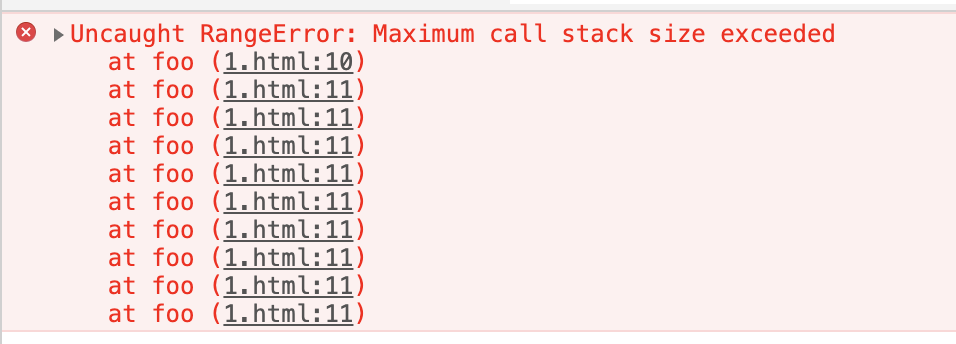
新的对象会首先被分配到 from 空间,当进行垃圾回收的时候,会先将 from 空间中的 存活的对象复制到 to 空间进行保存,对未存活的对象的空间进行回收。复制完成后, from 空间和 to 空间进行调换,to 空间会变成新的 from 空间,原来的 from 空间则变成 to 空间。这种算法称之为 ”Scavenge“。
Scavenge 算法
新生代内存回收频率很高,速度也很快,但是空间利用率很低,因为有一半的内存空间处于"闲置"状态。
老生代内存回收
新生代中多次进行回收仍然存活的对象会被转移到空间较大的老生代内存中,这种现象称为晋升。以下两种情况
在垃圾回收过程中,发现某个对象之前被清理过,那么将会晋升到老生代的内存空间中
在 from 空间和 to 空间进行反转的过程中,如果 to 空间中的使用量已经超过了 25% ,那么就讲 from 中的对象直接晋升到老生代内存空间中。
Nacos /nɑ:kəʊs/ 是 Dynamic Naming and Configuration Service 的首字母简称,一个易于构建 AI Agent 应用的动态服务发现、配置管理和AI智能体管理平台。Nacos 致力于帮助您发现、配置和管理微服务及AI智能体应用。Nacos 提供了一组简单易用的特性集,帮助您快速实现动态服务发现、服务配置、服务元数据、流量管理。Nacos 帮助您更敏捷和容易地构建、交付和管理微服务平台。
Rocky Linux(中文名:洛基)是由Gregory Kurtzer于2020年12月发起的企业级Linux发行版,作为CentOS稳定版停止维护后与RHEL(Red Hat Enterprise Linux)完全兼容的开源替代方案,由社区拥有并管理,支持x86_64、aarch64等架构。其通过重新编译RHEL源代码提供长期稳定性,采用模块化包装和SELinux安全架构,默认包含GNOME桌面环境及XFS文件系统,支持十年生命周期更新。
Sublime Text
Sublime Text具有漂亮的用户界面和强大的功能,例如代码缩略图,Python的插件,代码段等。还可自定义键绑定,菜单和工具栏。Sublime Text 的主要功能包括:拼写检查,书签,完整的 Python API , Goto 功能,即时项目切换,多选择,多窗口等等。Sublime Text 是一个跨平台的编辑器,同时支持Windows、Linux、Mac OS X等操作系统。

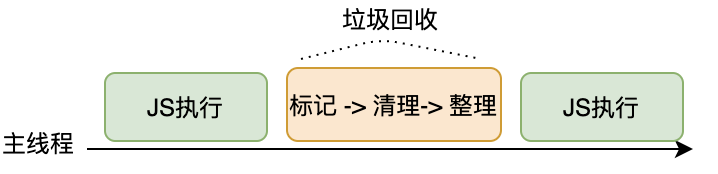
 通俗理解,就是把垃圾回收这个大的任务分成一个个小任务,穿插在 JavaScript任务中间执行,这个过程其实跟 React Fiber 的设计思路类似。
通俗理解,就是把垃圾回收这个大的任务分成一个个小任务,穿插在 JavaScript任务中间执行,这个过程其实跟 React Fiber 的设计思路类似。