
开源 | dl_inference更新:增加TensorRT、MKL集成,提高深度学习模型推理速度

背 景
dl_inference是58同城推出的通用深度学习推理服务,可在生产环境中快速上线由TensorFlow、PyTorch、Caffe等框架训练出来的深度学习模型。dl_inference于2020年3月26号发布,可参见《开源|dl_inference:通用深度学习推理服务》。
我们在2021年11月对dl_inference再次进行更新,从发布至今新增如下Features:
1、集成TensorRT加速深度学习推理,支持将TensorFlow-SavedModel模型、PyTorch-Pth模型进行自动优化,转换为TensorRT模型后部署,提高模型在GPU上的推理速度。
2、集成Intel Math Kernel Library库的TensorFlow Serving推理框架,加速TensorFlow模型CPU上推理。
3、支持Caffe模型推理,提供丰富的模型应用示例。
使用TensorRT加速深度学习推理
-
权重与激活精度校准:支持将模型量化为FP16/INT8精度,提高吞吐量的同时保持高准确度。 -
层与张量融合:TensorRT可以做计算图优化,通过kernel融合,减少数据拷贝等手段,生成网络的优化计算图。 -
内核自动调整:TensorRT可以自动选取最优kernel。同样是矩阵乘法,在不同GPU架构上以及不同矩阵大小,最优的GPU kernel的实现方式不同,TensorRT可以把它优选出来。 -
动态张量显存:更大限度减少显存占用,高效地为张量重复利用显存。 -
多流执行:并行处理多个输入流的可扩展设计。
开发者提供TensorFlow训练好的SavedModel.pb或PyTorch训练好的Model.pth模型文件,dl_inference会先将其转换为ONNX(Open Neural Network Exchange)格式模型,ONNX是一种针对机器学习所设计的开放式文件格式,用于存储训练好的模型,它使得不同的深度学习框架可以在相同格式存储模型数据并交互,然后dl_inference再将ONNX模型文件自动进行优化,转换得到TensorRT格式模型。开发者除了要提前准备好模型文件外还需提供模型元数据描述文件config.txt,TensorFlow SavedModel.pb模型元数据可由saved_model_cli 命令工具查看,PyTorch pth模型由于没有name概念,可设置为单字母名称,如 i, o等,表示inputs,outputs。以Resnet50(dl_inference/DLPredictOnline/demo/model/tis)为例模型元数据描述文件config.txt如下:
{"batch_size":0,"input":[{"name":"image","data_type":"float","dims":[-1,224,224,3],"node_name":"input_1:0"}],"output":[{"name":"probs","data_type":"float","dims":[-1,19],"node_name":"dense_1/Softmax:0"}]}
cd DockerImagedocker build -t tis-model-convert:lastest .
cd $模型所在路径docker run -v `pwd`:/workspace/source_model -e SOURCE_MODEL_PATH=/workspace/source_model -e TARGET_MODEL_PATH=/workspace/source_model -e MODEL_NAME=tensorflow-666 -e MODEL_TYPE=tensorflow tis-model-convert:lastest# SOURCE_MODEL_PATH 原始模型所在路径,也是模型描述文件所在路径# TARGET_MODEL_PATH 生成TensorRT模型所在路径# MODEL_NAME 模型名称# MODEL_TYPE 模型类型 (tensorflow or pytorch)
docker pull nvcr.io/nvidia/tritonserver:20.08-py3docker run -v ${TARGET_MODEL_PATH}:/workspace -p 8001:8001 nvcr.io/nvidia/tritonserver:20.08-py3 /opt/tritonserver/bin/tritonserver --model-repository=/workspace# TARGET_MODEL_PATH即为模型转换服务中环境变量值,默认使用8001端口且此端口固定
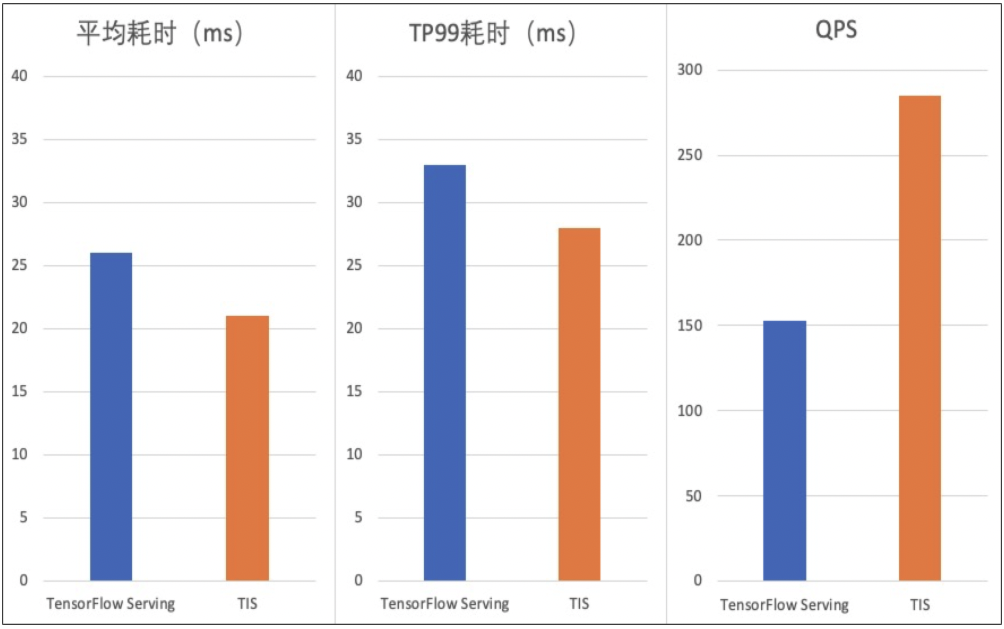
使用Intel MKL 加速深度学习推理
-
在CPU上运行时将TensorFlow替换为Intel优化版本,这样能在不改变模型网络的前提下提升性能。 -
消除不必要且耗费计算资源的数据层转换。 -
将多个运行融合在一起以在CPU上高效重复使用高速缓存。
KMP_BLOCKTIME - 设置线程在执行完并行区域之后,在休眠之前应该等待的时间(以毫秒为单位)
KMP_AFFINITY - 控制线程如何分布并绑定到特定的处理单元
KMP_SETTINGS - 允许 (true) 或禁止 (false) 在程序执行期间输出 OpenMP* 运行时库环境变量
OMP_NUM_THREADS - OpenMP运行时可用的最大线程数,通常设置为等于物理内核的数量
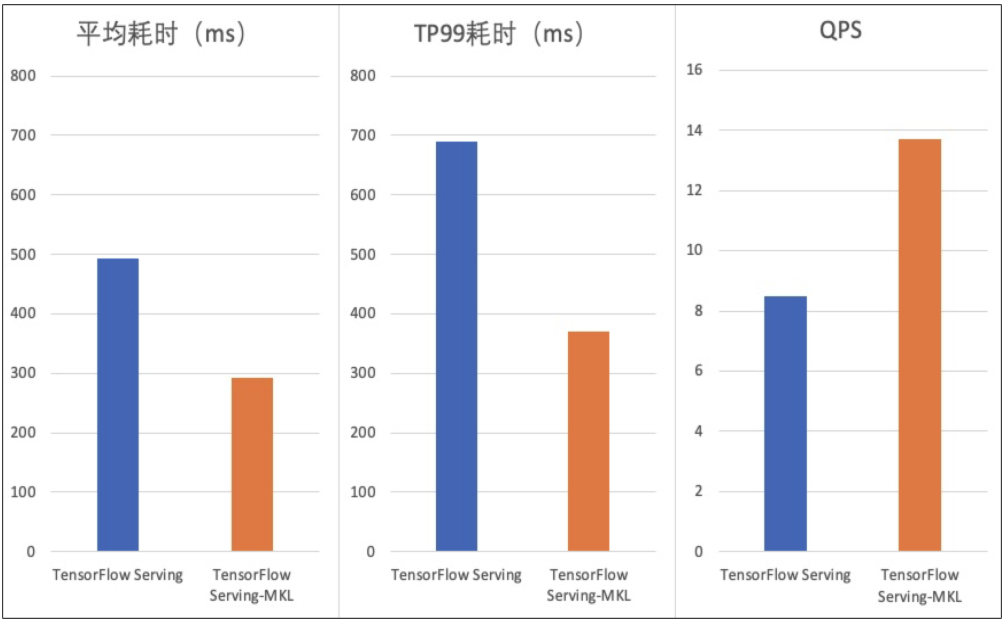
Caffe是一款较为主流的深度学习框架,使用人数虽然相比TensorFlow和PyTorch较少,但是仍然有着较大的应用基数。因此dl_inference在v1.1版本中,基于Seldon封装了Caffe模型推理RPC服务,统一接口协议,适用任何类型的Caffe模型,极大减少模型部署工作量。同时在模型RPC服务封装时我们进行了创新,首先,引入前后预处理程序, 支持用户在执行模型推理前后进行相关数据的处理;其次 ,开放模型调用,用户可以根据业务及模型的特点进行模型调用独立定制,Caffe模型推理流程如下图。
不同的业务场景模型实现不尽相同,为了支持在不同场景下的模型调用需求,用户可以在自定义接口文件中,重新定义模型的执行过程。默认的模型执行是单次执行,自定义接口函数中,可以多次执行同一个模型,或通过推理数据的参数修改模型内部权重,然后再进行模型调用,实现同一模型适应不通场景下的推理。dl_inference开放了模型调用的过程,提高了模型实现的灵活性,从而满足不同业务方的定制化需求。
提供丰富的应用示例
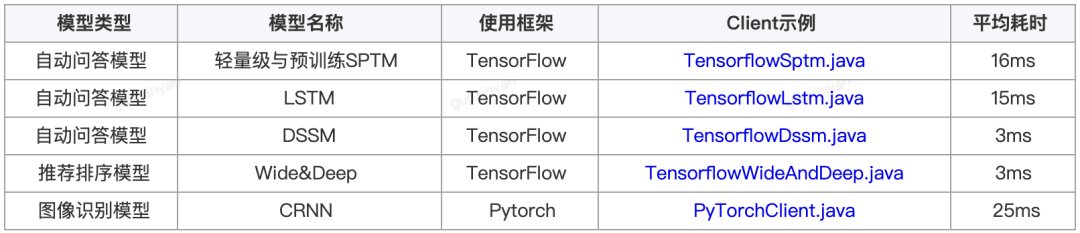
为了方便大家使用,dl_inference提供了更多模型案例供用户参考,包括: qa_match (由58同城开源的基于深度学习的问答匹配工具)训练模型、推荐排序和图像识别模型。
总结

未来我们会继续优化扩展dl_inference的能力,计划开源如下
1、持续优化CPU上推理性能,如兼容Intel的OpenVINO加速组件。
2、持续优化GPU上推理性能,如兼容INT8低精度推理、支持更多的算子等。
贡献指引:
本次开源只是dl_inference贡献社区的一小步,我们真挚地希望开发者向我们提出宝贵的意见和建议。您可以挑选以下方式向我提交反馈建议和问题
1、在https://github.com/wuba/dl_inference 提交PR或者lssue。
2、邮件发送至 ailab-opensource@58.com
[1] 通过Intel MKL优化TensorFlow:https://www.intel.cn/content/www/cn/zh/developer/articles/technical/tensorflow-optimizations-on-modern-intel-architecture.html
[2] 在Intel CPU上通过参数配置优化TensorFlow性能:https://www.intel.com/content/www/us/en/developer/articles/technical/maximize-tensorflow-performance-on-cpu-considerations-and-recommendations-for-inference.html
[3] Intel深度学习加速调优指南:https://www.intel.cn/content/www/cn/zh/developer/articles/technical/deep-learning-with-avx512-and-dl-boost.html
[4] NVIDIA TensorRT介绍:https://docs.nvidia.com/deeplearning/tensorrt/
[5] NVIDIA Triton-Inference-Server介绍:https://developer.nvidia.com/nvidia-triton-inference-server
本文分享自微信公众号 - 58技术(architects_58)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

JuiceFS 性能评估指南
JuiceFS 是一款面向云原生环境设计的高性能 POSIX 文件系统,任何存入 JuiceFS 的数据都会按照一定规则拆分成数据块存入对象存储(如 Amazon S3),相对应的元数据则持久化在独立的数据库中。这种结构决定了 JuiceFS 的存储空间可以根据数据量弹性伸缩,可靠地存储大规模的数据,同时支持在多主机之间共享挂载,实现跨云跨地区的数据共享和迁移。 JuiceFS 在运行过程中, 可能会因为硬件软件差异, 系统配置不同, 文件大小等原因导致实际的性能表现会有所不同。之前分享过[如何利用 JuiceFS 的性能工具做分析和调优]本文我们将更进一步介绍如何对 JuiceFS 进行准确的性能评估,希望能帮到大家。 前言 在进行性能测试之前,最好写下该使用场景的大致描述,包括: 对接的应用是什么?比如 Apache Spark、PyTorch 或者是自己写的程序等 应用运行的资源配置,包括 CPU、内存、网络,以及节点规模 预计的数据规模,包括文件数量和容量 文件的大小和访问模式(大文件或者小文件,顺序读写或者随机读写) 对性能的要求,比如每秒要写入或者读取的数据量、访问的 QP...
- 下一篇
超基础的机器学习入门-原理篇
前言— 随着前端智能化的火热,AI机器学习进入前端开发者们的视野。AI能够解决编程领域不能直接通过规则和运算解决的问题,通过自动推理产出最佳策略,成为了前端工程师们解决问题的又一大利器。 可能很多同学都跃跃欲试过,打开 TensorFlow 或者 Pytorch 官网,然后按照文档想要写一个机器学习的 Hello World ,然后就会遇到一些不知道是什么的函数,跑完例子却一头雾水,这是因为 TensorFlow 和 Pytorch 是使用机器学习的工具,而没有说明什么是机器学习。所以这篇文章以实践为最终目的出发,介绍一些机器学习入门的基本原理,加上一丢丢图像处理的卷积,希望可以帮助你理解。 基础概念— 首先,什么是机器学习?机器学习约等于找这样一个函数,比如在语音识别中,输入一段语音,输出文字内容 在图像识别中,输入一张图像,输出图中的对象, 在围棋中,输入棋盘数据,输出下一步怎么走, 在对话系统中,输入一句 hi ,输出一句回应, 而这个函数,是由你写的程序加上大量的数据,然后由机器自己学习到的。 怎么找这样一个函数呢,让我们从线性模型入手。线性模型形式简单,易于建模,但是蕴含着机...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- CentOS8安装MyCat,轻松搞定数据库的读写分离、垂直分库、水平分库
- Docker使用Oracle官方镜像安装(12C,18C,19C)
- Linux系统CentOS6、CentOS7手动修改IP地址
- CentOS7编译安装Cmake3.16.3,解决mysql等软件编译问题
- CentOS8编译安装MySQL8.0.19
- Docker安装Oracle12C,快速搭建Oracle学习环境
- CentOS7设置SWAP分区,小内存服务器的救世主
- CentOS6,7,8上安装Nginx,支持https2.0的开启
- CentOS关闭SELinux安全模块
- 设置Eclipse缩进为4个空格,增强代码规范
 微信收款码
微信收款码 支付宝收款码
支付宝收款码