📕 每日一句
极限就是为了超越而存在的,如何挑战自己的极限,只能苦练!
📕 为什么又要写类加载器?
为什么有些一篇相关与对类加载器的文章?个人觉得之前的侧重点在于ClassLoader本身,以及双亲委托机制,而本篇更多站在JVM虚拟机的层面上去讲述和描述,前者侧重于使用和实际,后者本篇注重于原理和深入分析。
📕 类加载的时机与作用
一段java程序在被执行的过程中,需要经历以下几个阶段:
📕 编译阶段
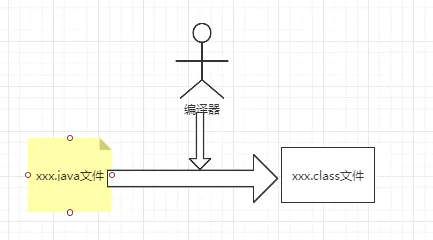
编译器将源码文件编译成class文件。
class文件是.java文件的二进制字节流表示,在class文件中,包含了对应的类或接口的定义信息等常量池数据。
-
内部存放的数据有:元数据常量池,访问标志,当前类索引、父类索引和接口索引的集合,字段表集合(类中声明的变量),方法表集合等,他们共同描述了一个类的信息。
-
每个class文件一定对应一个类,但反过来未必成立,例如,动态生成的类信息,直接生成二进制字节流送入类加载器完成类加载。
-
因此广义上来讲,class并不一定要是一个class文件,也可以仅仅就是一串二进制字节流。
![]()
📕 类加载阶段
![]()
📕 类加载的作用
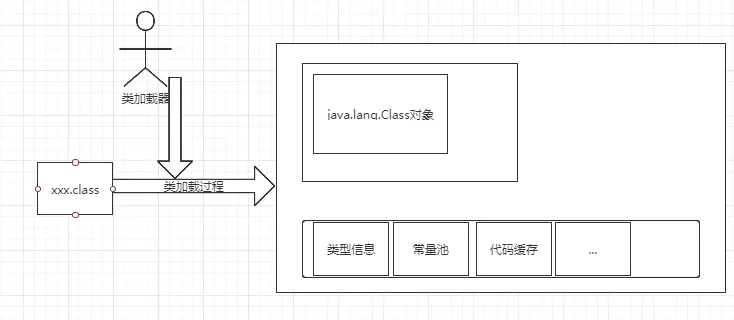
类加载在程序执行的过程中起到了承上启下的作用,将静态的二进制字节流数据转化为了运行时数据,供执行引擎去操作数据。
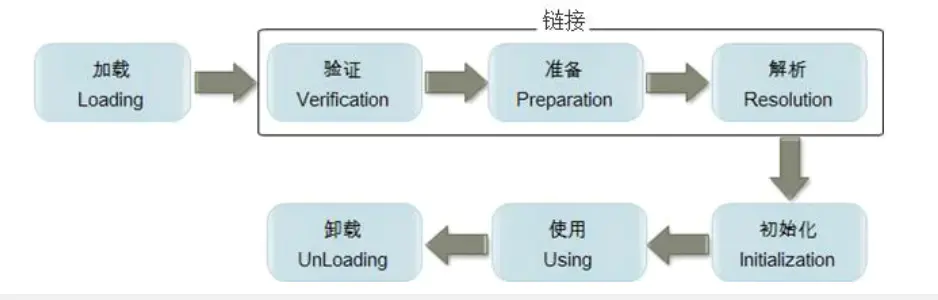
如图,加载-验证-准备-解析-初始化这五个阶段都属于类加载过程。
![]()
📕 类加载的时机
虚拟机规范并没有严格规定什么时候开始类加载。但是,规定了6种必须对类进行初始化的情况,它们被称为主动引用。
!!!由于初始化类对象需要在加载、验证、准备之后进行,因此这三步必然要在这之前完成。这里前4种是非常常见的,需要深刻掌握。
遇到new, getstatic, putstatic, invokestatic这四条字节码指令的时候,如果类型还没有被初始化,则需要初始化。
📕 其他的初始化条件
-
unsafe方法进行调用对象操作
-
clone方法进行操作,进行申请
-
通过文件IO的ObjectInputStream/ObjectOutputStream进行处理构造
-
通过反射对类进行调用的时候,需要确保类已经被初始化过。也好理解,反射的核心是Class对象。
-
当前类被初始化时,要先确保其父类已被初始化。
-
虚拟机启动时,要执行的主类(包含main方法的那个类)要先被初始化。
-
接口中定义了默认方法(被default修饰,可以有方法体的方法,比较少见),当该接口的实现类初始化时,该接口需要先被初始化。
除了以上的情况之外,所有其他对类的引用都不会触发类的初始化,他们被称为被动引用。
📕类加载的过程
加载
验证
验证的作用是确保Class文件内的信息符合虚拟机规范的要求,保证程序运行过程中的安全。
准备
为类变量(即静态变量)分配内存,并设初始值。(0, null, false ...)。
有两点需要留意:
解析
将运行时常量池中符号引用替换成直接引用。
举个例子,在解析完成之前,被引用的目标还没有被加载到内存中,只能先用一个符号来表示,如"java.lang.Object"。
初始化
在初始化阶段,需要执行类构造器(与实例对象的构造器区分开来)。类构造器并非我们直接编写的方法,而是编译器收集类变量的赋值语句和static代码块的产物。
初始化阶段就是对静态变量赋值和执行静态代码块的过程(父类会在前,子类会在后)。
实例化阶段就是执行实例构造器和实例代码块(构造代码块)的过程。
📕 执行指令(不是重点)
在这个阶段,字节码执行引擎根据指令,去操作内存中的数据,完成计算任务.