本文是Ignite数据加载入门系列文章的第一篇,会介绍开发人员、分析人员和运维人员可以使用的Ignite数据加载功能,在后面的两篇文章中,会介绍Ignite进行数据加载的两种主要技术:CacheStore和DateStreamer。
数据加载功能和Ignite的部署模式强相关,每个加载方式都有其优点和成本,这也使得用户在不同的场景会做出不同的选择。
Ignite的数据加载功能
Ignite提供了若干种功能,用于从外部数据源加载数据,下面会逐一介绍。
CacheStore
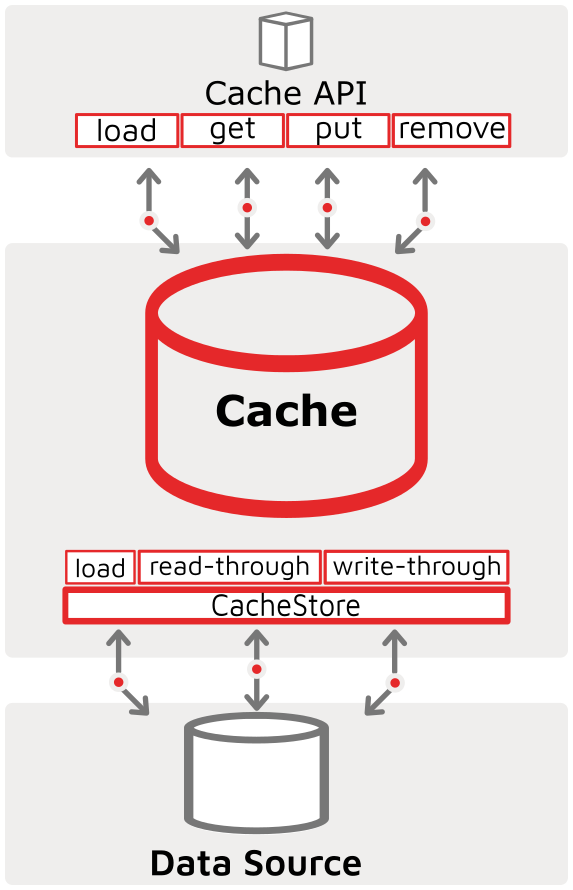
CacheStore是数据网格(IMDG)方案中用于与外部或第三方持久化存储进行同步的主要工具。Ignite的CacheStore接口实现了缓存的通读和通写功能,另外CacheStore接口还具有缓存加载方法,可用于在初始化时热加载缓存(不仅限于在启动时执行)。API-Cache-CacheStore-DataStore关系的图形表示如下所示,突出显示了通读、通写和缓存加载功能: ![]()
Ignite自带了很多CacheStore接口的实现,可将Ignite缓存与外部数据源(如RDBMS、Hibernate、NoSQL系统(如Cassandra)和其他自定义第三方系统)进行同步。这些实现将确保从KeyValue或SQL API进行的所有创建(缓存put新数据或SQL的INSERT)或更新(缓存put,SQL的UPDATE)或删除(缓存remove,SQL的DELETE)操作都将同步到第三方系统,它还为从数据源进行缓存热加载提供了一种手段。
数据流
IgniteDataStreamer API和在此基础上构建的各种流处理器目的是将大量连续的数据注入Ignite中。数据流以可伸缩和容错的方式构建,并为注入Ignite的所有数据提供至少一次保证的语义。
针对很多既有的系统,Ignite自带了很多直接可以用的流处理器,比如Kafka、JMS、MQTT等等。
put/putAll/SQL INSERT API
通常应用与Ignite缓存/表进行交互的方式是缓存的put/putAll和SQL API,它们也适用于将数据注入到缓存中。虽然putAll API的速度明显快于多个puts的速度,但是要显著慢于IgniteDataStreamer,因此通过这些API进行的数据加载通常用于增量数据加载。
SQL API通过其SET STREAMING [ON|OFF]选项支持集成流。这时SQL INSERTS将由JDBC/ODBC驱动进行批处理,并在整个集群节点集合中异步执行以实现最大吞吐量。
工具/应用
随着诸如JDBC/ODBC之类的通用接口的广泛使用,也会有更多的工具可用于数据加载。Ignite自带了SQLLine,支持通过COPY命令直接从文件加载数据: ![]()
其他ETL工具(例如Informatica和Talend)也是通过ODBC/JDBC进行数据加载的备选方案。
数据加载流程
当使用Ignite的原生客户端以及服务端API时,有两个主要的数据加载流程:
客户端将数据传输到服务端
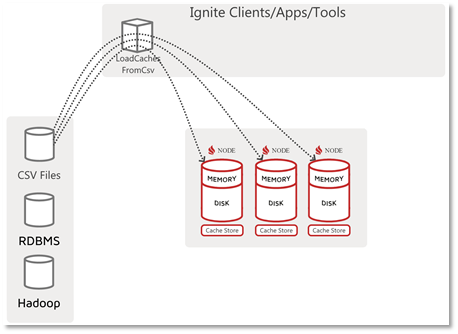
在大多数场景中,这可以视为标准的数据加载流程。这时执行加载的代理访问并读取数据源,然后将其写入数据库(即Ignite服务端节点/集群),该流程的示意图如下: ![]()
在上图中,针对特定的数据源(在本例中为CSV文件)编写了一个Ignite客户端应用,名为LoadCachesFromCsv,它知道如何访问和获取或接收数据,然后该应用还负责将数据写入或”装载“到集群中。在此数据加载流程中,可以使用任何Ignite写入API,put()、putAll()、SQL INSERT等,但Ignite DataStreamer也适用于这个场景并且性能最好。
客户端通知服务端加载数据
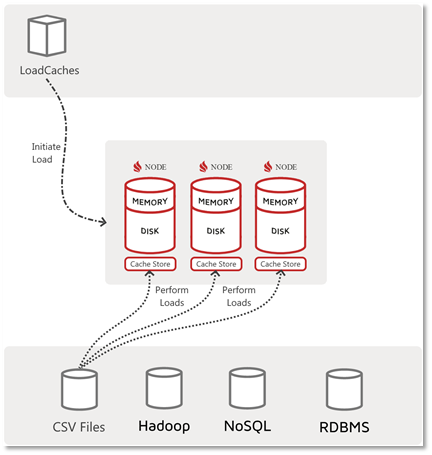
另一种数据加载流程是客户端仅通知服务端加载数据的流程(也许带有参数,指示要从何处获取哪些数据),该流程的示意图如下所示: ![]()
如上所示,LoadCache应用仅“启动”加载,但实际上的加载逻辑和数据移动发生在驻留CacheStore的集群节点上。
数据加载流程比较
在这两种加载流程(基于客户端的数据加载和通过客户端发出通知的服务端数据加载)中,可以看到在第一种模式中,客户端承担了相对于当前有效源数据的所有责任,比如上下文、数据访问、安全性、网络可见性等。这有其好处,因为只有客户端节点才需要访问数据,并且可以充当源系统和目标集群之间的代理,从而使集群免于直接外部访问。但是,当客户端执行加载时,它必须自己读取所有数据并写入集群(这可能还需要将数据重新分配给正确的目标节点)。
对于客户端只发出信号而服务端执行数据加载的方式,则可以利用服务端集群的功能和上下文。这时集群节点可能是网络中唯一配置了连接和安全参数以到达源数据的代理。另外如果数据和目标数据分区适合于并置加载,还可以按节点划分加载,每个节点仅加载归属该节点的分区的数据,这获得了巨大的可伸缩性优势(即每个节点都可以处理一部分,并可以水平扩展到所有节点),更多的细节请参见分区感知的数据加载文档。需要注意的是,如果无法进行分区感知加载,则存在数据读取IO的重复,因为每个节点将读取所有的数据并丢弃不属于本地节点的那些记录。
在本系列的后面两篇文章中,会针对CacheStore和IgniteDataStreamer这两种数据加载方式分别举例详细介绍。