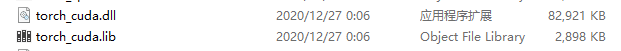Windows环境下老显卡跑PyTorch GPU版本
从pytorch 1.3开始 不再支持GPU的算力在3.5及其以下的显卡。这时,你只能安装1.2版本的官方Pytorch。如果够用就安装它吧,省心省力。但是如果你要用其它包需要更高版本的torch支持,比如:torch geometric需要至少1.4版本。你只能使用官方的CPU版本,因为官方的版本不再直接支持GPU算力3.5以下版本,简化版本的分发(Torch已经很大了)。到了Torch 1.7时,GPU算力至少要达到5.2。 这时,我们需要在Windows上重新编译Pytorch 源码,得到适合自己显卡的Torch。在编译时,系统会自动把GPU算力下限设为当前机器显卡的算力,比如GT 730M 1G 显卡算力为3.5。
参考:https://blog.csdn.net/qq_43051923/article/details/108393510
下面以Torch 1.7为例来说明整个操作过程。
1. 编译工具和第三方库
1.1 Visual studio 2019
原帖子上说最新的VS 2019有点问题,我并没有去证实。但是个人认为,原理上应该不会这样的,或者说不是关键问题。但是我还是按帖子上的说法,安装了16.6.5版本Professional版本。
https://docs.microsoft.com/en-us/visualstudio/releases/2019/history 里面的16.6.5版本。
只需要安装 C++桌面开发即可。
1.2 Cuda toolkit
去Nvidia官网下 https://developer.nvidia.com/cuda-toolkit
下载的版本选择cuda 10.1,cuda_10.1.105_418.96_win10.exe
需要安装NVCC,与Visual Studio相关的插件部分。
1.3 cudnn
这个的安装可以参考windows_cudnn_install. ( https://github.com/pytorch/pytorch/blob/master/.circleci/scripts/windows_cudnn_install.sh)
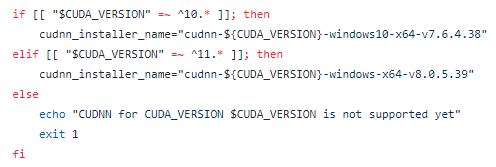
![]()
可以看到对应cuda10.1为v7.6.4.38,即cudnn-10.1-windows10-x64-v7.6.4.38.zip(不断地更新中)
https://developer.nvidia.com/compute/machine-learning/cudnn/secure/7.6.4.38/Production/10.1_20190923/cudnn-10.1-windows10-x64-v7.6.4.38.zip
将文件解压出来后,移动到Cuda toolkit安装路径中。(只是为了简化配置过程中的目录的设定)
1.4 mkl
这个的安装可以参考install_mkl
https://github.com/pytorch/pytorch/blob/master/.jenkins/pytorch/win-test-helpers/installation-helpers/install_mkl.bat
![]()
根据目前的官方文档下载:
https://s3.amazonaws.com/ossci-windows/mkl_2020.0.166.7z
1.5 magma
参考install_magma
https://github.com/pytorch/pytorch/blob/master/.jenkins/pytorch/win-test-helpers/installation-helpers/install_magma.bat
![]()
需要注意的是,要注意区别release和debug版本,如果你想下载cuda110的release版本,就xxx_cuda110_release,否则就是xxx_cuda110_debug。编译的时候release就用release版本,debug就用debug版本
根据目前的官方文档下载:
https://s3.amazonaws.com/ossci-windows/magma_2.5.4_cuda101_release.7z
1.6 sccache
参考install_sccache
https://github.com/pytorch/pytorch/blob/master/.jenkins/pytorch/win-test-helpers/installation-helpers/install_sccache.bat
![]()
根据官方文档下载:
https://s3.amazonaws.com/ossci-windows/sccache.exe
https://s3.amazonaws.com/ossci-windows/sccache-cl.exe
1.7 ninja
下载:ninja-win.zip
https://github.com/ninja-build/ninja/releases
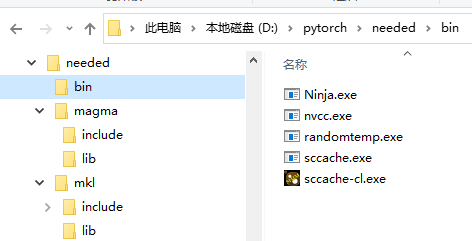
mkl, magma, sccache 和ninja下载解压后最好放在同一个目录下。
![]()
Nvcc和randomtemp.exe先不管它们,后面再说。
1.8 安装Ananconda 或者 miniconda
Torch官方文档推荐使用conda环境。这里我还是使用pip。实践证明没有问题。
1.9 安装python 包
Pip install numpy ninja pyyaml mkl mkl-include setuptools cmake cffi typing_extensions future six requests dataclasses
2. 设置环境变量
生成一个批处理文件进行环境变量的设置。
set -x
set BUILD_TYPE=release
set USE_CUDA=1
set DEBUG=
rem set DEBUG=1 for debug version
set USE_DISTRIBUTED=0
set CMAKE_VERBOSE_MAKEFILE=1
set TMP_DIR_WIN=D:\pytorch\needed\
set CMAKE_INCLUDE_PATH=%TMP_DIR_WIN%\mkl\include
set LIB=%TMP_DIR_WIN%\mkl\lib;%LIB
set MAGMA_HOME=%TMP_DIR_WIN%\magma
rem version transformer, for example 10.1 to 10_1.
set CUDA_SUFFIX=cuda10_1
set CUDA_PATH_V%VERSION_SUFFIX%=%CUDA_PATH%
set CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
set CUDNN_LIB_DIR=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64
set CUDA_TOOLKIT_ROOT_DIR=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
set CUDNN_ROOT_DIR=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
set NVTOOLSEXT_PATH=C:\Program Files\NVIDIA Corporation\NvToolsExt
set CUDNN_INCLUDE_DIR=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\include
set NUMBAPRO_CUDALIB=%CUDA_PATH%\bin
set NUMBAPRO_LIBDEVICE=%CUDA_PATH%\nvvm\libdevice
set NUMBAPRO_NVVM=%CUDA_PATH%\nvvm\bin\nvvm64_33_0.dll
set PATH=%CUDA_PATH%\bin;%CUDA_PATH%\libnvvp;%PATH%
set DISTUTILS_USE_SDK=1
set TORCH_CUDA_ARCH_LIST=3.5
set TORCH_NVCC_FLAGS=-Xfatbin -compress-all
set PATH=%TMP_DIR_WIN%\bin;%PATH%
set SCCACHE_IDLE_TIMEOUT=0
sccache --stop-server
sccache --start-server
sccache --zero-stats
set CC=sccache-cl
set CXX=sccache-cl
set CMAKE_GENERATOR=Ninja
if "%USE_CUDA%"=="1" (
copy %TMP_DIR_WIN%\bin\sccache.exe %TMP_DIR_WIN%\bin\nvcc.exe
:: randomtemp is used to resolve the intermittent build error related to CUDA.
:: code: https://github.com/peterjc123/randomtemp
:: issue: https://github.com/pytorch/pytorch/issues/25393
::
:: Previously, CMake uses CUDA_NVCC_EXECUTABLE for finding nvcc and then
:: the calls are redirected to sccache. sccache looks for the actual nvcc
:: in PATH, and then pass the arguments to it.
:: Currently, randomtemp is placed before sccache (%TMP_DIR_WIN%\bin\nvcc)
:: so we are actually pretending sccache instead of nvcc itself.
:: curl -kL https://github.com/peterjc123/randomtemp/releases/download/v0.3/randomtemp.exe --output %TMP_DIR_WIN%\bin\randomtemp.exe
set RANDOMTEMP_EXECUTABLE=%TMP_DIR_WIN%\bin\nvcc.exe
set CUDA_NVCC_EXECUTABLE=%TMP_DIR_WIN%\bin\randomtemp.exe
set RANDOMTEMP_BASEDIR=%TMP_DIR_WIN%\bin
)
set CMAKE_GENERATOR_TOOLSET_VERSION=14.26
set CMAKE_GENERATOR=Visual Studio 16 2019
"C:\Program Files (x86)\Microsoft Visual Studio\2019\Professional\VC\Auxiliary\Build\vcvarsall.bat" x64 -vcvars_ver=14.26
注意几点:
1)如果编译的是Cuda10的话,原帖上说:“set TORCH_CUDA_ARCH_LIST=3.7+PTX;5.0;6.0;6.1;7.0;7.5;8.”TORCH_CUDA_ARCH_LIST要去掉 8.0。
我这里直接设定为3.5。这里设定的就是算力下限。
2)编译debug/release版本是,下载对应的Magma debug/release版本包
3) 如果只编译CPU版本的话,设置USE_CUDA=0
4)这里将randomtemp.exe直接下载到本地。
5)脚本会自动复制nvcc.exe到设定目录。它是编译gpu代码的工具。
6)关闭了分布式训练的功能。set USE_DISTRIBUTED=0
3. 准备Torch源码
根据Torch官方文档:
Get the PyTorch Source
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
# if you are updating an existing checkout
git submodule sync
git submodule update --init –recursive
这里—recursive是递归下载Torch依赖的第三方git库。这里存在的问题是,在国内连接github的速度并不稳定,为了以免下载的源码出问题,我选择下载zip打包后的源码。
注:直接在github上进行下载是最方便的。 只是需要几个小时的时间,下载的速度只有20~50k/s,下载整个项目需要数个小时时间。(项目有600M以上,我没有坚持下载完全。中途断线了)
![]()
性子急的,才用下面的方法。快,但需要细心。
重要的地方是,这种打包下载是不能自动下载Torch所依赖的第三方库。只能自己手动下载与Torch版本所对应的第三方库。(与当前准备编译Torch版本所对应的第三方库,这很重要,泪!)
通过Tag标签,找到自己准备编译的1.7版本。
![]()
![]()
下载打包后的源码。
![]()
https://github.com/pytorch/pytorch/archive/v1.7.0.zip
这个也可以到国内的Gitee镜像站下载。可以直接在国内Gitee上使用指令git clone –recursive(我没有实验过,但是原理上是可行的。但是下载第三方库时,依然会访问github上的库)
https://gitee.com/mirrors/pytorch?_from=gitee_search
然后,进入Torch 1.7.0 分支的third_party。下载它所依赖的第三方库。
https://github.com/pytorch/pytorch/tree/v1.7.0/third_party
![]()
一共36个库文件。我全部下载的打包zip源码。
- 其中fbgemm库是一个关键库,它又依赖了三个其它的第三方库。
![]()
请注意它们之间版本对应关系(到github上看清楚上面的版本链接)。
![]()
对于Torch,FBGEMM不一定对应是最新版本。不同版本函数接口不一样,会导致编译的失败。
另外,ideep也依赖于自己的第三方库mkl-dnn @ 5ef631a。这也是一个关键的库。
最后,把全部源码根据Git上的形式整合到一起。这时源码全部准备好了。
(注意:由于手动整合源码,主要问题是确保各个第三方库版本与当前的Torch版本是配合的。是配合的。是配合的。)如果直接在网上git下载源码,就不会存在版本不对的问题,但是有可能下载不动,或者残缺的风险。
自己动手,丰衣足食!
4. 开始编译
请使用Powershell terminal, 而不要使用cmd。(在cmd中,中文的显示有问题。万一编译出错,你都不知道它在说什么)。也不需要管理员权限。给它也行。
进入Powershell terminal,首先运行前面生成批处理文件./set_env.bat,进行环境变量的设置。
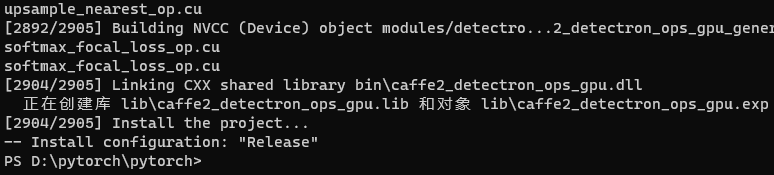
然后,编译libtorch。
python tools\build_libtorch.py
我只进行了库文件的编译。在i5-4200M的机器上,整个编译过程近6个小时,生成12G左右的临时文件和编译文件。
![]()
(注意:不要尝试在VS环境下直接cmake和编译库,因为官方脚本还做了其它事情)
5. 移花接木
到官方网站下载 1.7 GPU cu101版本。
![]()
安装后,用自己编译生成的两个库文件,替换掉官方提供的。下面官方的cuda有600M。
![]()
自己生成的只有它的八分之一。当然,也没有了分布式训练功能,因为前面没有选择它。
![]()
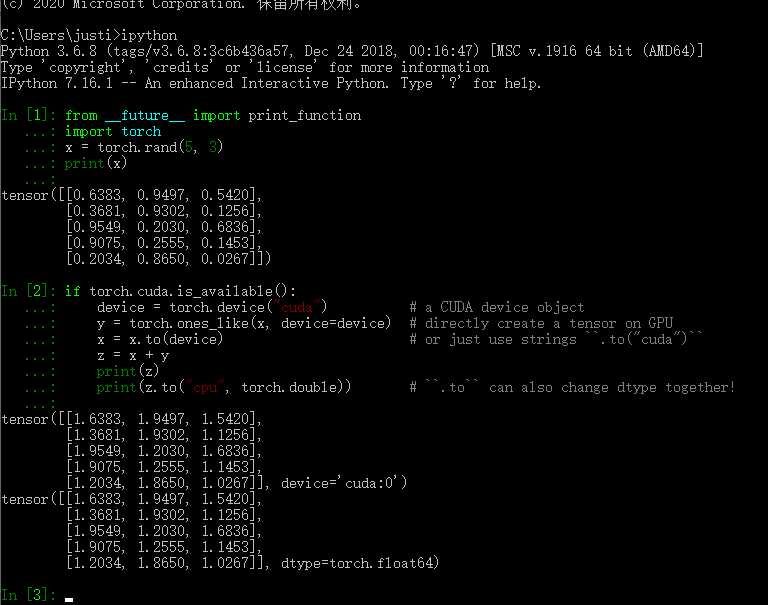
再进行一下测试。
![]()
KO!(理论上,用自己生成的库可以全部替换掉官方的,大家可以自己实验)目前已经用了近3个月 没有发现什么问题。