![]()
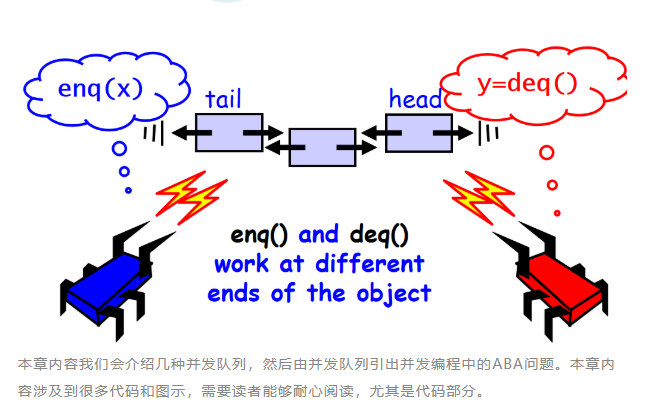
队列很容易体现生产者,消费者模式,生产者和消费者往往都会同时存在多个,这就涉及到了队列的并发访问问题。队列提供了先进先出(FIFO)的公平性保证。
队列一般会提供两个函数:
1. enq(x) : 将元素 x 放入到队列的尾部。
2. deq() : 移除并返回队列中最前面的元素。
队列的函数可以是完全、部分或同步的:
若一个函数的调用不需要等待某个条件成立,则称该函数是完全的。
若一个函数的调用需要等待某个条件成立,则称该函数是部分的。
若一个函数需要等待另一个函数与它的调用间隔相重叠,则称该函数是同步的。例如,在一个同步队列中,一个向队列中添加元素的函数调用将被阻塞直到该增加的元素被另一个函数调用取走。
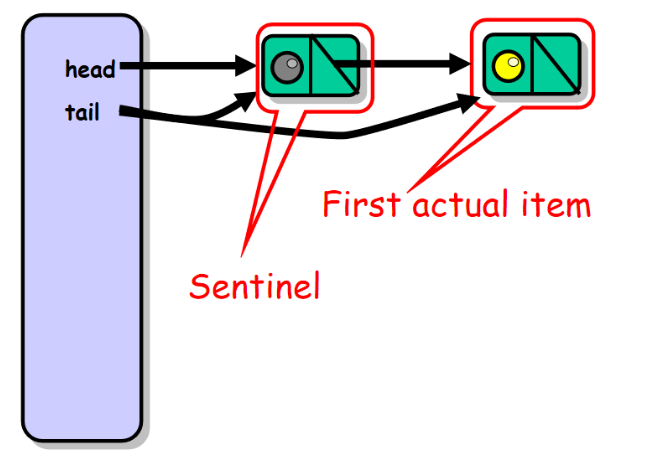
为了保持本章代码示例的简单性,我们假设不允许向队列中存放 null 值。将head域设置为我们的哨兵节点用来标识队列中的头位置。
![]()
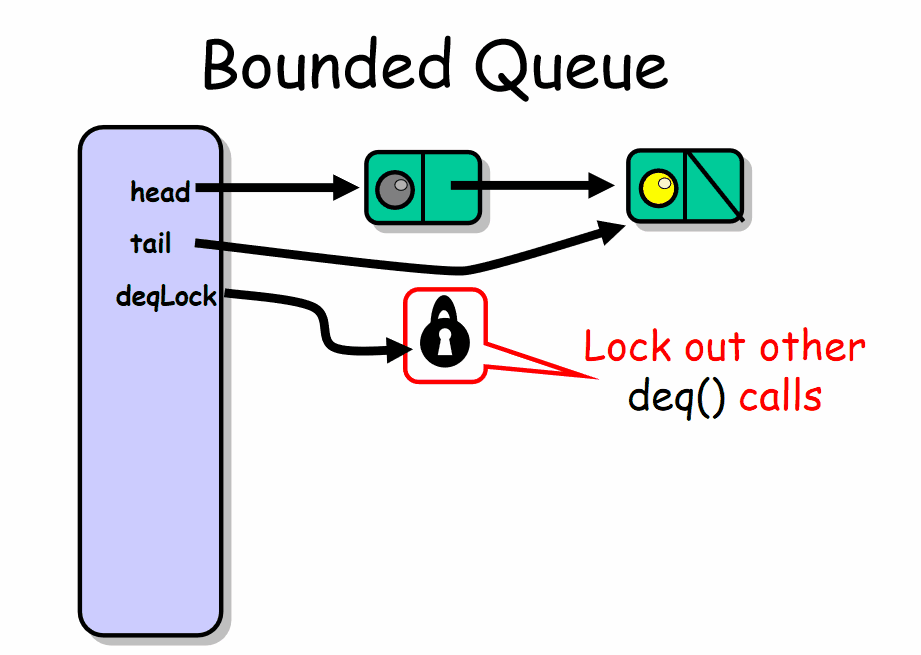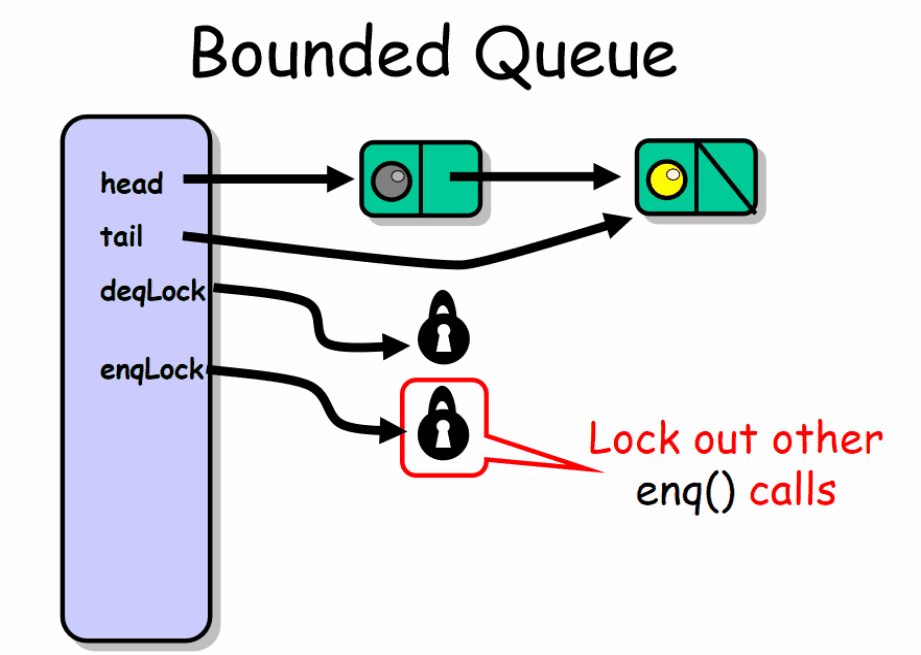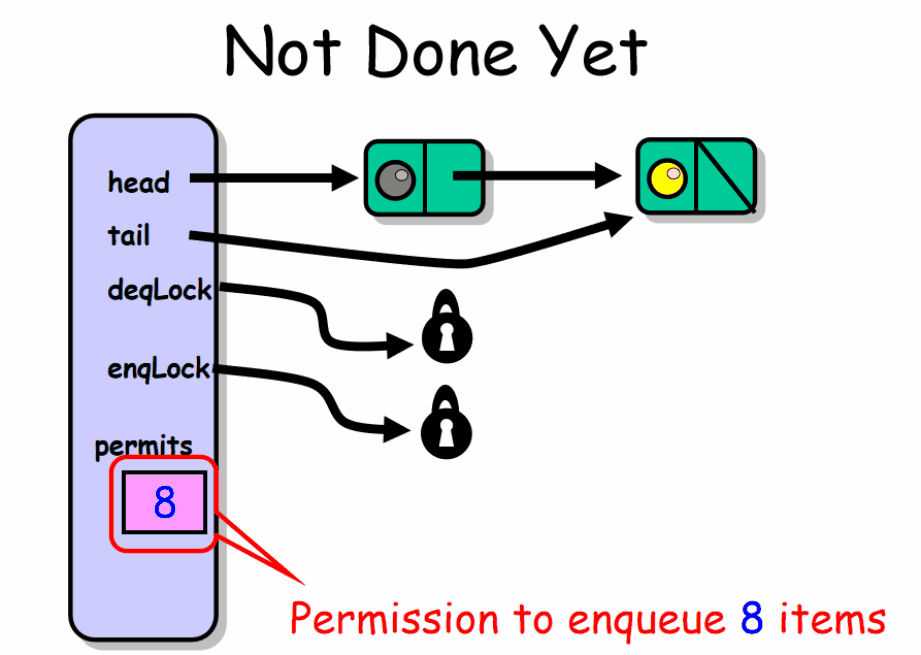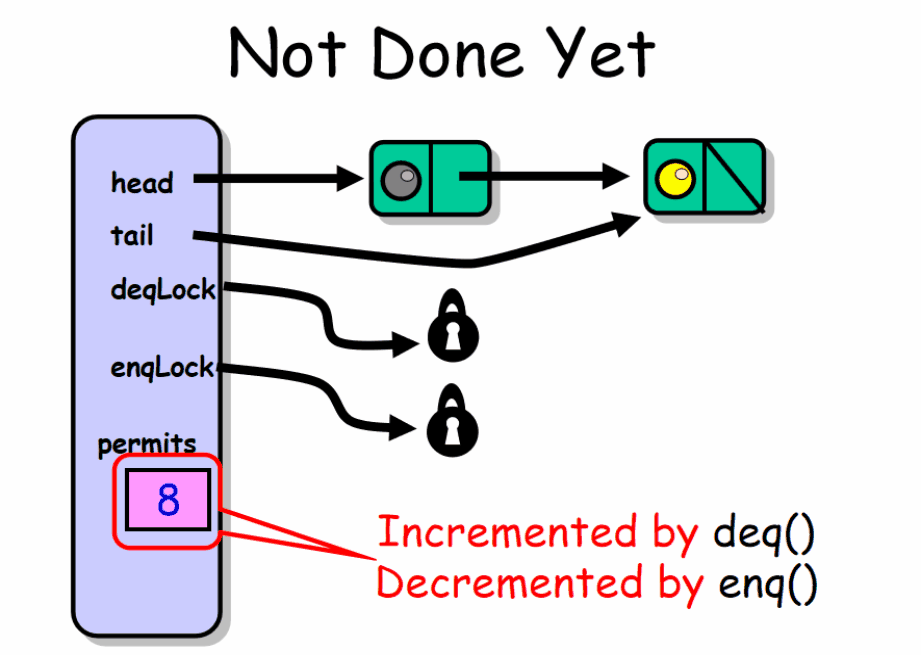
部分有界队列
有界队列存放有限个数的元素,该界限称为容量。在有界队列中只要队列没有满或者不为空,enq() 和 deq() 操作一般都可以无干扰的进行。但是并发的 enq() 之间会互相干扰,并发的 dep() 之间也会互相干扰。
![]()
分别使用 enqLock , deqLock 两个不同的锁来保证在一个时刻最多只有一个入队者和一个出队者可以访问队列。入队者和出队者使用不同的锁保证了他们之间不会出现相互争抢锁。enqLock 与 notFullCondition 条件相关联,当队列不满的时候,用来通知被阻塞等待的入队者。depLock 与 notEmptyCondition 条件相关联,当队列不为空的时候,用来通知被阻塞等待的出队者。
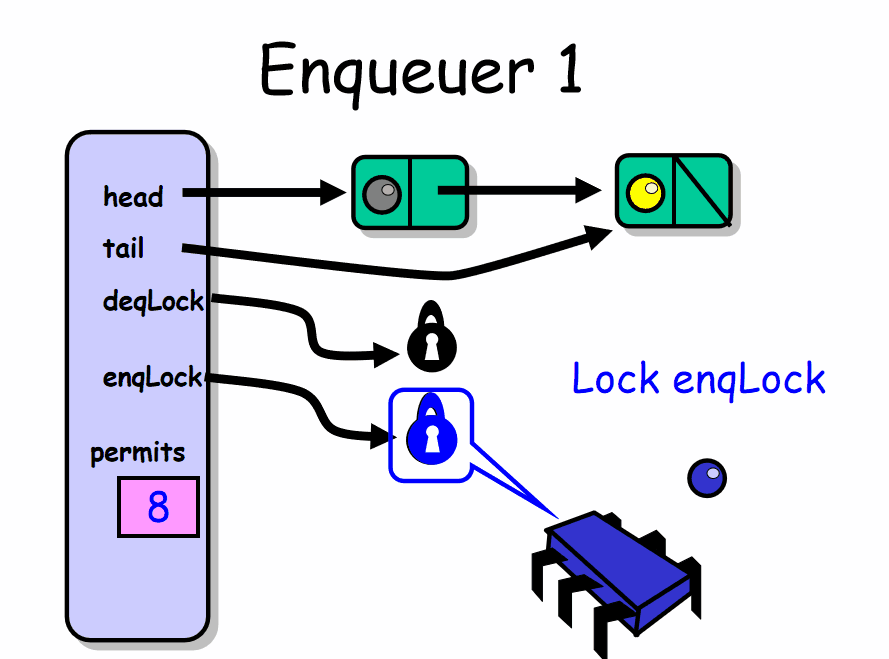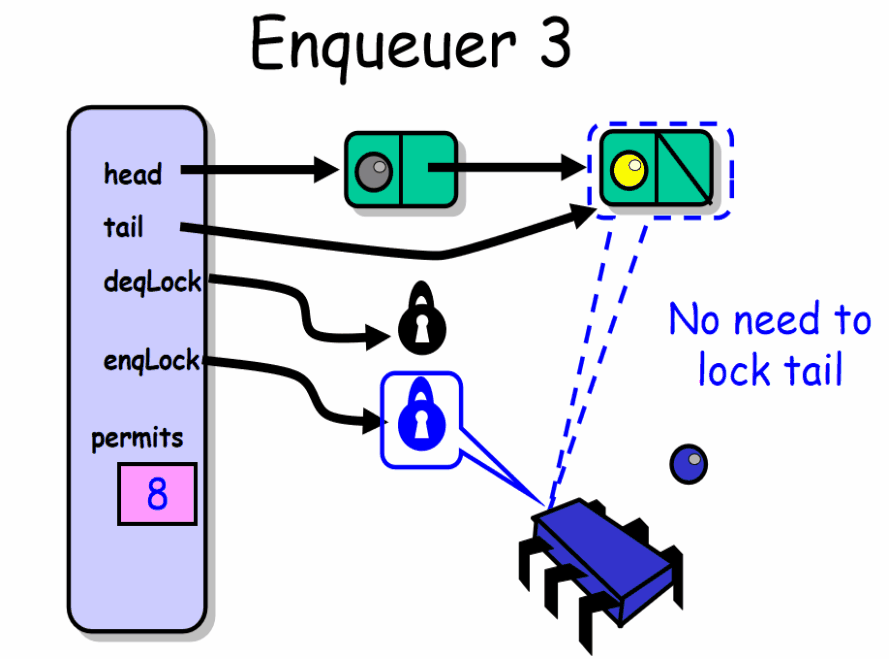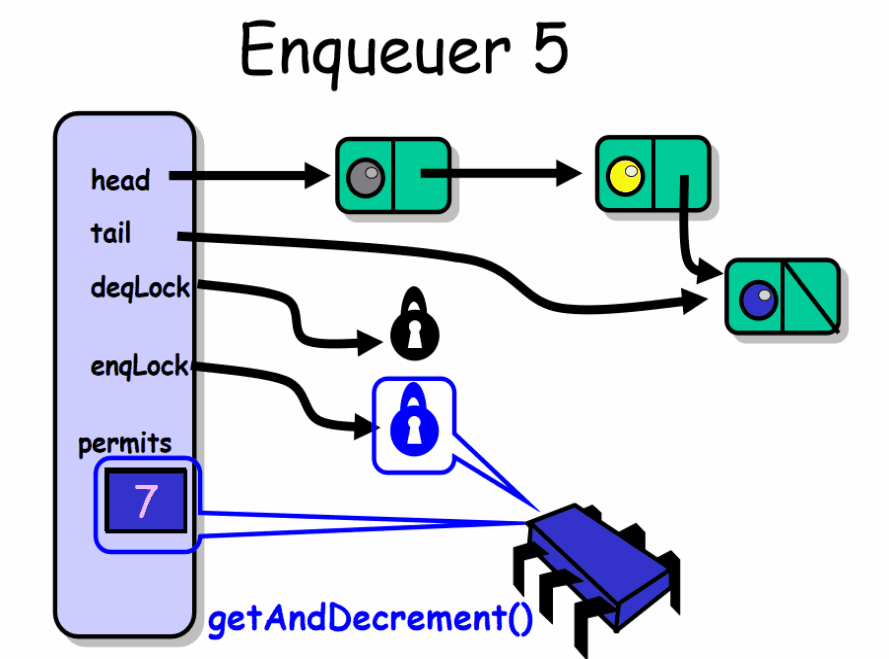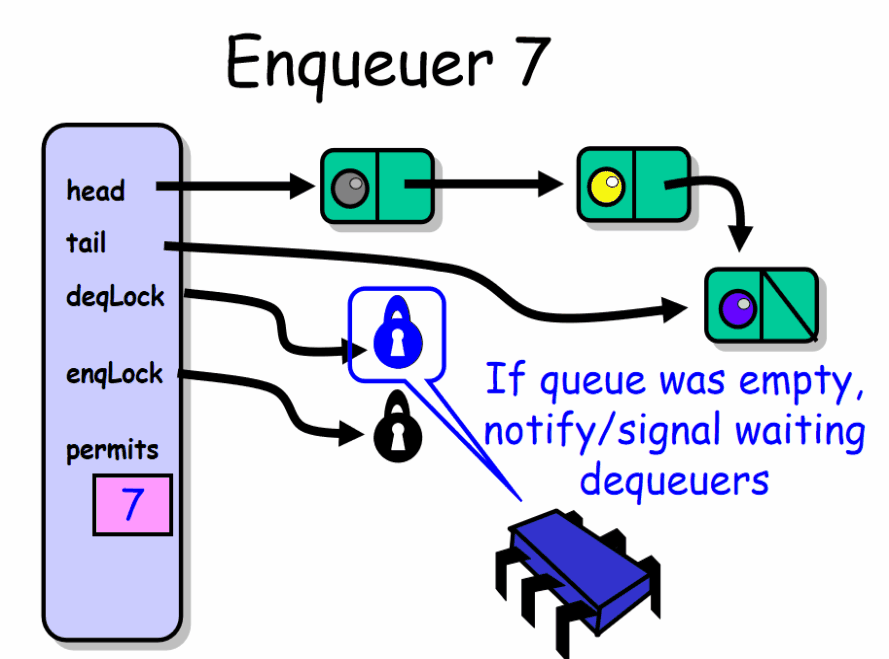
入队者如何工作:
enq() 入队者正常推进的前提是队列中有空槽位。线程首先获得 enqLock 锁,然后检查 permits 域。如果该域等于 0 说明此时队列是满的已经没有可用的槽位,该入队者必须等待直到出队者产生一个空槽位。入队者在 notFullCondition 条件上等待,暂时释放了 enqLock 锁,等待条件信号产生。每当入队者被唤醒,就会再次检查是否有空槽位,如果没有就继续等待。如果队列中有空槽位就会产生一个新节点,放到队列的尾部。最后会根据队列中是否还有节点来决定是否唤醒出队者。
![]()
出队者如何工作:
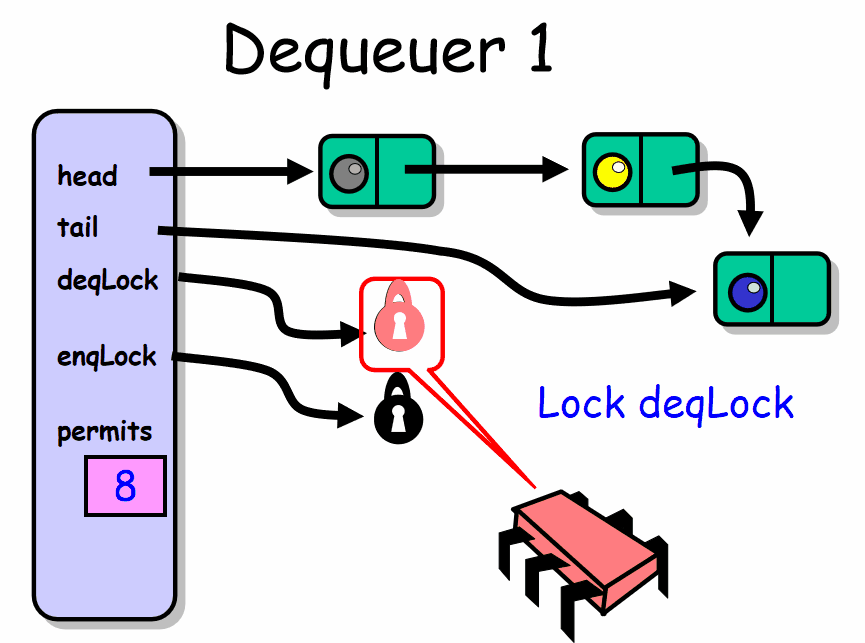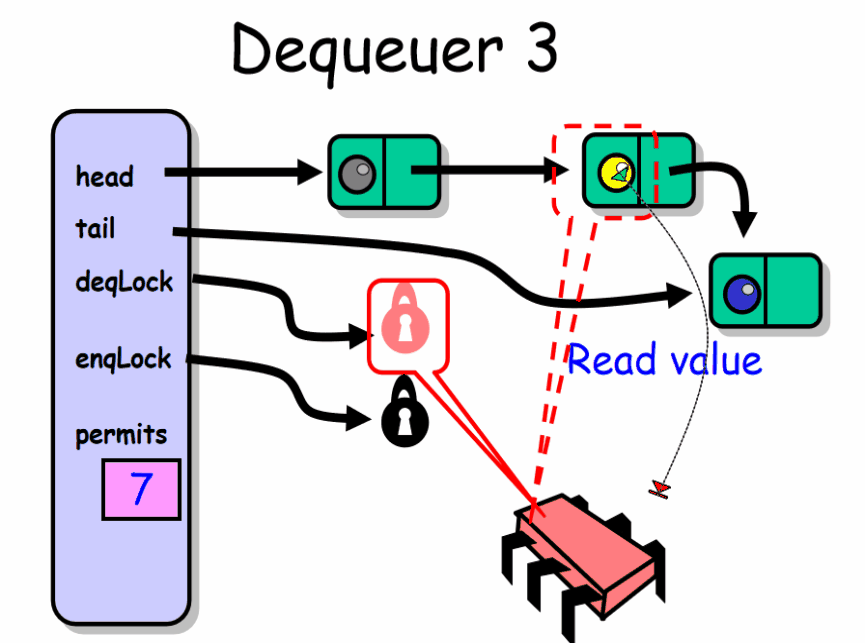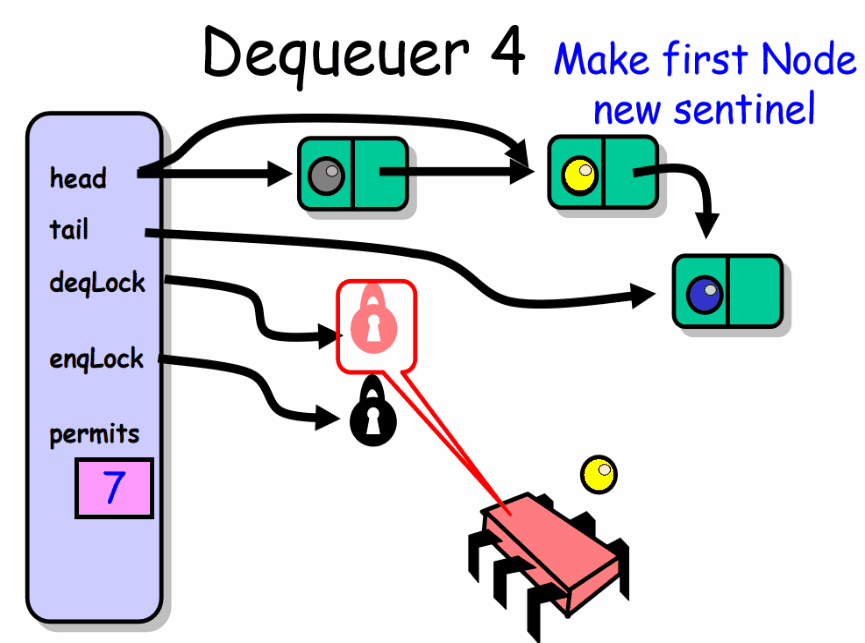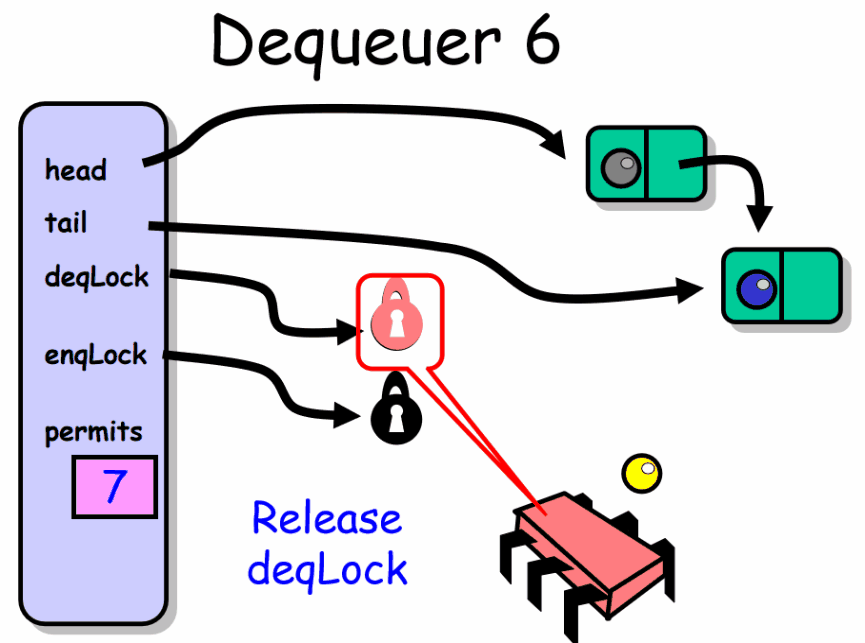
deq() 出队者正常推进的前提是队列中有元素。线程先获取 deqLock 锁,然后检查 permits 域,如果该域等于队列容量,说明队列是空的。出队者此时在 notEmptyCondition 条件上等待,暂时释放了 deqLock 锁。直到有一个入队者向队列中放入一个元素。每当出队者被唤醒,它就会再次检查队列是否为空。然后出队者会根据队列中是否还有空的槽位这一条件来决定是否唤醒入队者。
![]()
抽象队列的头元素和尾元素并不总是与 head 和 tail 所指向的元素相同,理解这一点是非常重要的。一旦最后一个节点的next域指向了新的节点,一个元素就已经被插入到队列中了,即使入队者还没有更新 tail 域的值。例如,一个线程可以持有 enqLock 的同时插入新节点。假设还没有更新 tail 域。一个并发的出队者线程可以持有 deqLock 这时候就可以获取到新节点,并且可以重设 head 指向新节点。而所有的这些操作都可以在入队者重设 tail 域指向新插入节点之前完成。简单来说就是 head ,tail 域的值并不是绝对准确的。
这种有界队列实现的一个缺点是并发的 enq() , deq() 之间互相干扰,但不是通过锁的方式。所有的函数对 permits 域调用 getAndIncrement() 和 getAndDecrement() ,这些函数比通常的读写开销更大,且能引起顺序瓶颈。
减少这种干扰的一种方法是将这个域分成两个计数器:一个由 deq() 加1的整型域 enqSidePermits 和一个由 enq() 减1的 deqSidePermits 。调用 enq() 的线程检查 enqSidePermits 只要它大于0就继续执行。当该域等于0时,说明队列满了,线程锁住 deqLock ,并将 deqSidePermits 加到 enqSidePermits 中。当入队者的大小估值变得非常大时,这种技术能够分散的同步,而不是对每个方法调用进行同步。
public class BoundedQueue<T> { ReentrantLock enqLock; ReentrantLock deqLock; Condition notEmptyCondition; Condition notFullCondition; AtomicInteger permits; Node head; Node tail; int capacity; public BoundedQueue(int capacity) { this.capacity = capacity; this.head = new Node(null); this.tail = head; this.permits = new AtomicInteger(capacity); this.enqLock = new ReentrantLock(); this.notFullCondition = enqLock.newCondition(); this.deqLock = new ReentrantLock(); this.notEmptyCondition = deqLock.newCondition(); } public T deq() { T result; boolean mustWakeEnqueuers = true; deqLock.lock(); try { while (permits.get() == capacity) { try { notEmptyCondition.await(); } catch (InterruptedException ex) {} } result = head.next.value; head = head.next; if (permits.getAndIncrement() > 0) { mustWakeEnqueuers = true; } } finally { deqLock.unlock(); } if (mustWakeEnqueuers) { enqLock.lock(); try { notFullCondition.signalAll(); } finally { enqLock.unlock(); } } return result; } public void enq(T x) { if (x == null) throw new NullPointerException(); boolean mustWakeDequeuers = false; enqLock.lock(); try { while (permits.get() == 0) { try { notFullCondition.await(); } catch (InterruptedException e) {} } Node node = new Node(x); tail.next = node; tail = node; if (permits.getAndDecrement() > 0) { mustWakeDequeuers = true; } } finally { enqLock.unlock(); } if (mustWakeDequeuers) { deqLock.lock(); try { notEmptyCondition.signalAll(); } finally { deqLock.unlock(); } } } protected class Node{ public T value; public Node next; public Node(T x) { value = x; next = null; } }}
完全无界队列
无界队列可以存放任意数量的元素。这种无界队列的算法要比有界队列简单,无界队列不可能发生死锁,因为每个函数中只获得一个锁,或者是 enqLock 或者 deqLock 。队列中唯一的哨兵节点永远不会被删除。
public class UnboundedQueue<T> { ReentrantLock enqLock, deqLock; Node head; Node tail; public UnboundedQueue() { head = new Node(null); tail = head; enqLock = new ReentrantLock(); deqLock = new ReentrantLock(); } public T deq() throws EmptyException { T result; deqLock.lock(); try { if (head.next == null) { throw new EmptyException(); } result = head.next.value; head = head.next; } finally { deqLock.unlock(); } return result; } public void enq(T x) { if (x == null) throw new NullPointerException(); enqLock.lock(); try { Node e = new Node(x); tail.next = e; tail = e; } finally { enqLock.unlock(); } }
protected class Node { public T value; public Node next; public Node(T x) { value = x; next = null; } }}
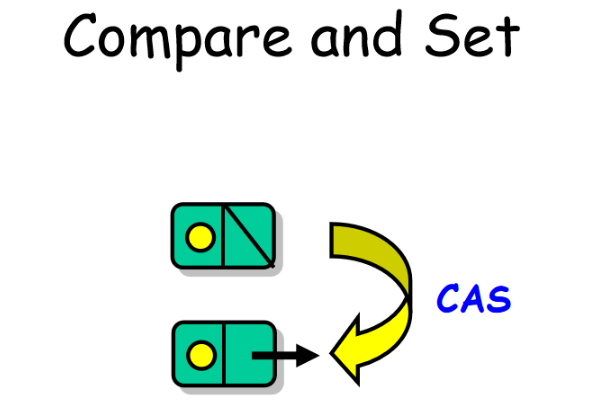
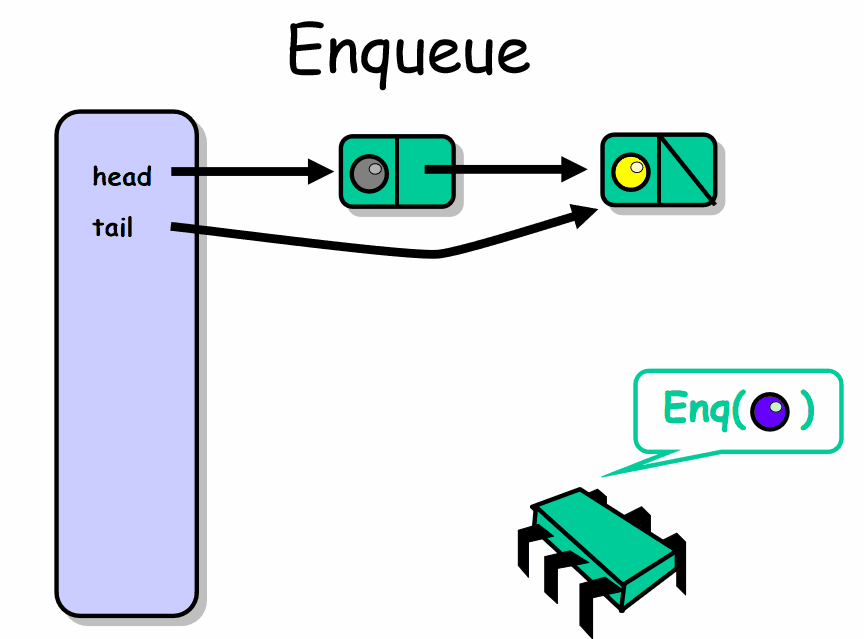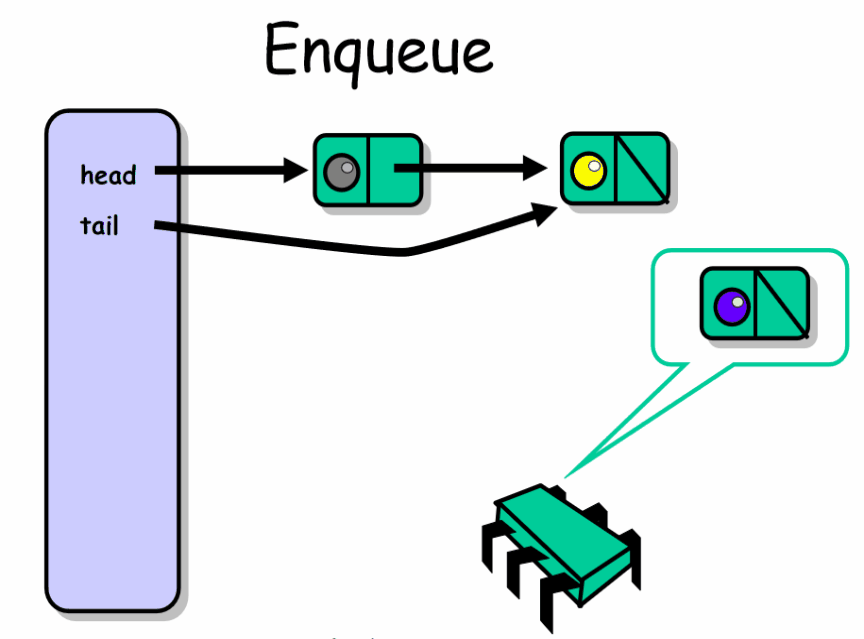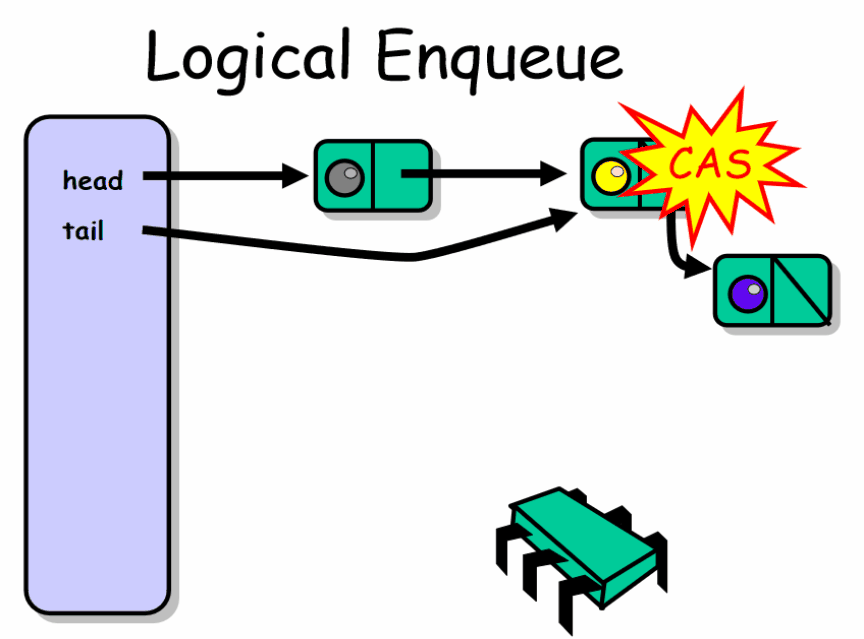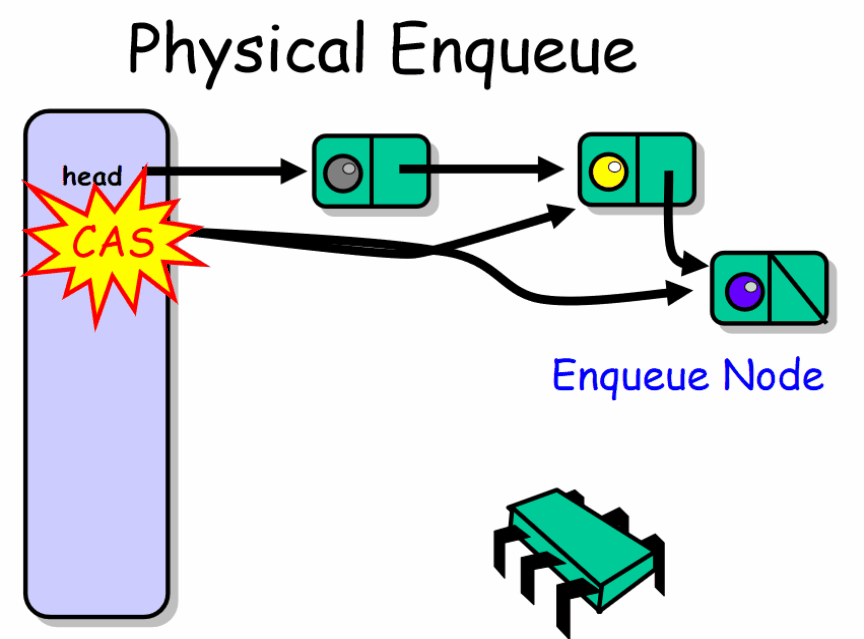
无锁无界队列
无锁无界队列依靠CAS操作来实现无锁化
![]()
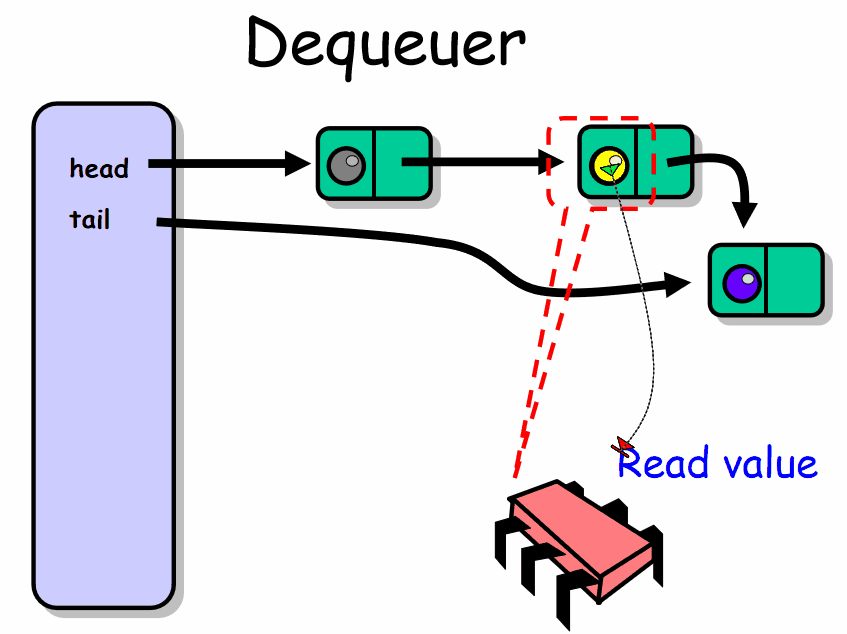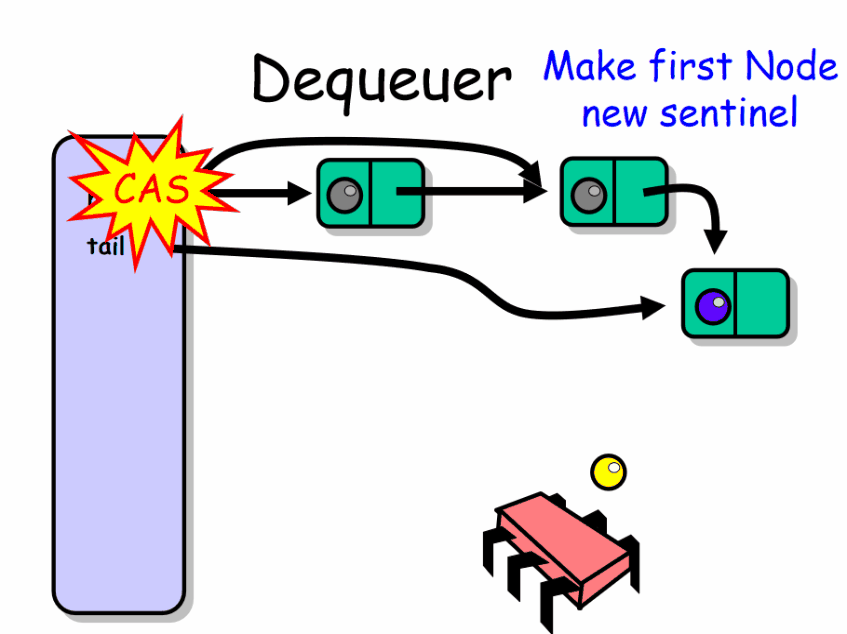
public class LockFreeQueue<T> { private AtomicReference<Node> head; private AtomicReference<Node> tail; public LockFreeQueue() { Node sentinel = new Node(null); this.head = new AtomicReference<Node>(sentinel); this.tail = new AtomicReference<Node>(sentinel); } public void enq(T item) { if (item == null) throw new NullPointerException(); Node node = new Node(item); // allocate & initialize new node while (true) { // keep trying Node last = tail.get(); // read tail Node next = last.next.get(); // read next if (last == tail.get()) { // are they consistent? if (next == null) { if (last.next.compareAndSet(next , node)) { tail.compareAndSet(last , node); return; } } else { tail.compareAndSet(last , next); } } } } public T deq() throws EmptyException { while (true) { Node first = head.get(); Node last = tail.get(); Node next = first.next.get(); if (first == head.get()) {// are they consistent? if (first == last) { // is queue empty or tail falling behind? if (next == null) { // is queue empty? throw new EmptyException(); } // tail is behind, try to advance tail.compareAndSet(last, next); } else { T value = next.value; // read value before dequeuing if (head.compareAndSet(first, next)) return value; } } } } public class Node { public T value; public AtomicReference<Node> next; public Node(T value) { this.value = value; this.next = new AtomicReference<Node>(null); } }}
入队者如何工作:
![]()
出队者如何工作:
![]()
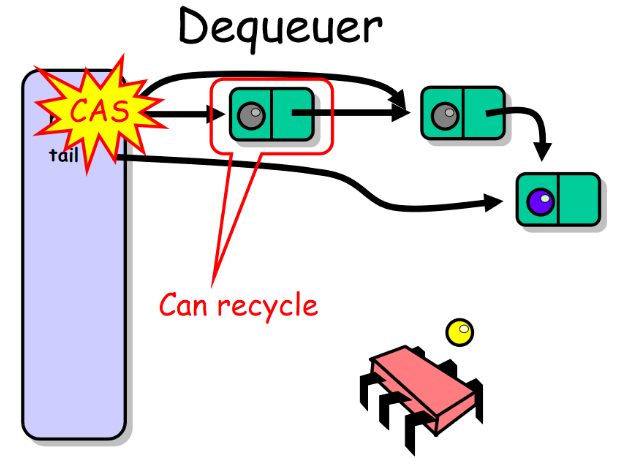
在无锁情况下存在一个很微妙的问题,在向前移动head之前,必须确认tail没有指向将要被删除的哨兵节点。为了避免这个问题我们加入了一个测试,如果head等于tail并且它们所指向节点的next域非null,则认为tail比实际值滞后了。与enq()函数一样,deq()通过调整tail指向哨兵节点的后继来尝试帮助tail使其一致,只有在这时才能更新head以删除哨兵节点。
很容易说明队列是无锁的,每个函数调用首先找出一个未完成的 enq() 调用,然后尝试完成它。最坏情形下,所有线程都试图移动队列的 tail 域,且其中之一必须成功。仅当另一个线程的函数调用在改变引用中获得成功时,一个线程才可能在入队或出队一个节点时失败。因此,总会有某个函数调用成功。这种无锁实现从本质上改变了队列性能,无锁算法的性能比最有效的阻塞算法要高。
内存回收与ABA问题
首先考虑一下内存回收的问题,到目前为止所有队列实现都依赖Java的垃圾回收器来重复利用哪些已经出队节点的内存空间。如果我们选择采用自己的内存管理,会出现什么样的情形呢?之所以这样做有以下几个原因:
1. C和C++这些语言并不支持垃圾回收。
2. 即使可以使用垃圾回收器,由类本身来提供自己的内存管理也往往具有更高的效率,特别是在创建和释放许多小对象时。
3. 若垃圾回收进程不是无锁的,则显然希望能提供自己的无锁内存回收。
![]()
以无锁方式循环节点的一种很自然的办法就是让每个线程维护它自己的由未使用队列项所组成的私有空闲链表。
ThreadLocal<Node> freeList = new ThreadLocal<Node>() { protected Node initiaValue() { return null; }}
当一个入队线程需要一个新节点时,它尝试从线程本地空闲链表中删除一个节点。如果空闲链表为空, 就new一个新节点。当一个出队线程准备释放一个节点时,它将该节点放入线程本地空闲链表。因为链表是线程本地的,因此不需要很大的同步开销。只要每个线程入队和出队次数大致相同,这种设计的效果就非常好。如果两种操作次数不平衡,则需要更加复杂的技术。
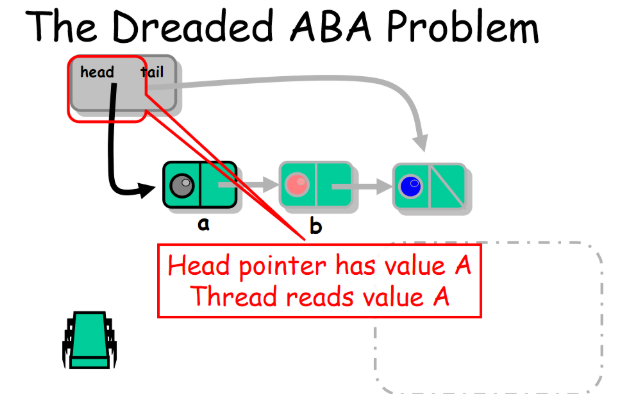
那么好如果我们使用上面说到的内存回收方案就会发生ABA问题。简单的介绍ABA问题:一个值原来是A,被别的线程修改成了B,又被别的线程修改成了A。最初看到这个值是A的线程被唤醒后发现值依然还是A就继续执行,不知道其实这个值已经被修改过很多次了。
其实生活中我们把钱存到银行里也是一个ABA问题(这里我们忽略掉那低的可怜的利率),你将一定数目的钱存到银行,银行用这笔钱去做了什么你并不知道,当你去银行取钱的时候还是你当时存进去的那个数额。
假设下面的场景:
1. 线程A要将a节点出队,将b节点设置为head, head.compareAndSet(a , b)。
![]()
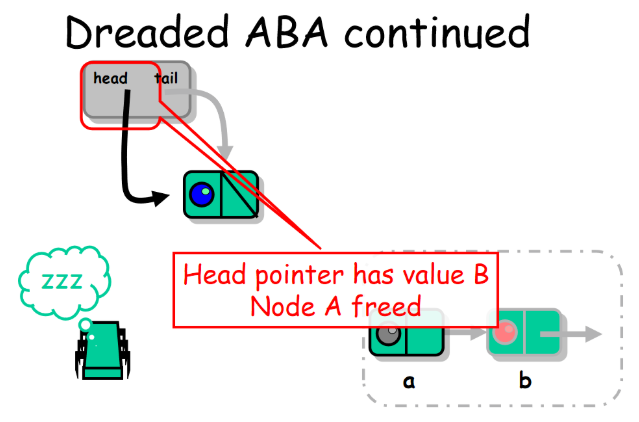
2. 线程B并发的将 a , b 节点出队并放入了空闲池当中。
![]()
3. 线程C重用了a节点并使得它再次成了head。
![]()
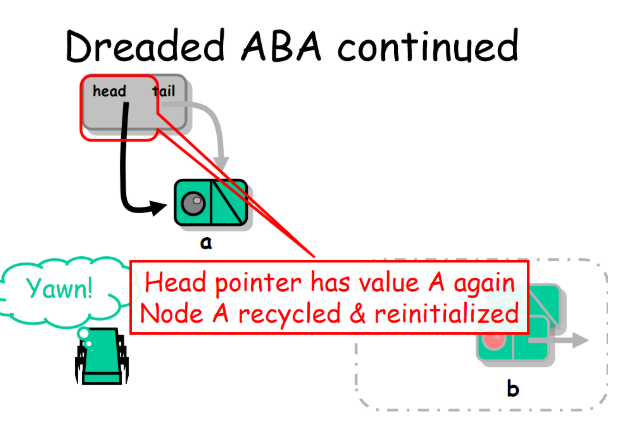
4. 线程A继续开始执行 head.compareAndSet(a , b) ,发现了此时head等于a,于是成功将head指向了b。但是b此时已经是一个出队了的节点。
![]()
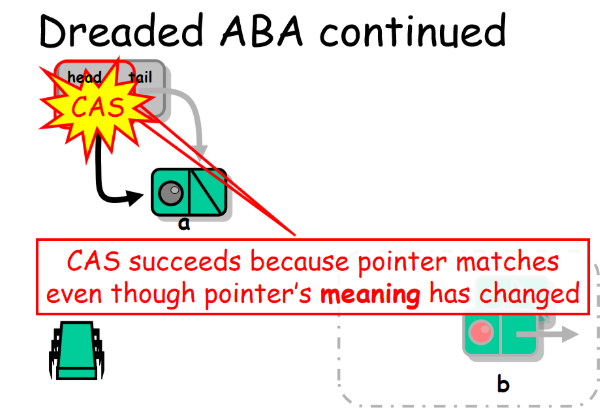
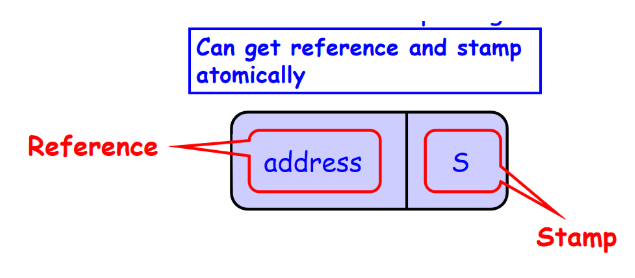
ABA现象经常出现,特别是在使用类似 test-and-set 这种条件同步操作的动态内存算法中。典型的情形就是,一个将要被 compareAndSet() 从 a 变为 b ,又从 b 变为 a。这样一来,即使对数据结构的影响已经产生了,compareAndSet() 调用也将成功返回,但结果已经不是我们期望的了。解决ABA问题的一种直接办法就是对每个原子引用附上一个唯一的标识。
![]()
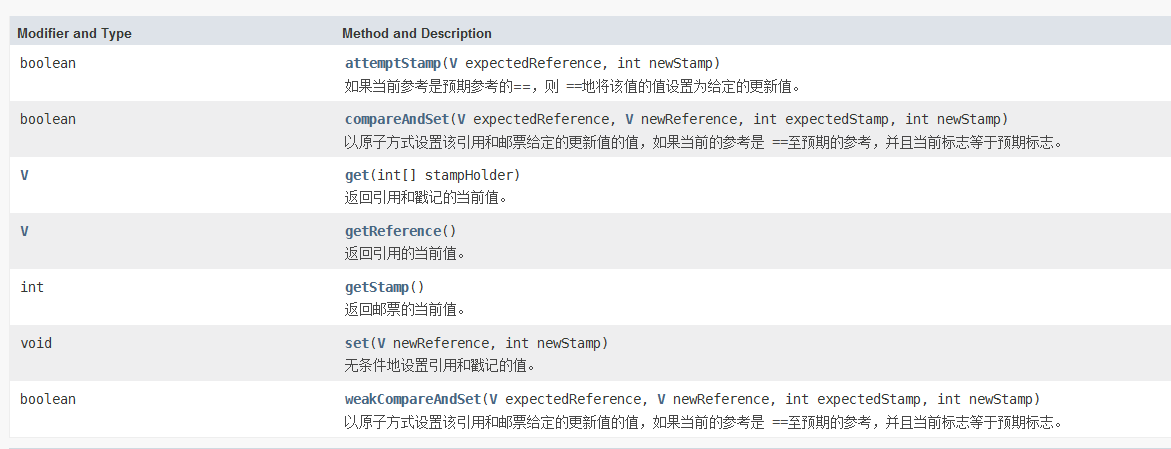
在Java语言中提供了这个类:java.util.concurrent.atomic.AtomicStampedReference<V>
![]()
![]()
public class LockFreeQueueRecycle<T> { private AtomicStampedReference<Node> head; private AtomicStampedReference<Node> tail; ThreadLocal<Node> freeList = new ThreadLocal<Node>() { protected Node initialValue() { return null; }; }; public LockFreeQueueRecycle() { Node sentinel = new Node(); head = new AtomicStampedReference<Node>(sentinel, 0); tail = new AtomicStampedReference<Node>(sentinel, 0); } private Node allocate(T value) { int[] stamp = new int[1]; Node node = freeList.get(); if (node == null) { // nothing to recycle node = new Node(); } else { // recycle existing node freeList.set(node.next.get(stamp)); } // initialize node.value = value; return node; } private void free(Node node) { Node free = freeList.get(); node.next = new AtomicStampedReference<Node>(free, 0); freeList.set(node); } public void enq(T value) { // try to allocate new node from local pool Node node = allocate(value); int[] lastStamp = new int[1]; int[] nextStamp = new int[1]; int[] stamp = new int[1]; while (true) { // keep trying Node last = tail.get(lastStamp); // read tail Node next = last.next.get(nextStamp); // read next // are they consistent? if (last == tail.get(stamp) && stamp[0] == lastStamp[0]) { if (next == null) { // was tail the last node? // try to link node to end of list if (last.next.compareAndSet(next, node, nextStamp[0], nextStamp[0]+1)) { // enq done, try to advance tail tail.compareAndSet(last, node, lastStamp[0], lastStamp[0]+1); return; } } else { // tail was not the last node // try to swing tail to next node tail.compareAndSet(last, next, lastStamp[0], lastStamp[0]+1); } } } } public T deq() throws EmptyException { int[] lastStamp = new int[1]; int[] firstStamp = new int[1]; int[] nextStamp = new int[1]; int[] stamp = new int[1]; while (true) { Node first = head.get(firstStamp); Node last = tail.get(lastStamp); Node next = first.next.get(nextStamp); // are they consistent? if (first == head.get(stamp) && stamp[0] == firstStamp[0]) { if (first == last) { // is queue empty or tail falling behind? if (next == null) { // is queue empty? throw new EmptyException(); } // tail is behind, try to advance tail.compareAndSet(last, next, lastStamp[0], lastStamp[0]+1); } else { T value = next.value; // read value before dequeuing if (head.compareAndSet(first, next, firstStamp[0], firstStamp[0]+1)) { free(first); return value; } } } } } public class Node { public T value; public AtomicStampedReference<Node> next; public Node() { this.next = new AtomicStampedReference<Node>(null, 0); } }}
基本同步队列
一种紧密相关的同步方式,生产者和消费者之间必须相互会合:向队列中放入一个元素的生产者应该阻塞直到该元素被另一个消费者取出,反之亦然。
SynchronousQueue 中 item 是第一个等待出队的元素, enqueuing 是入队者用来在它们之间同步的布尔值,lock是用来互斥的锁,condition 用于阻塞部分函数。如果 enq() 发现 enqueuing 为 true ,则表示另一个入队者已经提供了一个元素并正等待与一个出队者会合,所以该入队者将会重复执行释放锁,等待,检查 enqueuing 的操作。当条件满足,入队者将 enqueuing 设置为 true ,这将阻塞其他入队者直到与出队者的会合完成,并设置 item 指向新元素。然后通知所有等待线程,并等待直到 item 变为 null。当等待结束时,会合已经发生,入队者设置 enqueuing 为 false,通知所有等待线程并返回。
deq() 函数简单的等待 item 不为空,记录该数据元素,将 item 设为 null,然后在返回该元素之前通知所有等待线程。
由于这个队列设计的非常简单,所以它的同步代价也很高。在每个线程可能唤醒另一个线程的时间点,无论是入队者还是出队者都会唤醒所有线程,从而唤醒的次数是等待次数的平方。尽管可以使用条件对象来减少唤醒次数,但由于仍然需要阻塞每次调用,所以开销很大。
public class SynchronousQueue<T> { T item = null; boolean enqueuing; Lock lock; Condition condition; public SynchronousQueue() { enqueuing = false; lock = new ReentrantLock(); condition = lock.newCondition(); } public T deq() throws InterruptedException { lock.lock(); try { while (item == null) { condition.await(); } T t = item; item = null; condition.signalAll(); return t; } finally { lock.unlock(); } } public void enq(T value) throws InterruptedException { if (value == null) throw new NullPointerException(); try { while (enqueuing) { // another enqueuer's turn condition.await(); } enqueuing = true; // my turn starts item = value; condition.signalAll(); while (item != null) { condition.await(); } enqueuing = false; // my turn ends condition.signalAll(); } finally { lock.unlock(); } }}
双重数据结构同步队列
为了减少同步队列的同步开销,考虑另外一种同步队列实现,它将 enq() 和 deq() 函数分为两步来完成。下面是出队者移除一个元素的过程。第一步,它将一个保留对象放入队列,表示该出队者正在等待一个准备与之会合的入队者。然后出队者线程在这个保留对象的flag上自旋。第二步,当一个入队者发现该保留时,它通过存放一个元素并设置保留对象的flag来通知出队者完成这个保留。同样,入队者能够创建自己的保留对象,并在保留对象的flag上自旋。在任意时刻,队列本身包含enq()的保留或deq()的保留,或者为空。
这种结构称为双重数据结构,原因在于函数是通过两个步骤来生效的:保留和完成。该结构具有许多很好的性质。首先,正在等待的线程可以在一个本地缓存标志上自旋,而这是可扩展性的基础。其次,它保证了公平性。保留按照它们到达的次序来排队,从而保证请求也按照同样的顺序完成。这种数据结构是可线性化的,因为每个部分的函数调用在它完成时是可排序的。
public class SynchronousDualQueue<T> { AtomicReference<Node> head; AtomicReference<Node> tail; public SynchronousDualQueue() { Node sentinel = new Node(null, NodeType.ITEM); head = new AtomicReference<Node>(sentinel); tail = new AtomicReference<Node>(sentinel); } public void enq(T e) { Node offer = new Node(e, NodeType.ITEM); while (true) { Node t = tail.get(); Node h = head.get(); if (h == t || t.type == NodeType.ITEM) { Node n = t.next.get(); if (t == tail.get()) { if (n != null) { tail.compareAndSet(t, n); } else if (t.next.compareAndSet(n, offer)) { tail.compareAndSet(t, offer ); while (offer.item.get() == e); // spin h = head.get(); if (offer == h.next.get()) { head.compareAndSet(h, offer); } return; } } } else { Node n = h.next.get(); if (t != tail.get() || h != head.get() || n == null) { continue; // inconsistent snapshot } boolean success = n.item.compareAndSet(null, e); head.compareAndSet(h, n); if (success) { return; } } } } public T deq() { Node offer = new Node(null, NodeType.RESERVATION); while (true) { Node t = tail.get(); Node h = head.get(); if (h == t || t.type == NodeType.RESERVATION) { Node n = t.next.get(); if (t == tail.get()) { if (n != null) { tail.compareAndSet(t, n); } else if (t.next.compareAndSet(n, offer)) { tail.compareAndSet(t, offer); while (offer.item.get() == null); // spin h = head.get(); if (offer == h.next.get()) { head.compareAndSet(h, offer); } return offer.item.get(); } } } else { Node n = h.next.get(); if (t != tail.get() || h != head.get() || n == null) { continue; // inconsistent snapshot } T item = n.item.get(); boolean success = n.item.compareAndSet(item, null); head.compareAndSet(h, n); if (success) { return item; } } } } private enum NodeType {ITEM, RESERVATION}; private class Node { volatile NodeType type; volatile AtomicReference<T> item; volatile AtomicReference<Node> next; Node(T item, NodeType type) { this.item = new AtomicReference<T>(item); this.next = new AtomicReference<Node>(null); this.type = type; } }}
enq() 函数首先检查队列是否为空或者是否包含等待出队的已入队元素。如果条件满足,则像无锁队列一样,读队列的 tail 域,并确认读的值是一致的。如果 tail 域没有指向队列的最后一个节点,则推进 tail 域并重新开始。否则,enq() 函数尝试通过重设尾节点的 next 域指向新节点,把新节点添加到对尾。如果成功,就尝试推进 tail 指向新增加的节点,然后自旋,等待一个出队者通过设置该节点的 item 域为 null 来通知该元素已经出队。一旦元素出队,该函数就尝试将它的节点设为哨兵节点来进行清理。最后一步用来提高性能,因为不管是否推进了head域,该实现总是正确的。
然而,如果 enq() 函数发现队列中有正在等待完成的出队者保留,那么它就找出一个保留并完成。由于队列的 head 节点是一个其值无任何意义的哨兵节点,所以 enq() 读 head 后继节点,确认读到的值是一致的,并尝试将节点 item 域从 null 改为要入队的元素。不管这一步是否成功,该函数都试着推进 head。如果 compareAndSet() 调用成功,则该函数返回,否则重试。
往期精彩回顾
并发编程的艺术01-面试中被问到并发知识答不上来?
并发编程的艺术02-过滤锁算法
并发编程的艺术03-Bakery互斥算法
并发编程的艺术04-TAS自旋锁
并发编程的艺术05-队列自旋锁
并发编程的艺术06-复合&层次自旋锁
并发编程的艺术07-非阻塞同步演进
关注微信公众号「黑帽子技术」
第一时间浏览技术干货文章
![]()