
世界冠军之路:菜鸟车辆路径规划求解引擎研发历程

阿里妹导读:车辆路径规划问题(Vehicle Routing Problem, VRP)是物流领域最经典的优化问题之一,具有极大的学术研究意义和实际应用价值。菜鸟网络高级算法专家胡浩源带领仓配智能化算法团队经过两年的研发,逐步沉淀出了一套完善、强大的车辆路径规划求解引擎,为菜鸟内外部多项业务提供了技术支持。通过不断地对算法进行探索打磨,我们终于在车辆路径规划问题最权威的评测平台上打破了多项世界纪录,标志着菜鸟网络在此领域的技术研究已经进入世界前列。
问题介绍
车辆路径规划问题是运筹优化领域最经典的优化问题之一。在此问题中,有若干个客户对某种货物有一定量的需求,车辆可以从仓库取货之后配送到客户手中。客户点与仓库点组成了一个配送网络,车辆可以在此网络中移动从而完成配送任务。在求解此问题过程中,需要优化的决策变量为每个客户的配送任务应该分配到哪一辆车上,以及每辆车完成客户配送任务的先后顺序,优化目标为最小化使用的车辆数和车辆总行驶距离(通常情况下最小化车辆数为第一优化目标)。
以i,j表示配送网络中的节点(i,j∈{0,1,2,…,N}), 其中0表示仓库点,其它表示客户点),以k表示车辆(k∈{1,2,…,K}),以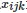 为决策变量,表示车辆k是否从i点行驶到j点。则标准的车辆路径规划问题可以使用以下数据规划的形式描述:
为决策变量,表示车辆k是否从i点行驶到j点。则标准的车辆路径规划问题可以使用以下数据规划的形式描述:
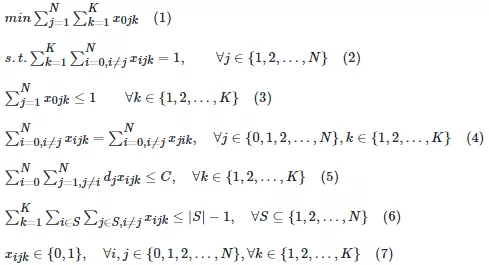
其中,表达式(1)表示优化目标为最小化使用车辆数;表达式(2)表示每个点有且仅有一辆车负责配送其所需要的货物;表达式(3)表示每辆车最多负责一条配送线路;表达式(4)表示网络中的流量平衡条件;表达式(5)表示每辆车负责配送的货物不超过其承载能力限制;表达式(6)为防止孤立子环出现的约束条件。
车辆路径规划问题在物流领域和生产领域的应用非常广泛。所以在实际应用中也出现了一些在标准问题的基础上增加了某些变化之后的变型问题。其中较为常见的包括:
- CVRP:Capacitated VRP, 限制配送车辆的承载体积、重量等。
- VRPTW:VRP with Time Windows, 客户对货物的送达时间有时间窗要求。
- VRPPD:VRP with Pickup and Delivery, 车辆在配送过程中可以一边揽收一边配送,在外卖O2O场景中比较常见。
- MDVRP: Multi-Depot VRP, 配送网络中有多个仓库,同样的货物可以在多个仓库取货。
- OVRP:Open VRP, 车辆完成配送任务之后不需要返回仓库。
- VRPB: VRP with backhauls, 车辆完成配送任务之后回程取货。
以上各类问题之间的关系可以通过图1表示:
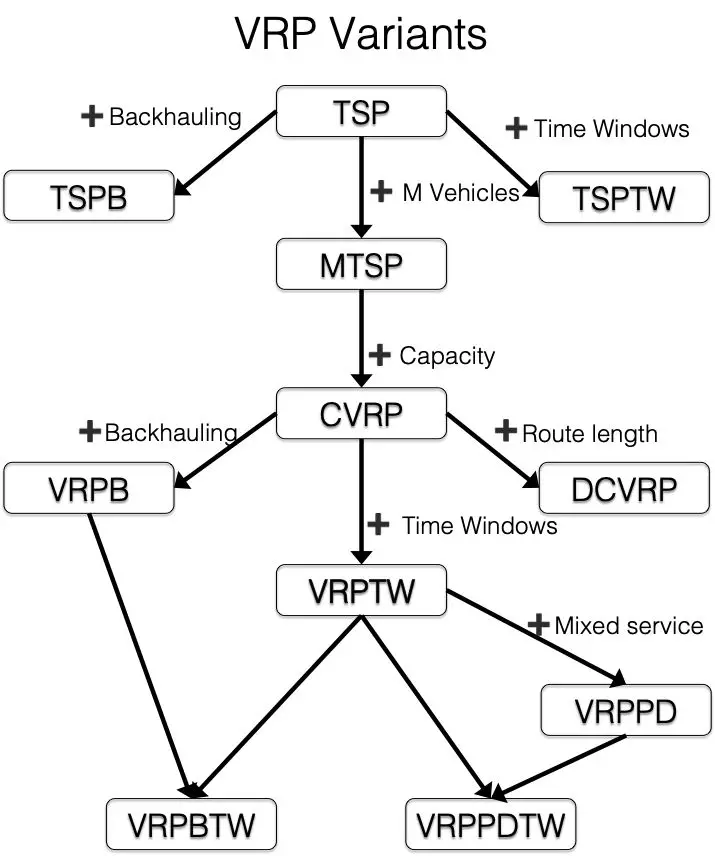
图1 VRP各类变型问题
经典求解算法
车辆路径规划问题是典型的NP-hard问题,非常具有挑战性。同时因为其在实际应用的巨大价值,学术界和工业界对此类问题的优化算法的探索已经持续了几十年的时间。已有的经典求解算法可以分为精确解算法和启发式算法两大类。
在精确解算法方面,最基本的方法为分支定界算法,虽然其能够从理论上保证在有限时间内获得最优解,但是在实际计算中存在计算耗时巨大的情况。为了提高求解效率,研究者们先后提出了多种Branch-and-Cut以及Branch-Cut-and-Price方法,大幅降低了算法的求解时间。但是对于实际应用中较大规模的问题而言(例如超过200个点的问题),精确解算法依然无法能够在合理的时间内完成计算。所以还有一大部分研究集中于启发式算法领域。
启发式算法的思想为通过一系列启发式的规则来构造和改变解,从而逐步提升解的质量。对于VRP而言,较为经典的启发式算法为Clarke-Wright算法等。此外,经过不断的探索研究,元启发式算法被证明在求解VRP方面具有很好的效果和效率。一些经过精心设计的元启发式算法,例如模拟退火、禁忌搜索、遗传算法、蚁群算法、变邻域搜索、自适应大规模邻域搜索算法等在求解VRP上有着非常好的表现。
菜鸟车辆路径规划引擎研发历程
阶段一:核心基础算法研发
在研发之初,菜鸟仓配智能化算法团队充分调研了VRP领域的相关学术论文和软件产品等,最终确定了以自适应大规模邻域搜索(Adaptive Large Neighborhood Search, ALNS)为核心算法进行算法引擎的建设。相对于其它算法,ALNS算法的优势包括:
- 算法框架易于拓展,除了求解标准的VRP之外,还能够求解VRPPD,MDVRP等变型问题;
- 相对于普通的Local Search类型的算法,ALNS在每一步搜索过程中能够探索更大的解空间;
- ALNS算法在搜索过程中能够自适应地选择合适的算子,从而对于不同类型的问题数据能够有比较稳定的良好求解结果;
- 通过设计实现不同类型的算子,ALNS可以实现不同的搜索策略,从而便于算法的升级拓展。
经典的ALNS算法的主流程如图2所示:
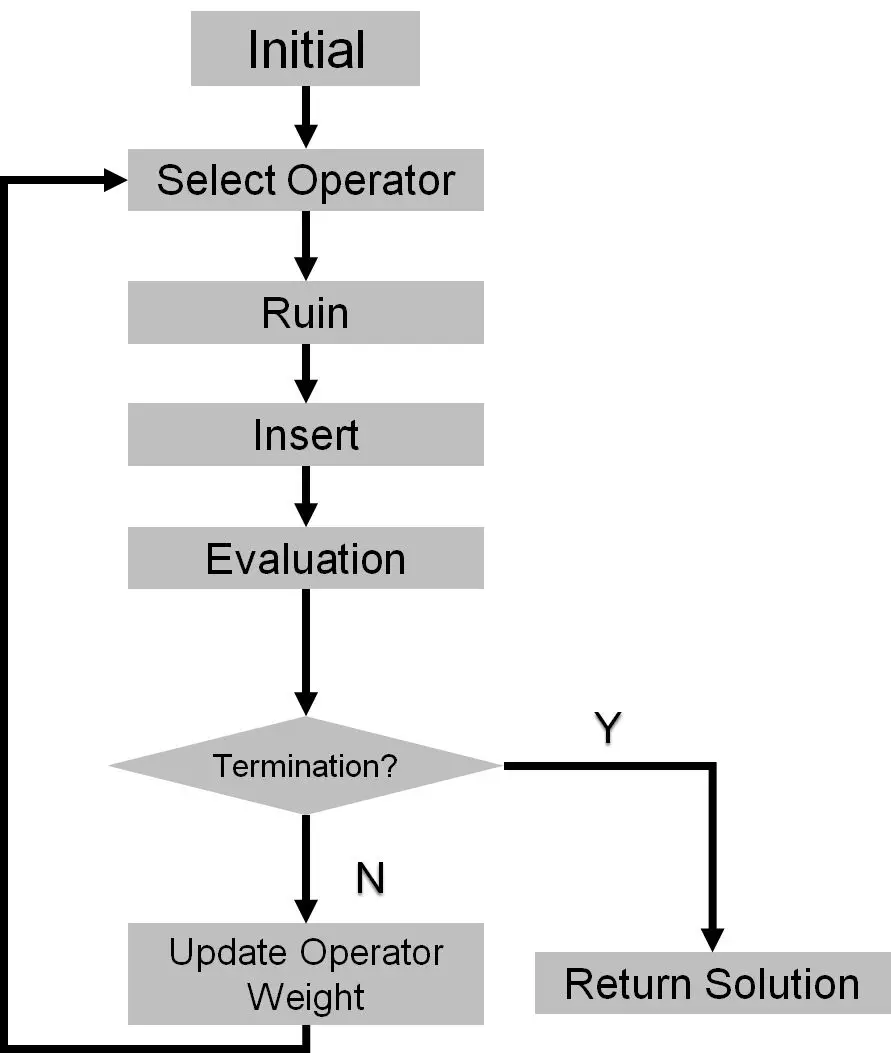
图2 ALNS算法主流程
如图2所示的ALNS算法的主要步骤为:
- 使用一定的规则构造一个初始解(即Initial过程);
- 基于算子的权重,选择此次迭代过程中使用的Ruin算子和Insert算子;
- 对此次迭代的初始解执行Ruin操作,即将部分已经被车辆服务的客户点删除,使初始解成为一个不可行解;
- 对步骤(3)获得的解执行Insert操作,即对于还没有被车辆服务的客户点,将其插入到解中,尽量获得一个可行解;
- 基于优化目标函数评估步骤(4)获得的新的解,并根据一定的策略决定是否接受新解;
- 判断是否达到终止条件。如果是,则终止计算,返回当前找到的最好解;否则,基于此轮计算中算子的表现,更新算子的权重,并返回到步骤(2)。
以ALNS算法为核心,菜鸟仓配智能化算法团队完成了第一版VRP优化引擎的研发。对比测试结果表明其求解效果和效率显著优于jsprit等国际上流行的开源VRP Solver。在此基础上,菜鸟仓配智能化算法团队还对引擎进行了服务化,从而更方便地服务于公司内外部用户。
阶段二:算法体系丰富与升级
为了更好地服务于公司内外部用户,菜鸟仓配智能化算法团队不断对VRP优化引擎的核心算法组件进行了丰富与升级。主要体现在以下几个方面:
1.完善功能:在原算法核心框架的基础上,增加了对Pickup and Delivery(车辆一边揽收一边派送)、Multi Trip(车辆多趟派送)等类型问题的支持;而且通过对实际业务问题的抽象,总结出了不同类型的优化目标方程(例如最小化阶梯定价的总成本、最小化配送时间等)以及约束条件(例如车辆行驶距离限制、车辆配送订单数限制、车辆跨区数限制等)。从而使求解引擎能够求解的问题更加全面广泛。
2.丰富算子:为了提升引擎的求解效果和稳定性,菜鸟仓配智能化算法团队还在VRP求解引擎中增加了更加丰富的优化算子,例如不同类型的局部搜索算子(例如Two-Opt, Three-Opt, Cross-Exchange等)、不同类型的中间结果接受策略(例如Greedy, Simulated Annealing等)。
3.提升效果:菜鸟仓配智能化算法团队还尝试了多种算法来提升引擎的求解效果,主要包括:
- Guided ejection search (GES):此算法通过不断尝试删减一辆车,并将此辆车服务的客户添加到其它车辆上,从而实现降低车辆的使用数。此算法在降低车辆数方面具有非常好的效果;
- Fast local search (FLS): 在搜索过程中,只搜索那些有希望改善当前解的的邻域空间,从而大幅降低搜索计算量,提升算法求解速度;
- Guided local serach (GLS): 在搜索过程中对局部最优解的某些特征施加惩罚项,从而改变搜索方向,避免陷入局部最优;
- Edge assembly crossover (EAX): 一种基于两个解生成一个新的解的方法,新生成的解能够很好的继承父代个体的空间结构;
- Branch-and-Price-Based Large Neighborhood Search:此算法将VRPTW问题分解为了Restricted Master Problem和Subproblem。其中在Restricted Master Problem中,基于一系列可行的路径,通过求解Set Partition问题来获得原问题的解;在Subproblem中,通过Tabu Search来搜索新的可行的路径;
- Path-Relink:此算法的核心思想为通过从initial solution到guiding solution的逐步移动,探索两个解之间的广阔的邻域,从而有可能发现更好的解;
- Hybrid Cluster and Heuristics:此算法是针对超大规模的问题而设计,首先通过合适的聚类算法对客户点进行聚类,从而将原问题分解为多个小规模的子问题,然后并行求解,最终将子问题的解组装成为原问题的解。
阶段三:算法并行化升级
对于大部分启发式算法而言,可以天然地通过并行化计算来提升搜索效率和效果,例如并行地计算评估多个相邻解的质量、向多个邻域方向进行搜索或者使用多种策略进行搜索等,甚至并行地使用多种算法进行搜索等。所以为了进一步提升VRP引擎的求解质量,菜鸟仓配智能化算法团队对VRP引擎进行了并行化升级。在此过程中,先后研发实现了三套并行化算法架构。
Population Island
Population Island的算法架构如图3所示。在算法执行过程中,有若干个Island并行执行计算,每个Island独立地进行演化,其中各有一个Master和若干Worker,其中Worker负责具体的搜索任务的计算执行,Master负责任务的分配协调以及与其它Island之间的通信等。每隔一定的计算步数,各个Island的Master之间会相同通信,分享搜索过程中获得的知识,从而提升整体的搜索效率。
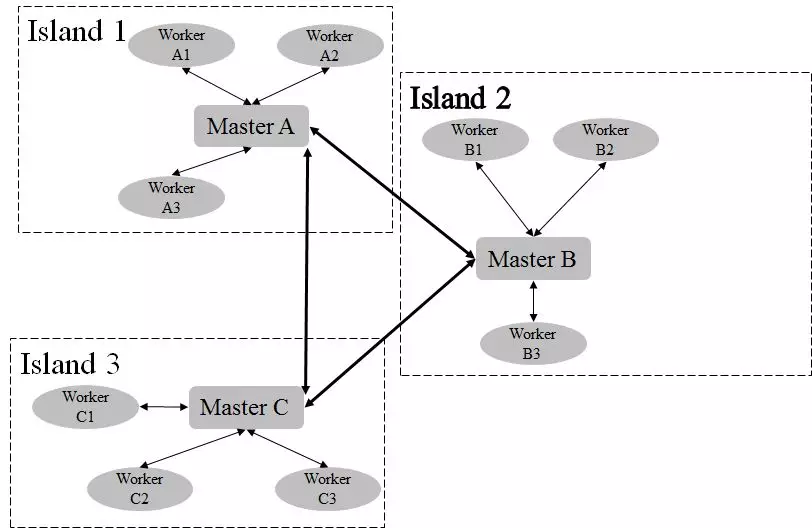
图3 Population Island并行化架构
Parallel Memetic
Parallel Memetic的算法架构如图4所示。整个算法可以分为两个阶段,第一个阶段的计算重点在于减少使用的车辆数(Delete Route),在此阶段中,若干个Worker并行计算,并每隔一定的步数相互通信分享信息。第一阶段结束之后,会获得若干中间结果,将这些结果作为第二阶段中每个Worker上的初始演化种群进行计算。第二阶段的计算重点在于降低车辆行驶距离(Reduce Distance),第二阶段的Worker之间同样有相互通信分享知识的机制,而且可以通过控制演化过程中父代个体的选择机制来进行动态地调节Exploration与Exploitation。
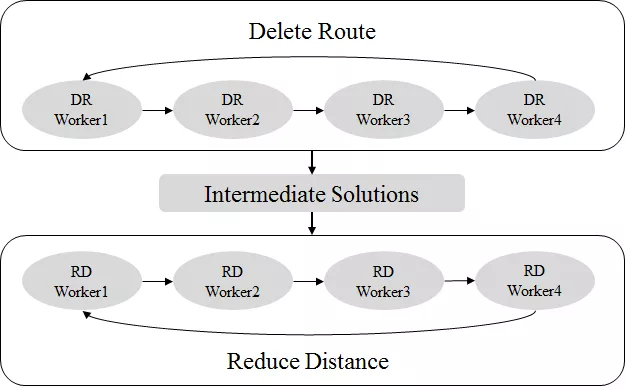
图4 Parallel Memetic并行化架构
Central Pool
Central Pool的算法架构如图5所示。在算法中有若干个Worker负责具体的搜索任务,并将搜索得到的解返回到Central Pool中,由Central Manager对解进行排序、筛选、聚类等处理,然后Central Manager会依据当前Central Pool中的解集情况生成新的计算任务并发送给Worker执行。Central Manager可以对解空间进行合理的刻画,并通过计算任务的管控分配在Exploration与Exploitation之间进行平衡,从而提升求解效率。

图5 Central Pool并行化架构
已获得成果
通过对优化算法的不断迭代升级,以及在工程架构上的更新完善,菜鸟网络的车辆路径规划引擎在服务内外部客户的同时也在技术沉淀上获得了重大成果。
在VRP算法领域,最权威的评测对比平台为欧洲独立研究机构SINTEF发起并管理的世界最好解榜单(Best Known Solution),其中包括了对Solomon数据集(1987年提出)和Gehring & Homberger数据集(1999年提出)共356份测试数据的世界纪录。全世界最顶尖的优化算法学者(例如Jakub Nalepa, D. Pisinger, Yuichi Nagata等)以及优化技术公司(例如Quintiq等)都不断地在此平台上刷新世界纪录,将车辆路径规划领域的技术逐渐地推向极致。
菜鸟网络仓配智能化算法团队在算法研发过程中也一直以此数据集为主要算法评估指标。随着算法的不断升级优化,在越来越多的数据上接近甚至持平世界纪录。
最终,在2018年9月,仓配智能化算法团队的算法终于获得了比世界纪录更好的结果,并经过了平台的验证,向全世界的研究者进行了公开。截止到2019年4月初,菜鸟网络在此评测数据集上共持有48项世界纪录,持有数量在众多研究团队中位居前列,这标志着菜鸟在这项领域的技术进入了世界顶尖水平,为菜鸟和集团赢得了巨大的技术影响力。
总结及展望
在历时两年的研发过程中,菜鸟仓配智能化算法团队的同学们付出了巨大的努力和心血。同时在这个过程中,集团多个事业部的兄弟团队在算法研究、工程技术等方面也提供了很多很好的专业建议,在此表示衷心的感谢!
在之后的工作中,菜鸟仓配智能化算法团队将会把VRP引擎打造成为更强大、稳定、易用的优化产品,为菜鸟和集团的各项业务发展提供技术支持,并有计划地向外输出,为中国的物流行业赋能提效。
作者:何柱、守初、本华
原文链接
本文为云栖社区原创内容,未经允许不得转载。
 关注公众号
关注公众号 低调大师中文资讯倾力打造互联网数据资讯、行业资源、电子商务、移动互联网、网络营销平台。
持续更新报道IT业界、互联网、市场资讯、驱动更新,是最及时权威的产业资讯及硬件资讯报道平台。
转载内容版权归作者及来源网站所有,本站原创内容转载请注明来源。
- 上一篇

Objc Block实现分析
Objc Block实现分析 Block在iOS开发中使用的频率是很高的,使用的场景包括接口异步数据的回调(AFN)、UI事件的回调(BlockKits)、链式调用(Masonry)、容器数据的遍历回调(NSArray、NSDictionary),具体的用法以及使用Block的一些坑这里就不一一赘述了,本文会从源代码的层面分析我们常用的Block的底层实现原理,做到知其然知其所以然。 本文会从如下几个主题切入,层层递进分析Block的底层原理,还原Block本来的面目 无参数无返回值,不使用变量的Block分析 使用自动变量的Block分析 使用__block修饰的变量的Block分析 Block引用分析 无参数无返回值,不使用变量的Block分析 有如下的源代码,创建一个简单的block,在block做的处理是打印一个字符串,然后执行这个block。接下来会从源码入手对此进行分析:block是如何执行的 // 无参数无返回值的Block分析 int main(int argc, const char * argv[]) { void (^blk) (void) = ^{ printf...
- 下一篇
探索Java日志的奥秘:底层日志系统-log4j2
前言 log4j2是apache在log4j的基础上,参考logback架构实现的一套新的日志系统(我感觉是apache害怕logback了)。 log4j2的官方文档上写着一些它的优点: 在拥有全部logback特性的情况下,还修复了一些隐藏问题 API 分离:现在log4j2也是门面模式使用日志,默认的日志实现是log4j2,当然你也可以用logback(应该没有人会这么做) 性能提升:log4j2包含下一代基于LMAX Disruptor library的异步logger,在多线程场景下,拥有18倍于log4j和logback的性能 多API支持:log4j2提供Log4j 1.2, SLF4J, Commons Logging and java.util.logging (JUL) 的API支持 避免锁定:使用Log4j2 API的应用程序始终可以选择使用任何符合SLF4J的库作为log4j-to-slf4j适配器的记录器实现 自动重新加载配置:与Logback一样,Log4j 2可以在修改时自动重新加载其配置。与Logback不同,它会在重新配置发生时不会丢失日志事件。 高级...
相关文章
文章评论
共有0条评论来说两句吧...
文章二维码
点击排行

推荐阅读






最新文章
- SpringBoot2整合Redis,开启缓存,提高访问速度
- Windows10,CentOS7,CentOS8安装MongoDB4.0.16
- Docker使用Oracle官方镜像安装(12C,18C,19C)
- Linux系统CentOS6、CentOS7手动修改IP地址
- CentOS7安装Docker,走上虚拟化容器引擎之路
- CentOS7编译安装Cmake3.16.3,解决mysql等软件编译问题
- Hadoop3单机部署,实现最简伪集群
- Springboot2将连接池hikari替换为druid,体验最强大的数据库连接池
- SpringBoot2初体验,简单认识spring boot2并且搭建基础工程
- CentOS8安装Docker,最新的服务器搭配容器使用
 微信收款码
微信收款码 支付宝收款码
支付宝收款码