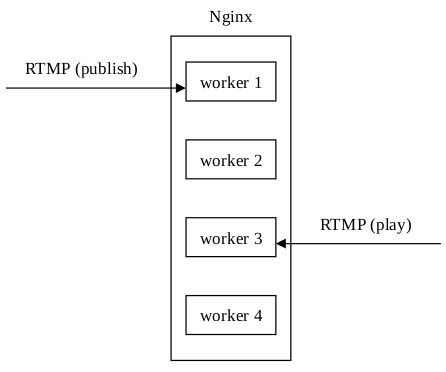
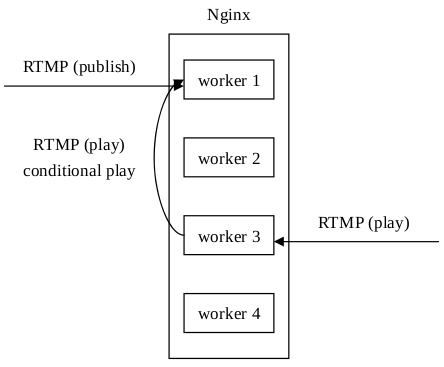
Arut最初在开发nginx-rtmp-module的时候只实现了单进程模式,好处是架构简单,推送和播放,数据统计,流媒体控制等都在一个进程上完成。但是这显然浪费了Nginx多进程(在Linux和FreeBSD平台上每个进程都可以绑定一个CPU核心,以减少进程切换带来的开销)的处理能力。但是,如果开启多进程模式,推送和播放如果不在同一个进程上,会造成播放失败的问题:
![]()
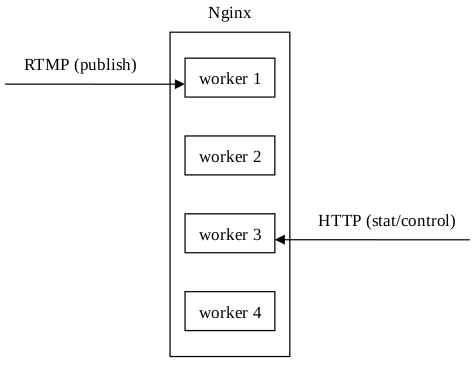
另外,请求数据统计信息也是个问题,因为采取HTTP方式请求数据统计信息时,在多进程模式下,请求被Nginx随机分配给了worker进程,可能造成我想看worker 1上的数据统计信息,但是Nginx返回的是worker 3上的数据统计信息。流媒体控制也采取了HTTP请求的方式,所以也存在着同样的问题:
![]()
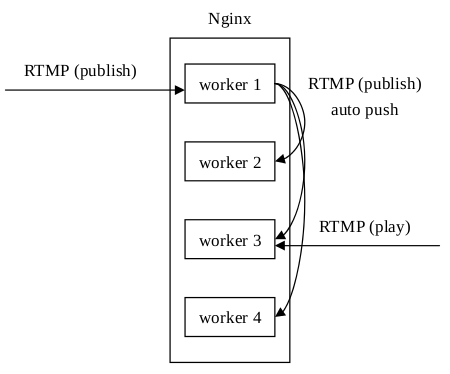
针对推送和播放不在同一个进程上的问题,Arut后来加入了auto push的功能,即把原始的推流数据再relay到其他进程上去。这个功能需要Unix domain socket的支持(所以类Unix系统都支持,Windows在Windows 10的某个版本后才开始支持):
![]()
这样处理后,不管播放请求落在哪个进程上,都能获得推送数据。
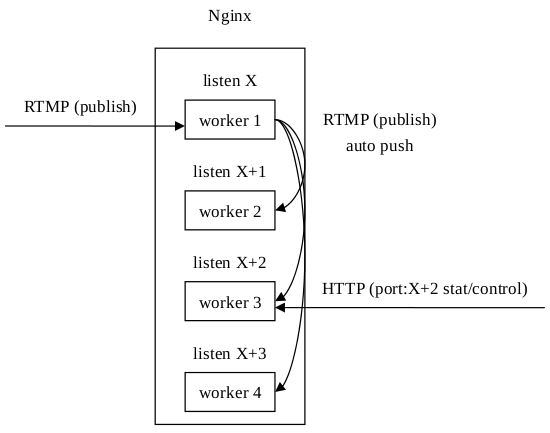
对于后面两个问题,Arut给出了一个布丁,需要修改Nginx本身的源代码,详情见per-worker-listener。这样处理后,在HTTP请求时加上端口号信息,就可以指定请求某个进程上的数据统计信息了,流媒体控制类似:
![]()
在测试中发现auto push的并发性能并不能随着CPU个/核数的提高而提高,一般在400~500路后就无法再提升(笔记本测试)。是什么原因呢?简单分析一下:假设服务器的CPU个/核数为N(Nginx的进程数一般配置为跟CPU个/核数相等),推流路数为M,且有M>>N,例如M=1000,N为4。假设M个推流请求被平均分配到N个进程上(实际上是不会被绝对平均分配的,但是相差不会很大),那么每个进程需要处理分配给自己本身的请求数为:
Publishers(self) = M / N
另外,要保证某个播放请求不管被哪个进程接受都能成功,那么每个进程都要接受另外N-1个进程的auto push过来的流,即:
Publishers(others) = M / N x (N - 1) = M - M / N
那么每个进程需要处理的推送路数为:
Publishers(all) = Publishers(self) + Publishers(others) = M / N + M - M / N = M
即每个进程需要处理的推流数跟CPU个/核数是没有关系的,并不能用增加CPU个/核数来试图提高推流并发性能,即相当于原本能将M个推流请求“平均”分配到N个进程上的方案不但没起作用,还让每个进程都处理了全部M个推流请求。
那么怎么解决这个问题呢?答案是使用被动拉的方案替代主动推(auto push)的方案。此方案要用到共享内存和互斥锁,当一个推流请求被某个进程接受后,在共享内存中记录推送的流和某个进程的映射信息。而当一个播放请求被某个进程接受后,需要先查找要播放的流是在哪个进程上发布的,然后再到发布流的进程上去请求数据:
![]()
这样就解决了上述的每个进程都要处理全部进程接收到的推流请求的问题。
关于nginx-rtmp-module的缺陷暂时介绍到这儿,其实nginx-rtmp-module还有很多其他的缺陷,后续有时间我会写文章介绍。
欢迎关注我在nginx-rtmp-module的基础上开发的项目:nginx-http-flv-module。