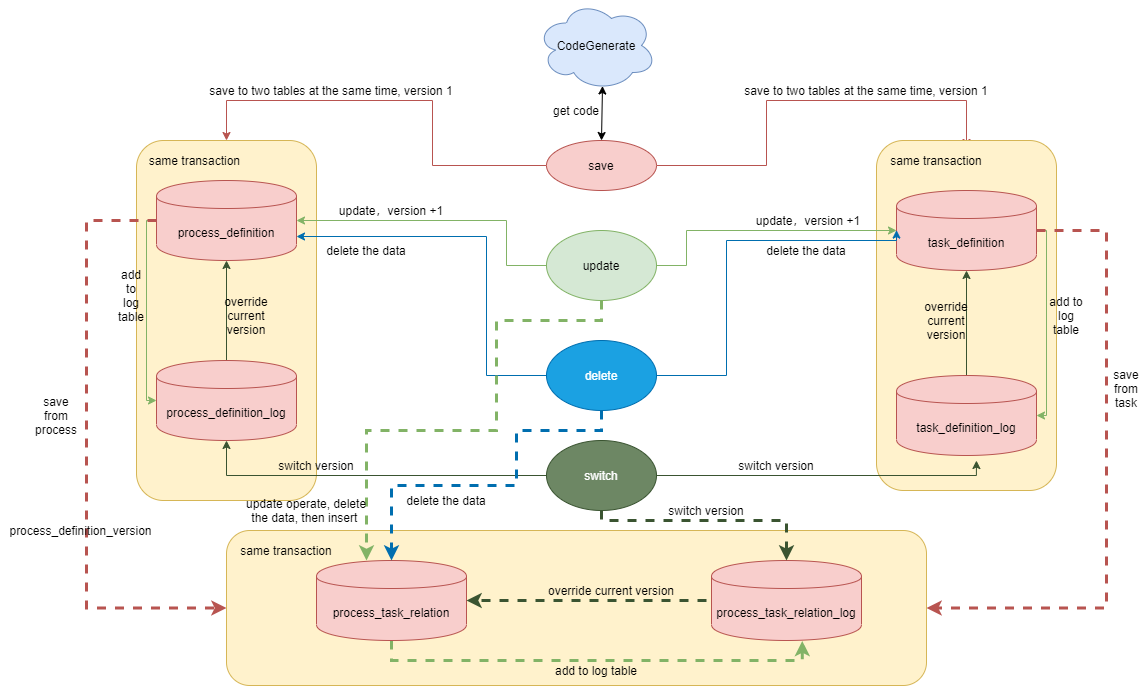
2. 工作流和任务解耦
在 Apache DolphinScheduler 1.x 版本中,任务及任务关系保存是以大 json 的方式保存到工作流定义表中的,如果某个工作流很大,比如达到 100 至 1000 个任务规模,这个 json 字段会非常大,在使用时需要解析 json。这个过程比较耗费性能,且任务无法重用;另一方面,基于大 json,在工作流版本及任务版本上也没有很好的实现方案。
因此,在新版本中,我们针对工作流和任务做了解耦,新增了任务和工作流的关系表,并新增了日志表,用来保存工作流定义和任务定义的历史版本,大幅提高工作流运行的效率。
下图为 API 模块下工作流和任务的操作流程图:
![]()
版本自动升级功能
2.0.1 增加了版本自动升级功能,用户可以从 1.x 版本自动升级到 2.0.1 版本。只需要运行一个使用脚本,即可无感知地使用新版本运行以前的工作流:
sh ./script/create-dolphinscheduler.sh
具体升级文档请参考:https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/upgrade.html
另外,Apache DolphinScheduler 将来的版本均可实现自动升级,省去手动升级的麻烦。
新功能列表
Apache DolphinScheduler 2.0.1 新增功能详情如下:
1. 新增 Standalone 服务
StandAloneServer 是为了让用户快速体验产品而创建的服务,其中内置了注册中心和数据库 H2-DataBase、Zk-TestServer,在修改后一键启动 StandAloneServer 即可进行调试。
如果想快速体验,在解压安装包后,用户只需要配置 jdk 环境等即可一键启动 Apache DolphinScheduler 系统,从而减少配置成本,提高研发效率。
详细的使用文档请参考:https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/installation/standalone.html
或者使用 Docker 一键部署所有的服务:https://dolphinscheduler.apache.org/zh-cn/docs/latest/user_doc/guide/installation/docker.html
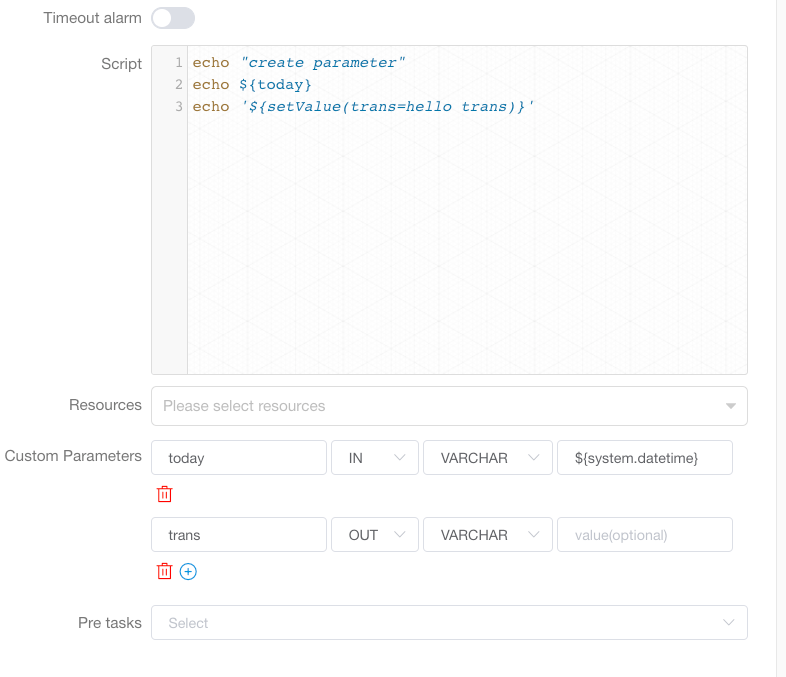
2 任务参数传递功能
目前支持 shell 任务和 sql 任务之间的传递。
在前一个"create_parameter"任务中设置一个out的变量”trans“: echo '${setValue(trans=hello trans)}'
![]()
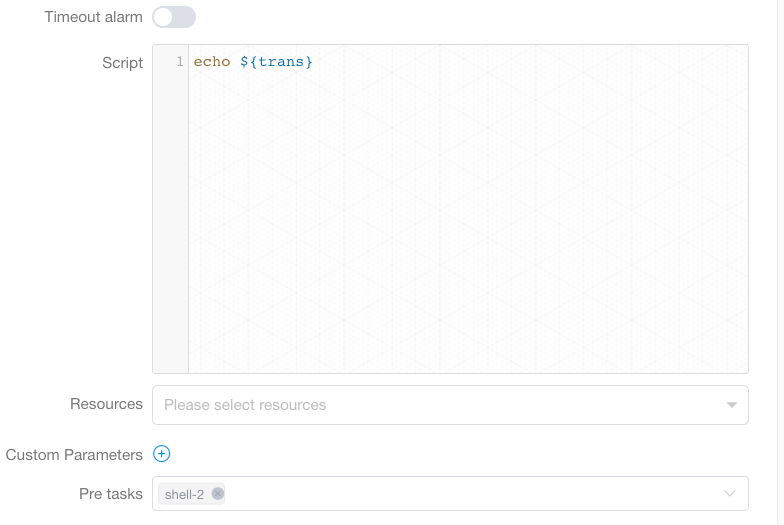
当前置任务中的任务日志中检测到关键字:”${setValue(key=value)}“, 系统会自动解析变量传递值,在后置任务中,可以直接使用”trans“变量:
![]()
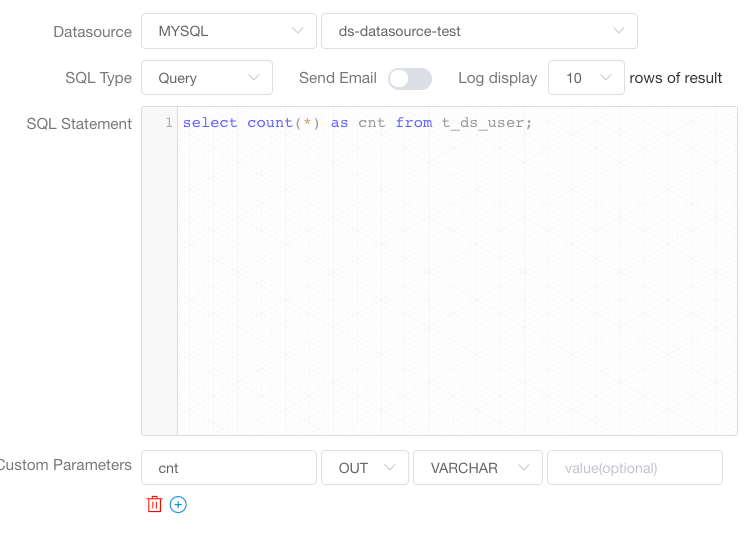
SQL 任务的自定义变量 prop 的名字需要和字段名称一致,变量会选择 SQL 查询结果中的列名中与该变量名称相同的列对应的值。输出用户数量:
![]()
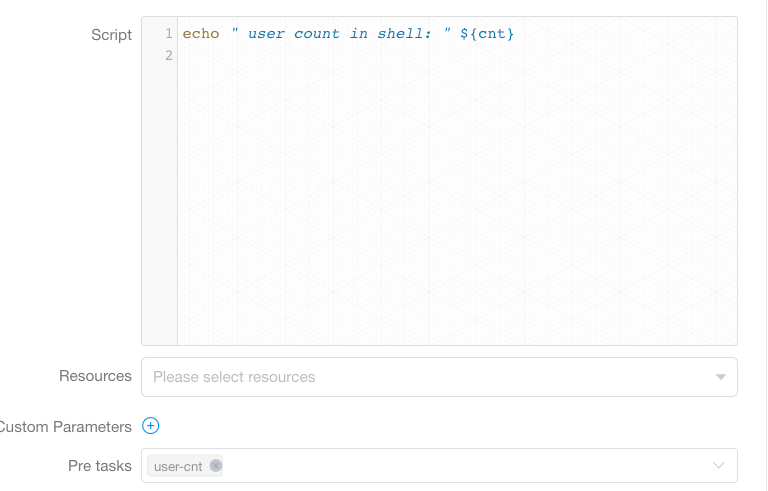
在下游任务中使用变量”cnt“:
![]()
新增 switch 任务和 pigeon 任务组件:
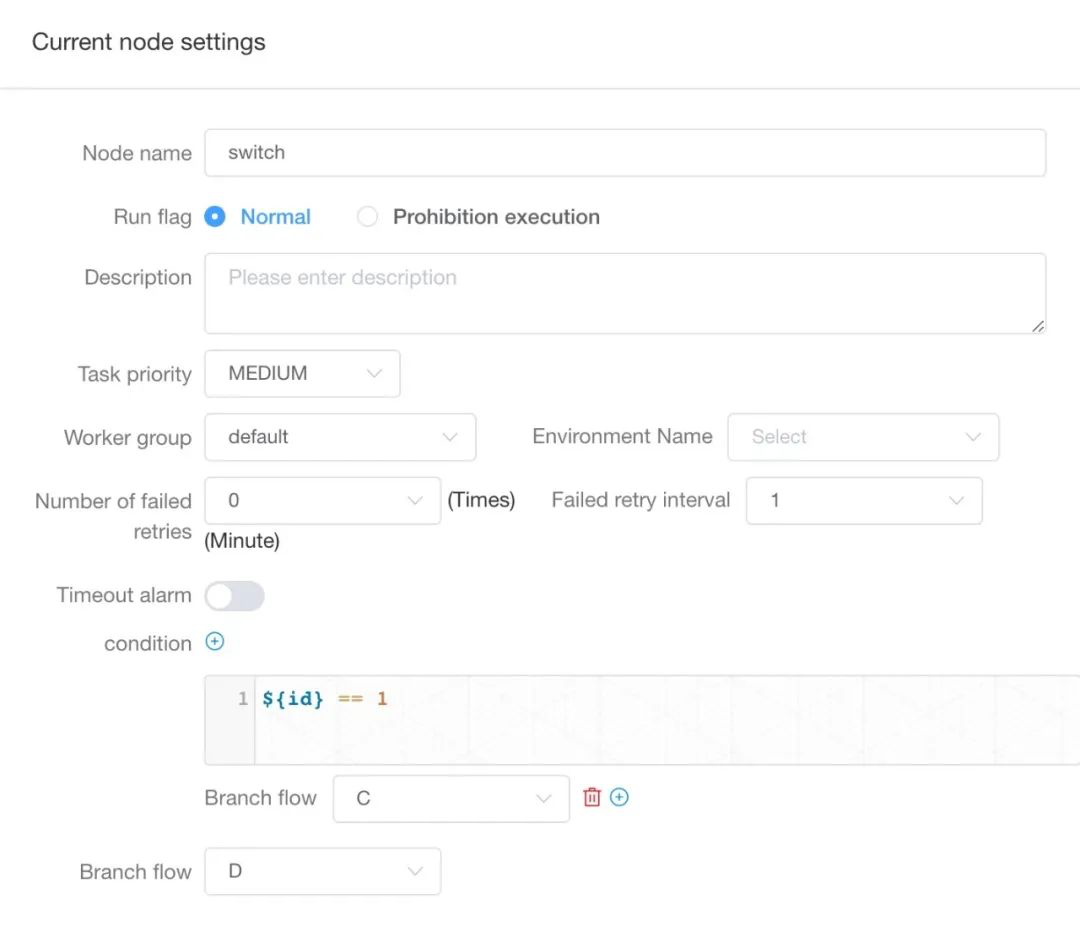
在 switch 任务中设置判断条件,可以实现根据不同的条件判断结果运行不同的条件分支的效果。例如:有三个任务,其依赖关系是 A -> B -> [C, D] ,其中 task_a是 shell 任务,task_b 是 switch 任务。
任务 A 中通过全局变量定义了名为 id 的全局变量,声明方式为echo '${setValue(id=1)}'。
任务 B 增加条件,使用上游声明的全局变量实现条件判断(注意 Switch 运行时存在的全局变量就行,意味着可以是非直接上游产生的全局变量)。下面我们想要实现当 id 为 1 时,运行任务 C,其他运行任务 D。
配置当全局变量 id=1 时,运行任务 C。则在任务 B 的条件中编辑 ${id} == 1,分支流转选择 C。对于其他任务,在分支流转中选择 D。
![]()
pigeon 任务,是一个可以和第三方系统对接的一种任务组件,可以实现触发任务执行、取消任务执行、获取任务状态,以及获取任务日志等功能。pigeon 任务需要在配置文件中配置上述任务操作的 API 地址,以及对应的接口参数。在任务组件里输入一个目标任务名称,即可对接第三方系统,实现在 Apache DolphinScheduler 中操作第三方系统的任务。
3 新增环境管理功能
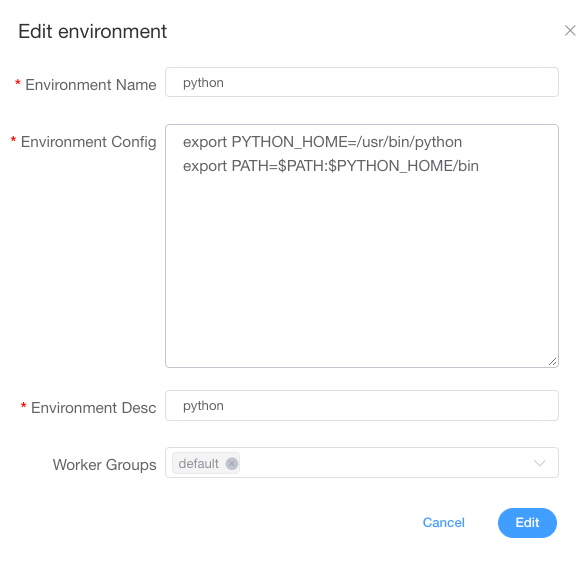
默认环境配置为 dolphinscheduler_env.sh。
在线配置 Worker 运行环境,一个 Worker 可以指定多个环境,每个环境等价于 dolphinscheduler_env.sh 文件。
![]()
在创建任务的时候,选择 worker 分组和对应的环境变量,任务在执行时,worker 会在对应的执行环境中执行任务。
优化项
1. 优化 RestApi
我们更新了新的 RestApi 规范,并且按照规范,重新优化了 API 部分,使得用户在使用 API 时更加简单。
2. 优化工作流版本管理
优化了工作流版本管理功能,增加了工作流和任务的历史版本。
3. 优化 worker 分组管理功能
在 2.0 版本中,我们新增了 worker 分组管理功能,用户可以通过页面配置来修改 worker 所属的分组信息,无需到服务器上修改配置文件并重启 worker,使用更加便捷。
优化 worker 分组管理功能后,每个 worker 节点都会归属于自己的 Worker 分组,默认分组为 default。在任务执行时,可以将任务分配给指定 worker 分组,最终由该组中的 worker 节点执行该任务。
修改 worker 分组有两种方法:
-
打开要设置分组的 worker 节点上的"conf/worker.properties"配置文件,修改 worker.groups 参数。
-
可以在运行中修改 worker 所属的 worker 分组,如果修改成功,worker 就会使用这个新建的分组,忽略 worker.properties 中的配置。修改步骤为"安全中心 -> worker 分组管理 -> 点击 '新建 worker 分组' -> 输入'组名称' -> 选择已有 worker -> 点击'提交'"
其他优化事项:
-
增加了启动工作流的时候,可以修改启动参数;
-
新增了保存工作流时,自动上线工作流状态;
-
优化了 API 返回结果,加快了创建工作流时页面的加载速度;
-
加快工作流实例页面的加载速度;
-
优化工作流关系页面的显示信息;
-
优化了导入导出功能,支持跨系统导入导出工作流;
-
优化了一些 API 的操作,如增加了若干接口方法,增加任务删除检查等。
变更日志
另外Apache DolphinScheduler 2.0.1 也修复了一些 bug,主要包括:
-
修复了 netty 客户端会创建多个管道的问题;
-
修复了导入工作流定义错误的问题;
-
修复了任务编码会重复获取的问题;
-
修复使用 Kerberos 时,Hive 数据源连接失败的问题;
-
修复 Standalone 服务启动失败问题;
-
修复告警组显示故障的问题;
-
修复文件上传异常的问题;
-
修复 Switch 任务运行失败的问题;
-
修复工作流超时策略失效的问题;
-
修复 sql 任务不能发送邮件的问题。
致谢
感谢 289 位参与 2.0.1 版本优化和改进的社区贡献者(排名不分先后)!
![]()
![]()
加入社区
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。
参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:
![]()
贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
- 社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
- 进阶问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
- 如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/docs/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的!