前言
kafka 集群消息同步是一个常见的需求,MirrorMarker 是 kafka 官方仓库提供的用于 kafka 各集群间 topic 消息同步的工具,本文旨在通过测验 MirrorMarker 的使用,搞清楚 MirrorMarker 的实现原理,以及通过各种使用场景模拟,验证 MirrorMarker 的可用性。
相关链接
本文软件版本
- spring-boot:2.4.5
- spring-kafka\spring-kafka-test:2.7.2
- kafka(MirrorMarker):2.5.1
创建 kafka-mock-server 项目
用于搭建测试 kafka 集群,测试 kafka 消息发送、消费,kafka 消息集群同步的项目。有如下模块。
mock-server
mock-server 用来创建 kafka 集群,进入项目的测试模块下,有如下创建 kafka 服务的启动器:
- KafkaMockServer9097:创建一个端口号为 9097 的单 broker 的 kafka 服务,zookeeper 端口号随机
- KafkaMockServer9098:创建一个端口号为 9098 的单 broker 的 kafka 服务,zookeeper 端口号随机
- MultipleBroker001:创建端口号为 9090、9091、9092 的多 broker 的 kafka 服务,zookeeper 端口号 59551
- MultipleBroker002:创建端口号为 9095、9096、9097 的多 broker 的 kafka 服务,zookeeper 端口号 59552
producer
producer 用来发送 kafka 消息,并监听自己发送的消息,消息发送做了计数统计,用于和同步 kafka 集群接收的的消息数据做对比
@SpringBootApplication
@RestController
public class ProducerMain {
private static final Logger logger = LoggerFactory.getLogger(ProducerMain.class);
private final KafkaTemplate<Object, Object> template;
private static final AtomicInteger integer = new AtomicInteger();
public static void main(String[] args) {
SpringApplication.run(ProducerMain.class, args);
}
public ProducerMain(KafkaTemplate<Object, Object> template) {
this.template = template;
}
@GetMapping("/send")
public String send() {
String message = "message:" + integer.incrementAndGet();
this.template.send("topic001", message);
return message;
}
@GetMapping("/send-message-by-time")
public String sendMessageByTime() throws ExecutionException, InterruptedException {
AtomicInteger counter = new AtomicInteger();
LocalDateTime stopTime = LocalDateTime.now().plusMinutes(3);
while (LocalDateTime.now().isBefore(stopTime)) {
String message = "message:" + counter.incrementAndGet();
//.get() 用于将异步发送变同步,异步发送本机受不了
template.send("topic001", message).get();
}
String result = "3 分钟总共发送了 " + counter.get() + " 条消息";
logger.info(result);
return result;
}
@KafkaListener(id = "webGroup", topics = "topic001")
public void listen(String input) {
logger.info("input value: {}", input);
}
}
producer 是一个 spring-boot 的 web 应用,默认启动 8089 端口,项目启动成功后,访问
consumer
consumer 用来消费 MirrorMaker 同步到 kafka 集群的消息,消息到的消息也做了计数,用于和发出的消息数据做对比
@SpringBootApplication
@RestController
public class ConsumerMain {
private static final Logger logger = LoggerFactory.getLogger(ConsumerMain.class);
private static final AtomicInteger counter = new AtomicInteger();
public static void main(String[] args) {
SpringApplication.run(ConsumerMain.class, args);
}
@KafkaListener(id = "ConsumerMain", topics = "topic001")
public void listen(String input) {
logger.info("总计:{},{}", counter.incrementAndGet(), input);
}
}
每做一次消息同步测试,都需要重启 ConsumerMain 服务,用于重置消息计数器,只有当计数器相等时,才认为消息同步成功无丢失无冗余
mirror-maker
mirror-maker 模块用于 kafka 消息集群同步,分别创建单线程的消费实例和多线程消费实例,观察消费者线程重新平衡的过程。
public class MirrorMarkerMain001 {
/**
* 开启 1 个消费线程的 kafka 集群同步服务
* @param args 命令入参,可用来覆盖默认默认配置
*/
public static void main(String[] args) {
if (args.length == 0) {
args = ConfigProvider.getOneThreadConfig();
}
MirrorMaker.main(args);
}
}
kafka-manager
kafka-manager 是雅虎开源的管理 kafka 集群的项目,kafka-manager 本身也是集群架构,需要依赖 zookeeper。项目拉下来后,先修改 conf/application.conf 中的 zookeeper 配置,然后根目录下执行 ./sbt start 启动项目。默认 web 端口是 9000,启动成功后,访问 http://127.0.0.1:9000
在 web 页面上添加需要管理的 kafka 集群时,只需要配置 kafka 集群的 zookeeper 地址即可。
测试 MirrorMarker 启停,组件工作是否正常
操作步骤如下,使用 kafka-manager 观察:
- 1、分别启动 MultipleBroker001、MultipleBroker002、MirrorMarkerMain001、producer、consumer、kafka-manager 等服务
- 2、触发 producer 的 /send 接口,检查服务是否正常工作
- 3、触发 producer 的 /send-message-by-time 接口,观察消息发送、消费情况,MirrorMarker 同步情况(消息总共会同步发送三分钟,期间完成如下操作)
- 4、启动 MirrorMarkerMain002 服务,观察同步消费组的 Consumer Instance Owner 变化
- 5、停止 MirrorMarkerMain001 服务,观察同步消费组的 Consumer Offset 状态
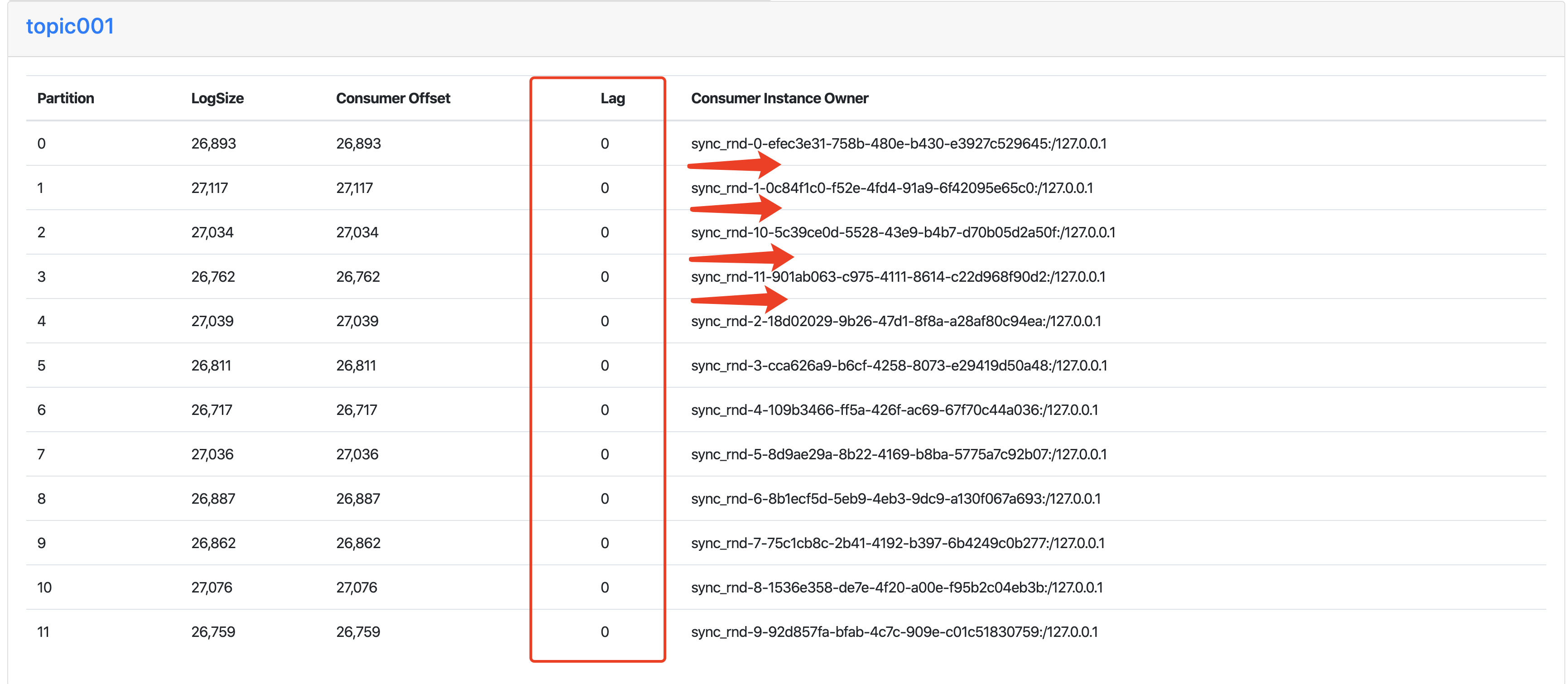
- 6、测试结束,对比发送的消息总数和同步集群消费到的总数,观察是否 LogSize 和 Consumer Offset 是否一致
步骤三 producer 发送记录图
![]()
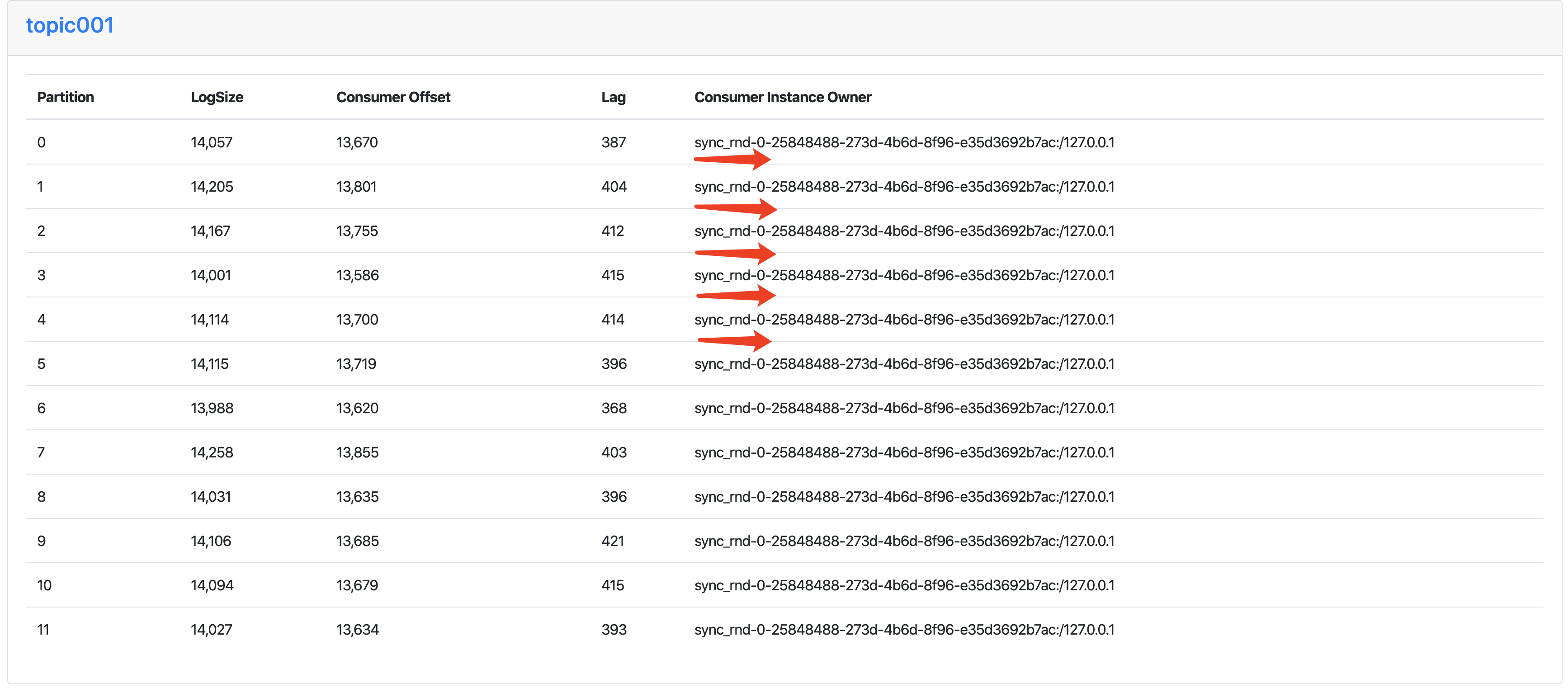
步骤三 Consumer Instance Owner 情况
![]()
步骤四、五、六 Consumer Instance Owner 、Consumer Offset的消息状态
![]()
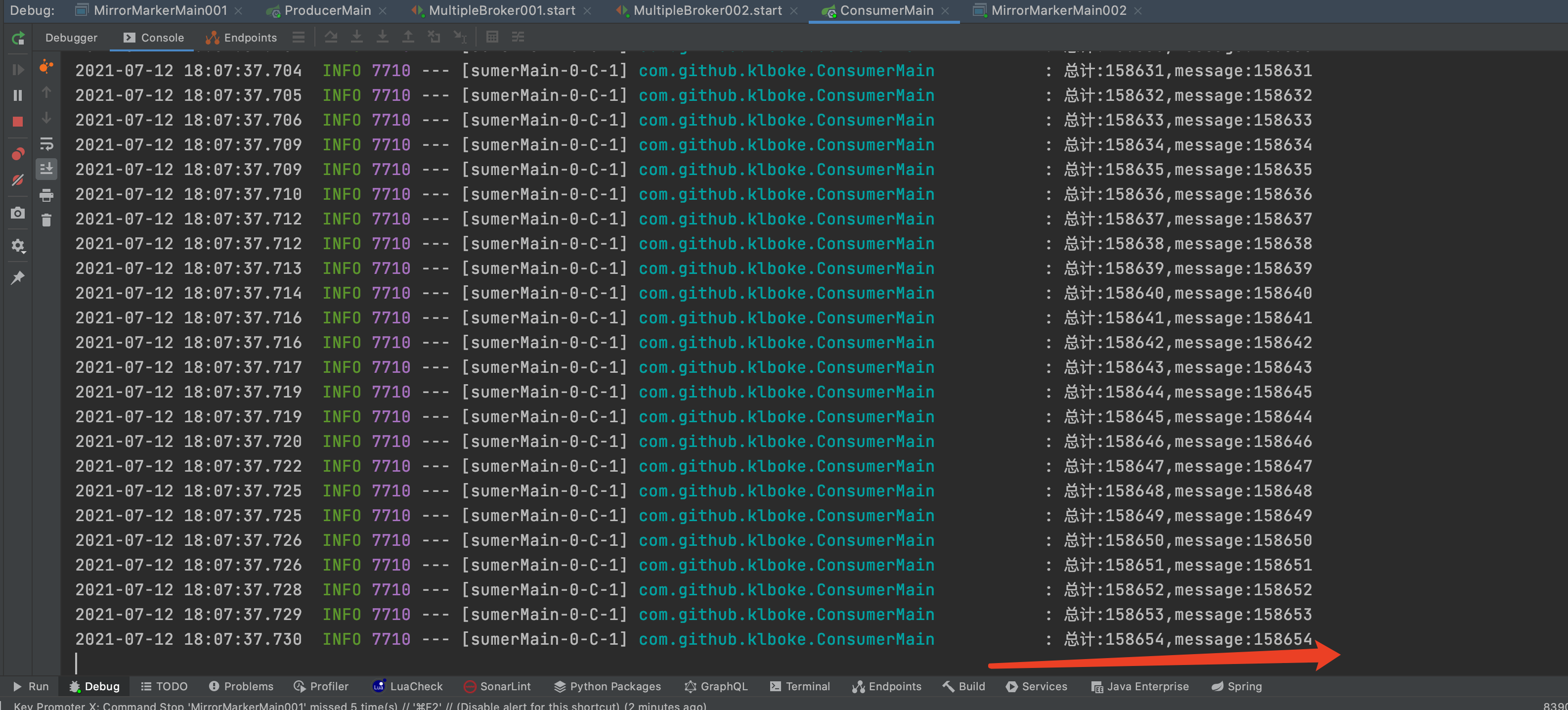
步骤六 Consumer 的消息情况
![]()
结果分析:
从测试结果来看,可以得出如下几个结论
1、从单消费线程的 MirrorMarkerMain001 切换到 MirrorMarkerMain001、MirrorMarkerMain002 同时工作,会触发 Consumer group 的消费重平衡,这个从 topic001 的 partition 的 Consumer Instance Owner 就能看出来
2、MirrorMarker 的启停过程,不影响集群同步的结果,因为 producer 和 consumer 的计数器是相等的
3、开启 MirrorMarker 多消费线程,消息的积压明显好于单线程消费
MirrorMarker 实现原理分析
MirrorMarker 的工作原理就是创建一个Consumer group,然后定制 Consumer 、Producer 参数,用来保证消息的准确性(不丢消息)。下面结合上面的测试场景,带着一些边界场景的问题,深入到源码(MirrorMarker 在 kafka 的 tools 包下)窥探下 MirrorMarker 是怎么处理的。
问题一、offset 是如何管理的?是自动提交吗?
def createConsumers(numStreams: Int,
consumerConfigProps: Properties,
customRebalanceListener: Option[ConsumerRebalanceListener],
whitelist: Option[String]): Seq[ConsumerWrapper] = {
// Disable consumer auto offsets commit to prevent data loss.
maybeSetDefaultProperty(consumerConfigProps, "enable.auto.commit", "false")
// Hardcode the deserializer to ByteArrayDeserializer
consumerConfigProps.setProperty("key.deserializer", classOf[ByteArrayDeserializer].getName)
consumerConfigProps.setProperty("value.deserializer", classOf[ByteArrayDeserializer].getName)
// The default client id is group id, we manually set client id to groupId-index to avoid metric collision
val groupIdString = consumerConfigProps.getProperty("group.id")
val consumers = (0 until numStreams) map { i =>
consumerConfigProps.setProperty("client.id", groupIdString + "-" + i.toString)
new KafkaConsumer[Array[Byte], Array[Byte]](consumerConfigProps)
}
whitelist.getOrElse(throw new IllegalArgumentException("White list cannot be empty"))
consumers.map(consumer => new ConsumerWrapper(consumer, customRebalanceListener, whitelist))
}
MirrorMarker 里是手动管理 offset 的,周知,kafka 客户端的 Consumer 消费记录,即 offset 默认是自动提交的,如上代码,在 MirrorMarker 里禁用了自动提交。因为这个配置来自 consumer.properties 配置文件,也是可以修改的,当手动修改成自动提交时,MirrorMarker 会提示
data loss or message reordering is possible(可能产生消息丢失和重排序)
通过 offset.commit.interval.ms 来控制 offset 提交的频次,这个参数是针对 MirrorMarker 而言的,而不是 consumer.properties ,所以需要使用命令行参数设置 --offset.commit.interval.ms 来使用,单位是毫秒,默认是 60000 。每次 Consumer poll 消息后都会触发这个函数,Consumer poll 的阻塞时间默认是 1 秒,这个参数没法修改,看到这里你可能有疑问,60 s提交一次 offset ,要是提交前服务关了怎么办?这个在问题二、三都有答案。不过,在实际使用时,还是建议调整这个参数,这样看起来,消费的时延会比较准确。
def maybeFlushAndCommitOffsets(): Unit = {
if (System.currentTimeMillis() - lastOffsetCommitMs > offsetCommitIntervalMs) {
debug("Committing MirrorMaker state.")
producer.flush()
commitOffsets(consumerWrapper)
lastOffsetCommitMs = System.currentTimeMillis()
}
}
问题二、有新的 Consumer group 实例加入,是如何处理的?
在 kafka 实例中,当有新的 Consumer group 加入时,中央协调器会重新触发 partition 的重新分配,在消费者端,有一个专门的监听器处理这个重平衡事件,MirrorMarker 中,也实现了自己的监听器:
private class InternalRebalanceListener(consumerWrapper: ConsumerWrapper,
customRebalanceListener: Option[ConsumerRebalanceListener])
extends ConsumerRebalanceListener {
override def onPartitionsLost(partitions: util.Collection[TopicPartition]): Unit = {}
override def onPartitionsRevoked(partitions: util.Collection[TopicPartition]): Unit = {
producer.flush()
commitOffsets(consumerWrapper)
customRebalanceListener.foreach(_.onPartitionsRevoked(partitions))
}
override def onPartitionsAssigned(partitions: util.Collection[TopicPartition]): Unit = {
customRebalanceListener.foreach(_.onPartitionsAssigned(partitions))
}
}
当消费线程经过重新平衡后,失去了原先分配的 partition,则会立马提交自己的 offsets,不用等待 offset.commit.interval.ms
问题三、停止 MirrorMarker 的时候做了什么?
finally {
CoreUtils.swallow ({
info("Flushing producer.")
producer.flush()
// note that this commit is skipped if flush() fails which ensures that we don't lose messages
info("Committing consumer offsets.")
commitOffsets(consumerWrapper)
}, this)
info("Shutting down consumer connectors.")
CoreUtils.swallow(consumerWrapper.wakeup(), this)
CoreUtils.swallow(consumerWrapper.close(), this)
shutdownLatch.countDown()
info("Mirror maker thread stopped")
// if it exits accidentally, stop the entire mirror maker
if (!isShuttingDown.get()) {
fatal("Mirror maker thread exited abnormally, stopping the whole mirror maker.")
sys.exit(-1)
}
}
这段代码是 MirrorMarker 接收到关闭指令时运行的,程序关闭之前也提交了 offset,程序关闭事件是通过
Exit.addShutdownHook("MirrorMakerShutdownHook", cleanShutdown())
注册的,所以,千万别 kill -15 pid 暴力关闭
ps:以上涉及到的用户保证同步服务准确性定制的 Consumer 、Producer 参数,在 MirrorMarker 的类注释上也有直接说明,凡是如下注释列出的参数不要轻易修改,如:
/**
* The mirror maker has the following architecture:
* - There are N mirror maker thread, each of which is equipped with a separate KafkaConsumer instance.
* - All the mirror maker threads share one producer.
* - Each mirror maker thread periodically flushes the producer and then commits all offsets.
*
* @note For mirror maker, the following settings are set by default to make sure there is no data loss:
* 1. use producer with following settings
* acks=all
* delivery.timeout.ms=max integer
* max.block.ms=max long
* max.in.flight.requests.per.connection=1
* 2. Consumer Settings
* enable.auto.commit=false
* 3. Mirror Maker Setting:
* abort.on.send.failure=true
*/
结语
经过反复测试,验证了 MirrorMarker 服务还是比较稳定可靠的,多消费实例启停,触发消费重平衡等场景都能很好的处理。有两个参数建议调整下,num.streams ,这个参数控制了消费线程,建议和 partition 的数量保持一致即可,多了会有线程空跑,少了的话,同步的性能会下降,同步时延会增加。offset.commit.interval.ms 调整到 500 ,消费记录会趋向真实情况。另外,用于确保数据不丢失的默认参数,如 enable.auto.commit 、acks 等参数不要修改