TCP Implementation in Linux: A Brief Tutorial
一个简单教程关于 TCP 协议在 linux 内核的实现
翻译:内核小王子 (欢迎订阅微信公众号)
原文:Helali Bhuiyan, Mark McGinley, Tao Li, Malathi Veeraraghavan University of Virginia
原文链接 TCP Implementation in Linux: A Brief Tutorial
A. Introduction
本文档简要概述了如何在Linux中实现TCP。他可能并不全面,并且也不能保证完全准确。
![]()
B. TCP implementation in Linux
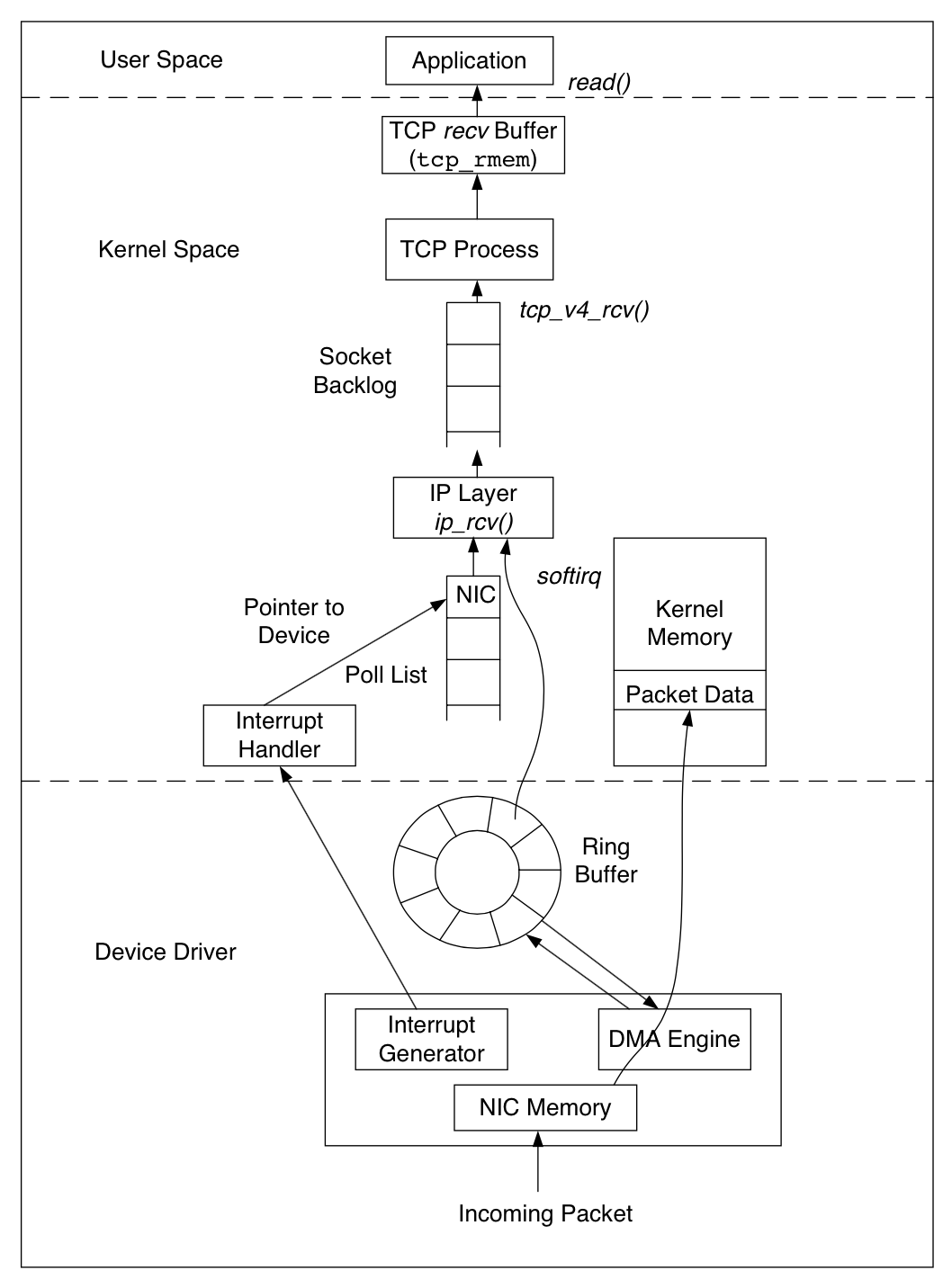
图1 和 图2 展示了 TCP/IP 协议栈在 Linux 内核中的实现,图1 展示了一个网络包通过物理网线到达应用程序的过程,Linux 内核使用一个名为 sk_buff 的数据结构来表示一个网络包。当一个网络包到达网卡时,会通过 DMA 引擎将这个 sk_buff 加入到一个叫 rx ring 的 ring buffer 中,当这个 ring buffer 已经满了的时候,的报文将被舍弃。当更高层的协议处理数据包的时候,报文保存在内核的内存中从而避免了额外的拷贝。
一旦成功接收到一个数据包,网卡会向 CPU 发送一个中断,中断处理函数将数据包传给 IP 层。 IP层处理完后,判断如果是 TCP 报文,就会将数据包发给 TCP 层处理,数据包经过 TCP 层一系列复杂的处理过程,会更新 TCP 的状态机,最后将数据包存储在 TCP 的 接收缓冲区中。
TCP 调优的一个关键参数为接收端的 recv 缓冲区大小。TCP 发送方能够发送的数据包的数量为发送方的拥塞控制窗口 (cwnd) 和接收方的告知的接收窗口 (rwnd) 中的最小值。而接收方告知的接收窗口的最大值就是 recv 缓冲区大小。因此,如果 recv 缓冲区设置的比 BGP (带宽延迟积) 小,则网络的吞吐量将会很低。另外,一个大的 recv 缓冲区允许大量的数据包处于未完成状态,可能超过了双方可以维持的数据包数量。recv 缓冲区大小可以通过修改 /proc/sys/net/ipv4/tcp rmem变量来设置。它需要三个值,最大值,最小值,默认值。最小值定义了最小可以接收的缓冲区大小,即使操作系统处于硬件内存很小。默认值是接收缓冲区的默认大小,它与TCP滑动窗口比例一起用来计算实际公示的窗口大小。max 定义接收缓冲区的最大值。
此外在接收端,参数netdev max backlog 指示网卡设备上排队的最大数据包数,这些数据包等待TCP接收进程处理。如果一个新收到的数据包在添加到队列时会导致队列超过netdev max backlog,那么它将被丢弃。
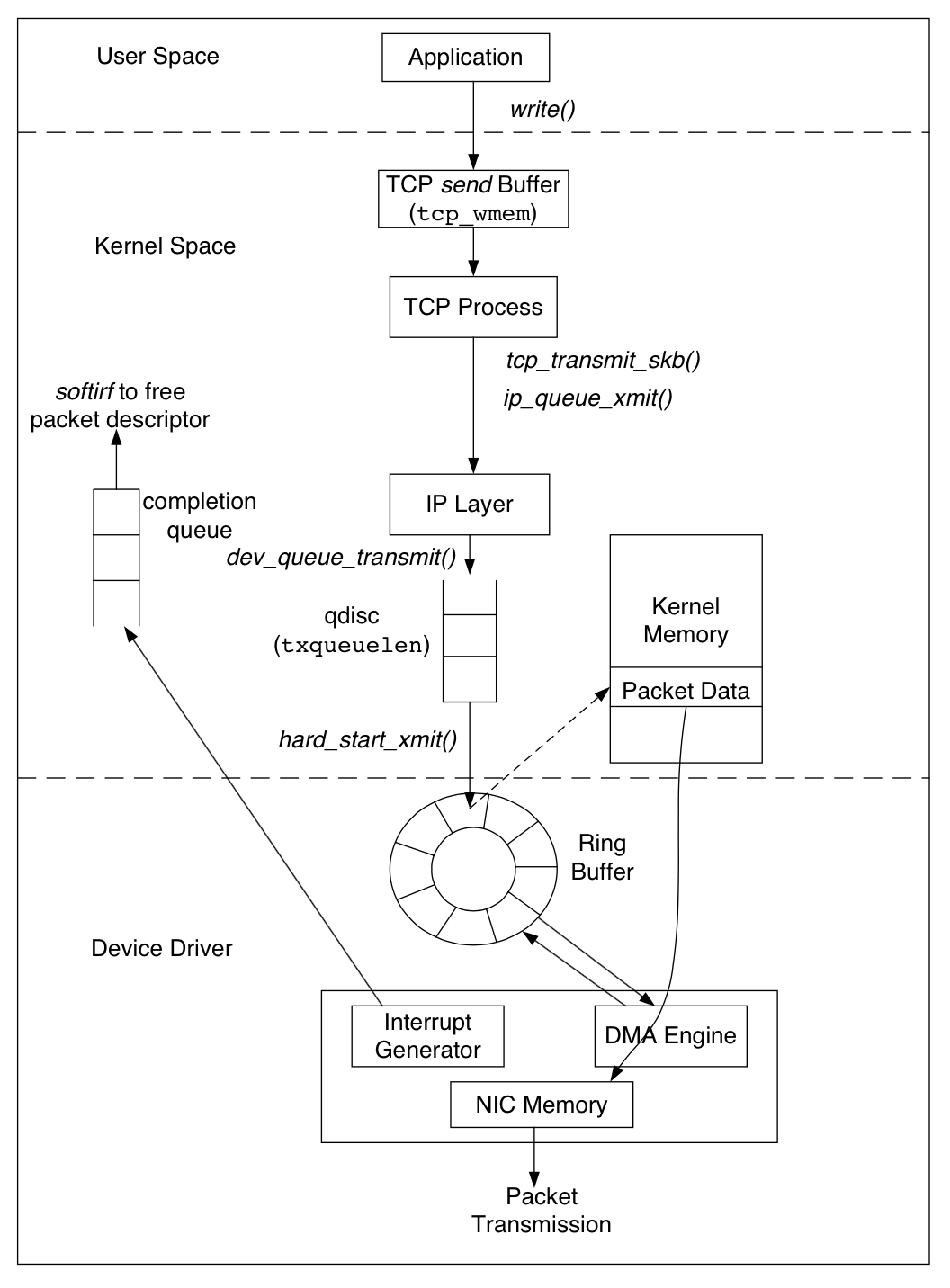
在发送端,如图 2 ,所示,用户程序通过系统调用 write() 将数据写入 TCP 的 send buffer,和接收端的缓冲区一样,send buffer 也是提供吞吐量很重要的参数。拥塞窗口的最大值和分配给 TCP socket 的 send buffer 空间大小相关,send buffer 保存了所有还没有确认的数据包,因为该数据包可能还需要重发,如果s end buffer 设置的太小,则拥塞窗口也会变小,将影响吞吐量。另外,一个大的 send buffer 可能导致拥塞窗口变大,如果没有通过 接收端的 recv buffer 来限制,未确认的报文数目会随着拥塞窗口的增加而变大,如果超过双方可以维持的最大包数目从而导致丢包。send buffer 的大小可以通过修改 /proc/sys/net/ipv4/tcp 的 wmem 变量值,同样需要配置最大最小值和默认值。
![]()
类似于接收端的 netdev max backlog 是发送者的网卡设备上排队的最大数据包数。TCP 层在数据到达 send buffer的时候会构建报文,当收到确认报文回复的时候也会更高数据包状态。构建好 TCP 报文后会将数据包推送到协议下层的 IP 层进行传输,IP 层将加数据包放入一个和网卡关联的输出队列。该队列的大小可以通过修改和网卡设备关联的 txqueuelen 变量值来设置。如果队列已满,会尝试将数据包排队生成一个阻塞事件传播到 TCP层。TCP 拥塞控制算法将减少拥塞窗口的状态变量,每有一个阻塞事件会将当前拥塞窗口的状态变量减半。当数据包成功加入到队列,则这个数据包的描述符 (sk buff) 将会放入到发送方的 ring buffer 中,之后设备驱动通过 DMA engine 将数据包传输到线路中。
上述参数展示了网络连接的流量控制,但拥塞控制行为也会对对吞吐量产生很大影响。TCP使用多种拥塞控制算法来匹配发送速率以适应有瓶颈的线路。在一个无连接的网络环境里,大量的TCP流和其他类型的流量共享同一个瓶颈链路,当链路上的数据包数量发生变化的时候,TCP 流的可用带宽也会变化。当TCP流的发送速率高于可用带宽时,数据包会丢失。另一方面,由于带宽被保留,数据包不会因为与电路中其他流的竞争而丢失。但,当一个发送速率很快的发送端连接到一个速率较低的链路时,由于交换机的缓冲区溢出,数据包也可能会丢失。
当一个 TCP 完成连接建立后,发送方使用确认报文作为一个时钟从而将新的数据包加入网络,称为 ACK-clocking。由于 TCP 接收端发送 ACK 数据包的速度不能超过瓶颈链路速率,因此ACK 时钟下的 TCP 发送端传输速率与瓶颈链路速率匹配。为了启动 ACK 时钟,TCP 发送端使用慢速启动机制。在慢启动阶段,对于接收到的每个 ACK 数据包,TCP发送端连续传输两个数据包。由于 ACK 数据包以瓶颈链路速率传输,发送方传输数据的速度基本上是瓶颈链路能够维持的速度的两倍。当拥塞窗口的大小超过 ssthresh 时,慢启动阶段结束。在许多拥塞控制算法中,如 bic,可以调整初始慢启动阈值(ssthresh),以及其他因素(如最大增量),使bic或多或少提高效率。但是,与通过sysctl函数更改缓冲区一样,这些是系统范围内的更改,可能会对其他正在进行的连接和将来的连接产生不利影响。TCP 发送端最多只能发送拥塞窗口和接收端公布的窗口中的最小值。因此,除非受接收端公示的窗口的限制,否则每个往返时间内未完成数据包的数量将增加一倍。由于数据包是由瓶颈链路速率转发的,因此在每个往返时间内,将未完成数据包的数量加倍也将使瓶颈交换机内的缓冲区占用率加倍。最后,一旦缓冲区溢出,瓶颈交换机内部就会有数据包丢失。
当发生数据包丢失后,TCP发送端进入拥塞控制阶段。在这期间,每收到一个回复报文拥塞窗口加一。当 ACK 数据包以瓶颈链路速率返回时,拥塞窗口和未完成数据包的数量都在不断增加。因此,一旦未完成数据包的数量超过瓶颈链路交换机中的缓冲区大小加上线路上的数据包数量,数据包将再次丢失。
还有许多与 Linux 中的 TCP 操作相关的其他参数,并且每个参数都在发布的文档(documentation/networking/ip sysctl.txt)中进行了简要说明。TCP 实现可配置参数的一个例子是 rfc2861 拥塞窗口重启功能。如果发送方 空闲一段时间(一个 RTO),则RFC2861 Pro 将重新启动拥塞窗口,目的是确保拥塞窗口反映网络的当前状态。如果连接处于空闲状态,拥塞窗口可能反映网络的已经过时状态,需要进行重置。可以使用 ysctl tcp slow start 在空闲后禁用此行为,但此更改会影响系统范围内的所有连接。
如果对 TCP 对流量控制和拥塞控制不是很理解,欢迎关注公众号 内核小王子 ,下周将分享 网络内核之如何实现c10m 深入分析linux的网络模型
![]()