
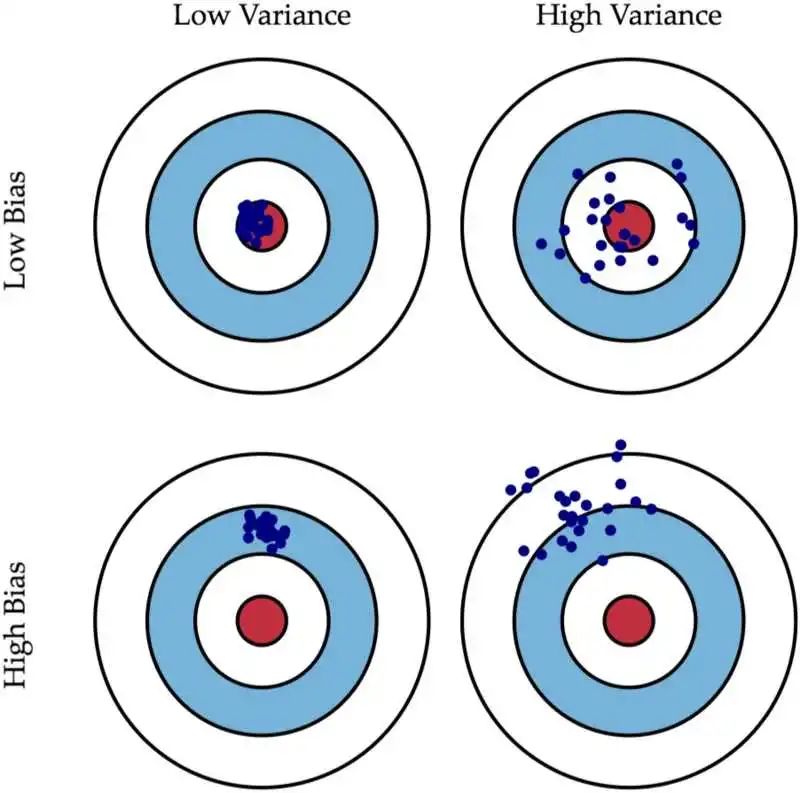
 这个图中,左上角是低偏差低方差的,可以看到所有的预测值,都会落在靶心,完美模型;
这个图中,左上角是低偏差低方差的,可以看到所有的预测值,都会落在靶心,完美模型;



【框架】122:spring框架之注解
今天是刘小爱自学Java的第122天。 感谢你的观看,谢谢你。 学习内容安排如下: Spring注解的使用。 JavaWeb项目的搭建。 Spring的Web集成。 本来还计划学Spring的junit测试集成的,结果又没时间了。 一、Spring的注解 IoC容器是Spring的特色之一,可以使用它管理很多Bean,前几天我们都是将这些Bean配置在applicationContext.xml文件中的。 而注解的作用在于:用了注解之后,就不需要在xml文件中配置这些了 。 1开启注解 ①开启spring的注解 context:annotation-config 让注解有效了,能够识别注解。 ②配置注解扫描 context:component-scan 用来专门扫描含有@Component注解的类,自动将其作为bean。 base-package 要扫描包的路径,包含子包,com.liuxiaoai表示该包下的所有子包和类定义注解都有效. 注意:注解扫描配置的时候,会自动开启注解功能,也就是说有了②的话,①就不需要了。 如果是注解+XML组合使用,可以只开启①。 2注解的使用 ①@Co...