摘要:Python 有几种方法可以定时调度一个任务,这就是我们将在本文中学习的内容。
本文分享自华为云社区《Python中使用定时调度任务(Schedule Jobs)的5种方式)》,作者: Regan Yue 。
今天构建的大多数应用程序都需要某种方式的调度机制。轮询 API 或数据库、不断检查系统健康状况、将日志存档等是常见的例子。 Kubernetes和Apache Mesos等使用自动伸缩扩容技术(Auto-scaling)的软件需要检查部署的应用程序的状态,为此它们使用定期运行的存活探针(Liveness Probe)。调度任务需要与业务逻辑解耦,因此我们要使用解耦的执行队列,例如Redis队列。
Python 有几种方法可以定时调度一个任务,这就是我们将在本文中学习的内容。我将使用以下方式讨论调度任务:
- 简单循环 (Simple Loops)
- 简单循环但是使用了线程 (Simple Loops but Threaded)
- 调度库 (Schedule Library)
- Python Crontab
- RQ 调度器作为解耦队列 (RQ Scheduler as decoupled queues)
简单循环 Simple loops
使用简单循环来实现调度任务这是毫不费力的。使用无限运行的 while 循环定期调用函数可用于调度作业,但这不是最好的方法,不过它是很有效的。可以使用内置time模块的slleep()来延迟执行。不过这并不是大多数作业的调度方式,因为,它看起来很难看,而且与其他方法相比,它的可读性较差。
import time
def task():
print("Job Completed!")
while 1:
task()
time.sleep(10)
当涉及到每天早上 9:00 或每周三晚上 7:45 等这些日程安排时,事情就变得比较棘手了。
import datetime
def task():
print("Job Completed!")
while 1:
now = datetime.datetime.now()
# schedule at every wednesday,7:45 pm
if now.weekday == 3 and now.strftime("%H:%m") == "19:45":
task()
# sleep for 6 days
time.sleep(6 * 24 * 60 * 60)
这是我的第一时间想到的解决办法,不用谢!这种方法的一个问题是这里的逻辑是阻塞的,即一旦在 python 项目中发现这段代码,它就会卡在 while 1 循环中,从而阻塞其他代码的执行。
简单循环但是使用了线程Simple loops but threaded
线程是计算机科学中的一个概念。具有自己指令的小程序由进程执行并独立管理,这就可以解决我们第一种方法的阻塞情况,让我们看看怎么样。
import time
import threading
def task():
print("Job Completed!")
def schedule():
while 1:
task()
time.sleep(10)
# makes our logic non blocking
thread = threading.Thread(target=schedule)
thread.start()
线程启动后,其底层逻辑无法被主线程修改,因此我们可能需要添加资源,程序通过这些资源可以检查特定场景并根据它们执行逻辑。
定时调度库 Schedule Library
早些时候,我说使用 while 循环进行调度看起来很丑陋,调度库可以解决这个问题。
import schedule
import time
def task():
print("Job Executing!")
# for every n minutes
schedule.every(10).minutes.do(task)
# every hour
schedule.every().hour.do(task)
# every daya at specific time
schedule.every().day.at("10:30").do(task)
# schedule by name of day
schedule.every().monday.do(task)
# name of day with time
schedule.every().wednesday.at("13:15").do(task)
while True:
schedule.run_pending()
time.sleep(1)
正如您所见,通过这样我们可以毫不费力地创建多个调度计划。我特别喜欢创建作业的方式和方法链(Method Chaining),另一方面,这个片段有一个 while 循环,这意味着代码被阻塞,不过我相信你已经知道什么可以帮助我们解决这个问题。
Python Crontab
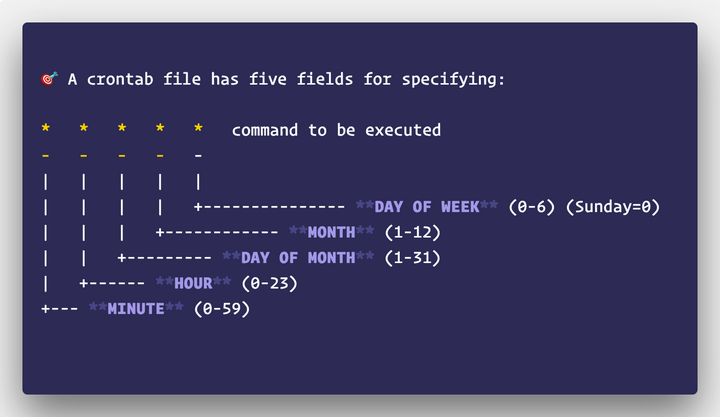
Liunx 中的 crontab 实用程序是一种易于使用且被广泛接受的调度解决方案。Python 库python-crontab提供了一个 API 来使用 Python 中的 CLI 工具。在crontab中,一个定时调度使用 unix-cron字符串格式(* * * * *)来描述,它是一组五个值的一条线,这表明当作业应该被执行时,python-crontab 将在文件中写入 crontab 的计划转换为写入编程方法。
![]()
from crontab import CronTab
cron = CronTab(user='root')
job = cron.new(command='my_script.sh')
job.hour.every(1)
cron.write()
python-crontab 不会自动保存计划,需要执行 write() 方法来保存计划。还有更多功能,我强烈建议您查看他们的文档。
RQ 调度器 RQ Scheduler
有些任务不能立即执行,因此我们需要根据 LIFO 或 FIFO 等队列系统创建任务队列并弹出任务。python-rq允许我们做到这一点,使用 Redis 作为代理来排队作业。新作业的条目存储为带有信息的哈希映射,例如created_at, enqueued_at, origin, data, description.
排队任务由名为 worker 的程序执行。workers 在 Redis 缓存中也有一个条目,负责将任务出列以及更新 Redis 中的任务状态。任务可以在需要时排队,但要安排它们,我们需要rq-scheduler。
from rq_scheduler import Scheduler
queue = Queue('circle', connection=Redis())
scheduler = Scheduler(queue=queue)
scheduler.schedule(
scheduled_time=datetime.utcnow(), # Time for first execution, in UTC timezone
func=func, # Function to be queued
args=[arg1, arg2], # Arguments passed into function when executed
kwargs={'foo': 'bar'}, # Keyword arguments passed into function when executed
interval=60, # Time before the function is called again, in seconds
repeat=None, # Repeat this number of times (None means repeat forever)
meta={'foo': 'bar'} # Arbitrary pickleable data on the job itself
)
RQ worker(RQ 工作器)必须在终端中单独启动或通过 python-rq 工作器启动。一旦任务被触发,就可以在工作终端中看到,在成功和失败场景中都可以使用单独的函数回调。
总结 Conclusion
还有一些用于调度的库,但在这里,我已经讨论了最常见的库。值得一提的是Celery,celery 的另一个优点是用户可以在多个代理之间进行选择。我很感激你读到最后。也可以看看我的其他文章。干杯!
翻译来源: https://python.plainenglish.io/5-ways-to-schedule-jobs-in-python-99de8a80f28e
点击关注,第一时间了解华为云新鲜技术~