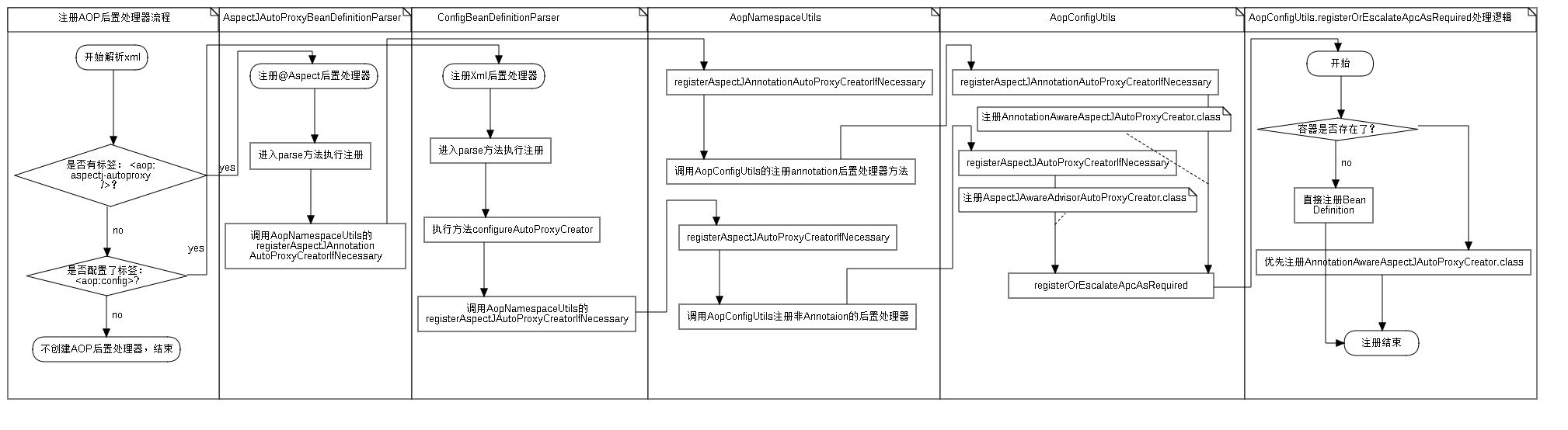
AOP面向切面编程是Spring一个重要的概念,当我们了解到他的使用后,我们还需要知道他的原理。在上一篇中,我们知道,要使用AOP面向切面编程有两种方式来实现,一种是XML文件配置方式,而另外一种则是通过注解的方式来实现。我们使用这两种方式都会自动开启AOP代理的自动检测,就是使用AOP面向编程会去注册一个AOP代理的后置处理器来自动将需要被代理对象包装成一个代理对象。而今天的重点就是这个后置处理器的注册。整个的注册流程如下: ![]()
自定义节点的处理器
在这篇文章讲到了spring的xml文件的节点是分成两类的,一类叫主节点而另外一类叫自定义节点,aop这种节点就被归类成自定义节点,自定义节点都有通用的handler类来处理,handler里面定义了各种节点的解析器,我们来看下aop节点的handler类:
public class AopNamespaceHandler extends NamespaceHandlerSupport {
@Override
public void init() {
// In 2.0 XSD as well as in 2.1 XSD.
registerBeanDefinitionParser("config", new ConfigBeanDefinitionParser());
registerBeanDefinitionParser("aspectj-autoproxy", new AspectJAutoProxyBeanDefinitionParser());
registerBeanDefinitionDecorator("scoped-proxy", new ScopedProxyBeanDefinitionDecorator());
// Only in 2.0 XSD: moved to context namespace as of 2.1
registerBeanDefinitionParser("spring-configured", new SpringConfiguredBeanDefinitionParser());
}
}
从init方法里面定义了我们两种方式的解析器,config节点对应的解析器是ConfigBeanDefinitionParser,而注解的方式的aspectj-autoproxy节点对应的解析器是AspectJAutoProxyBeanDefinitionParser,这2个解析器相同的地方就是会都去注册一个后置处理器,当然他们注册的后置处理器是不一样的,对于ConfigBeanDefinitionParser还有个任务就是注册切面bean definition等操作。对照着上面的图的注册流程,我们分别来看这两个解析器,看下发生了什么事情?
在xml文件里配置了aop节点后发生了什么事
假如我们配置了aop的config节点后,就会进入到ConfigBeanDefinitionParser的解析器,入口是ConfigBeanDefinitionParser的parse方法如下:
public BeanDefinition parse(Element element, ParserContext parserContext) {
CompositeComponentDefinition compositeDef =
new CompositeComponentDefinition(element.getTagName(), parserContext.extractSource(element));
parserContext.pushContainingComponent(compositeDef);
//这是重点,这里就是注册AOP后置处理器的操作
configureAutoProxyCreator(parserContext, element);
//下面是普通的节点的解析,注册bean definition操作为后续的实例化做准备
List<Element> childElts = DomUtils.getChildElements(element);
for (Element elt: childElts) {
String localName = parserContext.getDelegate().getLocalName(elt);
if (POINTCUT.equals(localName)) {
parsePointcut(elt, parserContext);
}
else if (ADVISOR.equals(localName)) {
parseAdvisor(elt, parserContext);
}
else if (ASPECT.equals(localName)) {
parseAspect(elt, parserContext);
}
}
parserContext.popAndRegisterContainingComponent();
return null;
}
在这个方法里面,注册aop后置处理器的操作是在方法configureAutoProxyCreator里完成的,而下面的只是将节点解析成bean definition并注册的操作步骤,有兴趣可以自己看。那么到底如何注册后置处理器以及注册的后置处理器是什么样的呢?继续看这个方法:
//注册切面代理
private void configureAutoProxyCreator(ParserContext parserContext, Element element) {
AopNamespaceUtils.registerAspectJAutoProxyCreatorIfNecessary(parserContext, element);
}
我们继续跟到最里层,我们会发现这样一句代码,这就是注册后置处理器的最终代码如下:
public static BeanDefinition registerAspectJAutoProxyCreatorIfNecessary(
BeanDefinitionRegistry registry, @Nullable Object source) {
return registerOrEscalateApcAsRequired(AspectJAwareAdvisorAutoProxyCreator.class, registry, source);
}
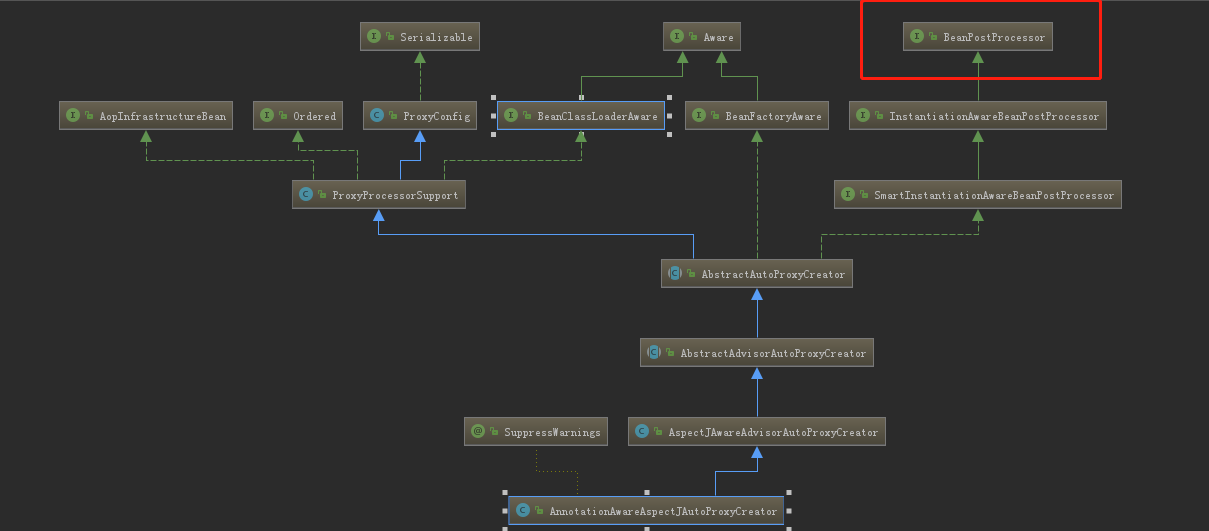
从上面代码,最终注册的后置处理器是AspectJAwareAdvisorAutoProxyCreator类,为什么叫他后置处理器呢,我们看下他的结构,结构如下图:
![]()
他实现了BeanPostProcessor接口,这也是为什么叫他后置处理器,BeanPostProcessor接口的作用其实就是对实例化后的对象进行修改,如包装成代理对象,而这个AspectJAwareAdvisorAutoProxyCreator类就是将被通知的对象包装成代理对象。至此,我们就知道了当我们配置了切面以及通知的时候,这些切面和通知是怎么自动被检测并运用于被代理对象中,其实就是通过后置处理器实现的。 当我们注册完后置处理器后,spring在实例化bean的时候就会自动的去调用后置处理器进行判断,并将需要被代理的对象包装成代理并返回。 更加详细的对BeanPostProcessor的介绍可以看这篇Spring源码解析-BeanPostProcessor。
aop:aspectj-autoproxy节点的作用
前面讲的是用xml去定义切面的,spring还提供注解的方式来定义切面,但是并不是直接用注解定义了个切面他就会生效的,这时候需要让容器能检测到切面类,所以就必须开启aop注解功能,需要在xml配置文件中定义如下一句代码:
<aop:aspectj-autoproxy />
这样子aop的注解才能生效,不然是不能生效的,那加入上面这句代码后spring做了些什么事情呢?跟上面的用config配置aop一样,这个注解也会有个解析器去解析处理该节点,就是在上文提到的类AspectJAutoProxyBeanDefinitionParser,同样解析的入口也是parse方法,如下方法内容:
public BeanDefinition parse(Element element, ParserContext parserContext) {
//注册aop注解的后置处理器
AopNamespaceUtils.registerAspectJAnnotationAutoProxyCreatorIfNecessary(parserContext, element);
extendBeanDefinition(element, parserContext);
return null;
}
同样的我们跟到里面,里面关键代码如下:
@Nullable
public static BeanDefinition registerAspectJAnnotationAutoProxyCreatorIfNecessary(
BeanDefinitionRegistry registry, @Nullable Object source) {
//注册aop注解的后置处理器
return registerOrEscalateApcAsRequired(AnnotationAwareAspectJAutoProxyCreator.class, registry, source);
}
跟config一样,注解的aop后置处理器是AnnotationAwareAspectJAutoProxyCreator这个类,我们来看下他的结构如下, ![]()
他也是实现了BeanPostProcessor,也会在容器实例化bean后调用这个后置处理器进行代理的包装并返回。
两个AOP代理后置处理器优先级
上面我们提到了两个后置处理器一个是AnnotationAwareAspectJAutoProxyCreator,另外一个是AspectJAwareAdvisorAutoProxyCreator问题来了,就是如果我两个都配置了,spring是不是两个都注册了?答案是否定的,spring只会注册一个aop代理后置处理器,而且会优先注册AnnotationAwareAspectJAutoProxyCreator这个后置处理器,看下registerOrEscalateApcAsRequired方法里面到底做了什么处理:
private static BeanDefinition registerOrEscalateApcAsRequired(
Class<?> cls, BeanDefinitionRegistry registry, @Nullable Object source) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
//判断容器是否注册了aop代理后置处理器
if (registry.containsBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME)) {
BeanDefinition apcDefinition = registry.getBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME);
//如果待注册的aop处理器跟已注册的aop处理器不一致,就判断优先级来优先注入
if (!cls.getName().equals(apcDefinition.getBeanClassName())) {
//查找优先级,高优先级的优先注册
int currentPriority = findPriorityForClass(apcDefinition.getBeanClassName());
int requiredPriority = findPriorityForClass(cls);
if (currentPriority < requiredPriority) {
apcDefinition.setBeanClassName(cls.getName());
}
}
return null;
}
//容器没有则直接注册
RootBeanDefinition beanDefinition = new RootBeanDefinition(cls);
beanDefinition.setSource(source);
beanDefinition.getPropertyValues().add("order", Ordered.HIGHEST_PRECEDENCE);
beanDefinition.setRole(BeanDefinition.ROLE_INFRASTRUCTURE);
registry.registerBeanDefinition(AUTO_PROXY_CREATOR_BEAN_NAME, beanDefinition);
return beanDefinition;
}
从上面很清楚的知道,aop后置处理器的definition的注册是有优先级的,而且会优先注册AnnotationAwareAspectJAutoProxyCreator,因为AnnotationAwareAspectJAutoProxyCreator包括了对xml文件的定义的切面的检测,而AspectJAwareAdvisorAutoProxyCreator并没有检测注解的切面。这2个后置处理器的注册,其实是比较简单的,讲这2个是为了后面了解spring是如何将一个普通的类包装成aop代理,这2个类就是入口。明白这2个类就知道了AOP切面是怎么被发现,以及哪些对象需要被包装成代理的流程都是在这2个类里面,待续...