![]()
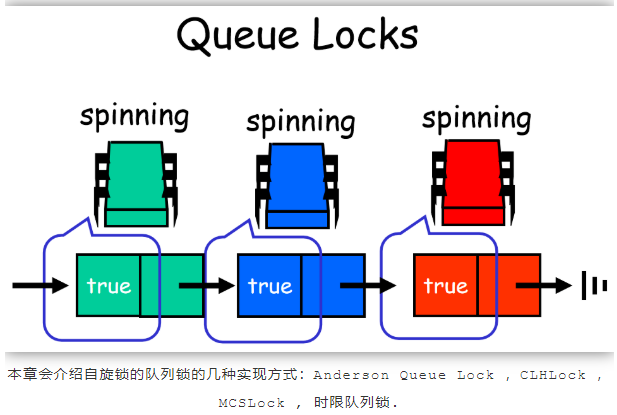
Queue Spin-Lock
队列锁是一种可扩展自旋锁的方法,这种实现比BackoffLock稍微复杂一些,但是却有更好的移植性。在BackoffLock算法中有两个问题:
1. cache一致性流量:所有线程都在一个共享的存储单元上自旋,每一次成功的锁访问都会产生cache一致性流量。(尽管比 TASLock要低)。
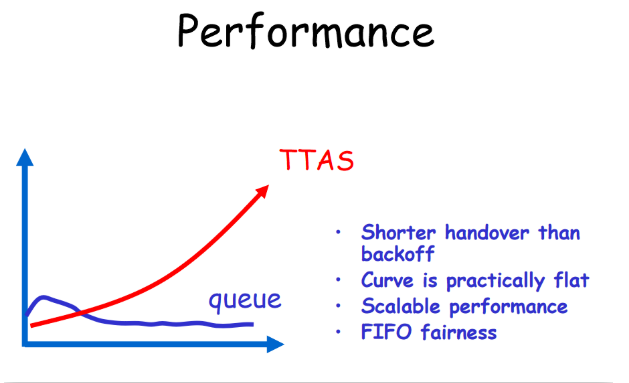
2. 临界区的利用率低:线程延迟时间长,导致临界区利用率低下。在队列中,每个线程检测其前驱线程是否已完成来判断是否轮到了自己。让每个线程在不同的存储单元上自旋,从而降低cache一致性流量。队列还提高了临界区的利用率,因为没有比要去判断何时要访问它:每个线程直接由队列中的前驱线程来通知。队列还提供了先来先服务的公平性。
![]()
Anderson Queue Lock
public class ALock implements Lock {
ThreadLocal<Integer> mySlotIndex = new ThreadLocal() {
protected Integer initiaValue() {
return 0;
}
};
AtomicInteger tail;
boolean[] flag;
int size;
public ALock(int capacity) {
size = capacity;
tail = new AtomicInteger(0);
flag = new boolean[capacity];
flag[0] = true;
}
public void lock() {
int slot = tail.getAndIncrement() % size;
mySlotIndex.set(slot);
while (! flag[slot]) {
}
// Prepare slot for re-use
flag[slot] = false;
}
public void unlock() {
Integer slot = mySlotIndex.get();
flag[(slot + 1) % size] = true;
}
}
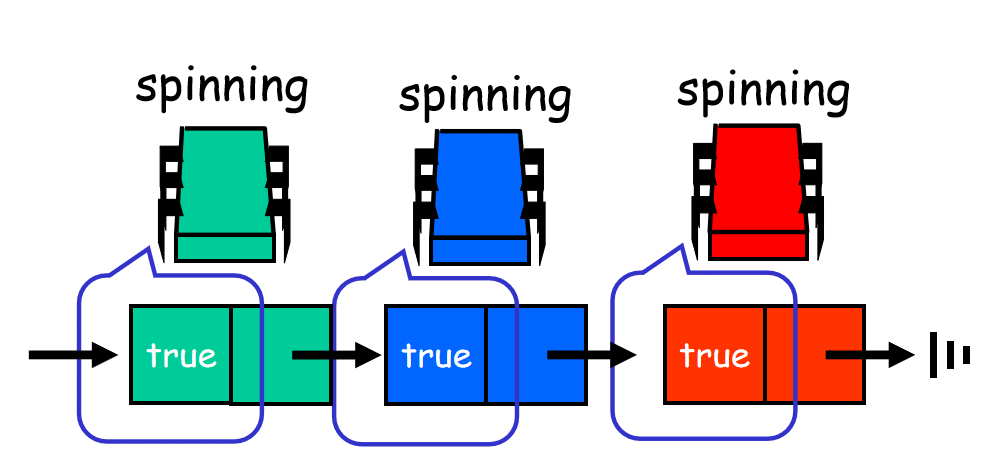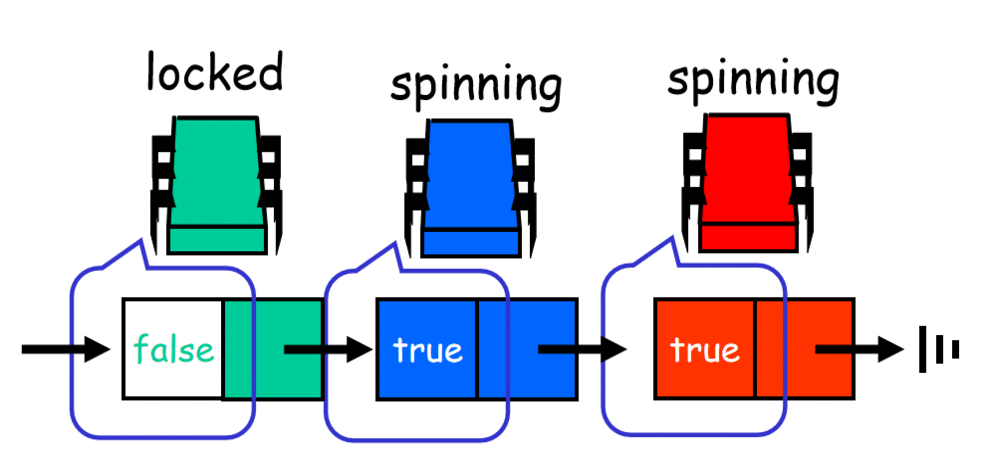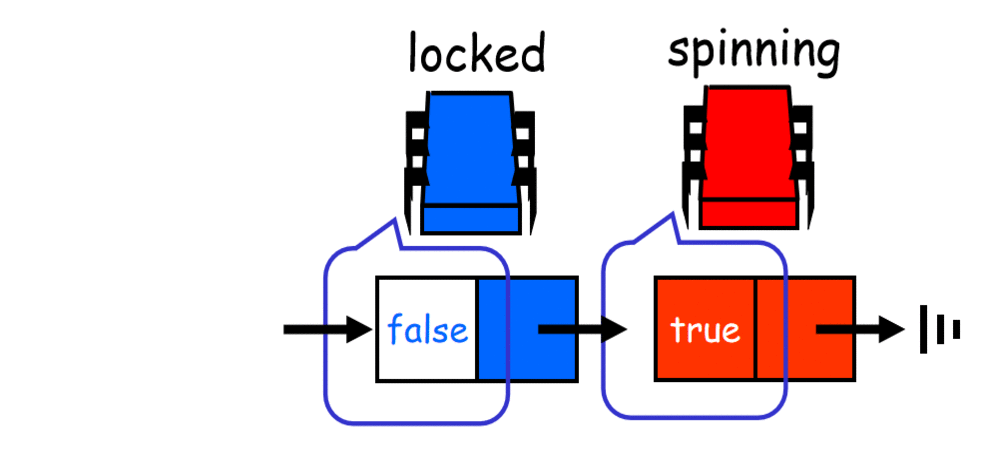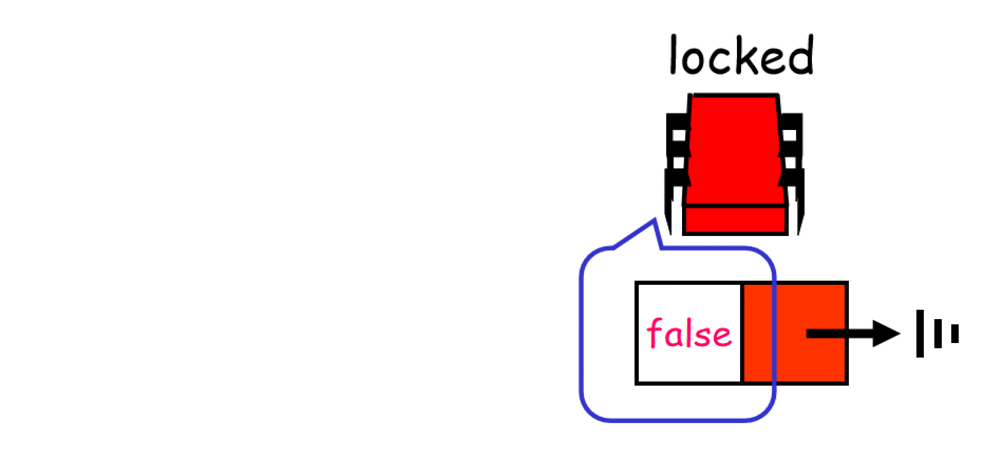
数组flag[]是被多个线程共享的。但在任意给定时间,由于每个线程都是在一个数组存储单元的本地缓存中副本上自旋,大大降低了无效流量,从而使得对数组存储单元的争用达到最小。但是争用任然可能发生,原因在于存在一种假共享的现象,当相邻数据项(比如数组元素)在同一个cache line 中就会发生这种现象。对一个数据项的写会使得该cache line无效,但是对于哪些在同一个cache line中未发生改变的数据项来说,这种写将会引起在这些未改变数据项上进行自旋的处理器的无效流量。要解决这个问题就需要在数据项之间进行填充,确保每一个数据项处在一个单独的cache line中。ALock 是对BackoffLock的改进,它将无效性降低到最低并把一个线程释放锁和另一个线程获取该锁之间的时间间隔最小化。与 TASLock 和 BackoffLock 不同,该算法能够确保无饥饿性。同时也保证了先来先服务(First-Come-First-Served)的公平性。ALock 并不是空间有效的。它要求并发线程的最大个数为一个已知的界限 n ,同时为每个锁分配一个与该界限大小相同的数组。因此即使一个线程每次只能访问一个锁,同步L个不同对象也需要O(Ln)大小的空间。
![]()
CLH LOCK
class QNode {
public locked = false;
}
public class CLHLock implements Lock {
AtomicReference<QNode> tail = new AtomicReference<QNode>(new QNode());
ThreadLocal<QNode> myNode, myPred;
public CLHLock() {
myNode = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return new QNode();
}
};
myPred = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return null;
}
};
}
public void lock() {
QNode qnode = myNode.get();
qnode.locked = true;
QNode pred = tail.getAndSet(qnode);
myPred.set(pred);
// Spin until predecessor releases lock
while (pred.locked) {
}
}
public void unlock() {
QNode qnode = myNode.get();
qnode.locked = false;
myNode.set(myPred.get());
}
}
QNode 对象的 locked 域中记录了每个线程的状态。如果为 true 则相应的线程要么已经获得了锁,要么正在等待锁。如果为 false 则相应的线程已经释放了锁。锁本身被表示为 QNode 对象的虚拟链表,之所以说是虚拟是因为链表是隐式的:每个线程通过一个局部变量 pred 指向其前驱。公共的 tail 域对于最近加入到队列中的节点来说是一个 AtomicReference<QNode> 。
若要获得锁,线程讲其QNode的locked域设置为 true ,表示该线程不准备释放锁。随后线程对 tail 调用 getAndSet() ,使得当前线程自己成为新的tail节点,同时获取到前驱线程的 QNode 引用。然后线程在前驱 QNode的locked域上自旋等待,直到前驱线程释放了锁。释放锁的时候线程将其QNode的locked域设置为false 。然后复用了前驱节点的QNode作为自己线程的QNode , 因为前驱线程目前已经处于释放锁的状态不再去使用这个 QNode, 这个QNode的locked域已经是false,而当前线程也释放了锁,所以可以重用这个QNode作为当前释放了锁状态下的QNode 。
与 ALock 一样该算法让每个线程在不同的存储单元上自旋,当一个线程释放掉锁时,只会使得它后面节点的线程cache失效。该算法比ALock所需的存储空间少,而且不需要知道可能使用锁的线程数量。该算法也提供了先到先服务(First-Come-First-Served)公平性。
MCS Lock
MCSLock 的锁链表是显示的而不是虚拟的,通过 QNode 对象中的 next 域所体现。
class QNode {
public locked = false;
public QNode next;
}
public class MCSLock implements Lock {
AtomicReference<QNode> tail = new AtomicReference<QNode>(null);
ThreadLocal<QNode> myNode;
public MCSLock () {
myNode = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return new QNode();
}
};
}
public void lock() {
QNode qnode = myNode.get();
QNode pred = tail.getAndSet(qnode);
if (pred != null) {
qnode.locked = true;
pred.next = qnode;
while (qnode.locked) {
}
}
}
public void unlock() {
QNode qnode = myNode.get();
if (qnode.next == null) {
if (tail.compareAndSet(qnode , null))) {
return;
}
while (qnode.next == null) {
}
}
qnode.next.locked = false;
qnode.next = null;
}
}
MCSLock , 若要获得锁,线程把自己的 QNode 添加到链表的尾部。如果队列不为空则将前一个节点的 QNode 的 next 域指向当前线程的 QNode。然后线程在自己的 QNode 对象 locked 域上自旋等待。直到前一个节点的线程将自己 QNode 的 next 域 QNode 的 locked 域设置为 false 。
释放锁时,先要检查节点的 next 域是不是空的。如果是,则要么不存在其他线程正在争用这个锁,要么是存在争用锁的线程但是执行的较慢。为了区分这两种情况,对 tail 域调用 compareAndSet(qnode , null) 。如果返回true 说明没有其他线程正在试图获取锁,将 tail 域设置为 null 并返回。否则说明有另一个线程正在试图获取锁,于是该函数自旋等待正在获取锁的线程设置 next 域。然后将 next 节点的 locked 域设置为 false ,表示锁是空闲的,结束 next 节点线程的自旋等待。
时限队列锁
Java 的 Lock 接口包含一个 tryLock() 函数,该函数允许调用者指定一个时限:调用者为了获得锁而准备等待的最大时间。如果在调用者获得锁之前超时,调用者放弃获得锁的尝试。由于线程能非常简单的从 tryLock() 返回,所以放弃一个 BackoffLock 请求是很容易的。超时无需等待,只要求固定的操作步骤。于此相反,若对任意队列锁算法都进行超时控制就不是一件容易的事:如果一个线程简单的返回,那么排在它后面的线程将会饿死。
class QNode {
public QNode pred;
}
public class TOLock implements Lock {
static QNode AVAILABLE = new QNode();
AtomicReference<QNode> tail = new AtomicReference<QNode>(null);
ThreadLocal<QNode> myNode;
public TOLock() {
myNode = new ThreadLocal<QNode>() {
protected QNode initialValue() {
return new QNode();
}
};
}
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
long startTime = System.nanoTime();
long patience = TimeUnit.NANOSECONDS.convert(time, unit);
QNode qnode = new QNode();
myNode.set(qnode); // remember for unlock
qnode.pred = null;
QNode pred = tail.getAndSet(qnode);
if (pred == null || pred.pred == AVAILABLE) {
return true; // lock was free; just return
}
while (System.nanoTime() - startTime < patience) {
QNode predPred = pred.pred;
if (predPred == AVAILABLE) {
return true;
} else if (predPred != null) { // skip predecessors
pred = predPred;
}
}
// timed out; reclaim or abandon own node
if (!tail.compareAndSet(qnode, pred))
qnode.pred = pred;
return false;
}
public void unlock() {
QNode qnode = myNode.get();
if (! tail.compareAndSet(qnode, null))
qnode.pred = AVAILABLE;
}
public void lock() {
try {
tryLock(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
}
时限队列锁是一个虚拟的队列,每个线程在它的前驱节点上自旋,等待锁被释放。若一个线程超时,则该线程不能简单的抛弃它的队列节点,因为当锁被释放时,该线程的后继节点无法注意到这种情形。另一方面,让一个队列节点从链表中删除而不扰乱并发锁的释放似乎是相当困难的。因此,可以使用惰性方法:如果一个线程超时,则该线程将它的节点标记为已放弃。这样该线程在队列中的后继将会注意到它正在一个已经放弃了的节点上自旋,于是转而在被放弃的节点的前驱节点上自旋。这种方法有一个额外的好处是:后继线程可以重用被放弃的节点。
当一个QNode的pred域为null时,该节点所对应的线程或者还未获得锁或者已经释放了锁。当一个QNode的pred域指向了一个可判别的静态QNode(AVAILABLE)时,其相应的线程已经释放了锁。如果pred域指向了某个QNode,那么相应的线程已经放弃了请求锁,这样后继节点的线程应该在被放弃节点的前驱上自旋。
tryLock() 函数创建了一个pred域为null的新的QNode,它像CLHLock一样把该节点加入到链表尾部。如果这个锁是空闲的,则线程进入临界区。否则,线程自旋等待其前驱节点的pred域被改变。如果前驱线程超时未获得锁,则设置pred域指向其前驱,并在新的前驱上自旋。最后如果线程自己超时,那么它就在tail域上调用compareAndSet()来尝试从链表中移除它的QNode。如果移除失败了说明这个线程还有后继线程,线程则设置它的QNode的pred域指向其前驱的QNode,表明他已经从队列中放弃获得锁。
unlock() 函数中,线程通过compareAndSet()来检查是否存在后继线程。如果有,则设置它得QNode的pred域为AVAILABLE。要注意这个时刻重新使用线程的老节点是很危险的,因为该节点有可能被它的直接后继所引用,或被一个由这种引用所组成的链所引用。一旦线程跳过超时节点并进入临界区,那么这个链中的节点就可以被回收。
TOLock具有CLHLock的大多数优点:在缓存的存储单元上进行本地自旋以及对锁空闲的快速检测。它也具有BackoffLock的无等待超时特性。然而,该锁也存在缺点,包括每次锁访问都需要分配一个新的节点以及在锁上自旋的线程在访问临界区之前有可能不得不回溯一个超时节点链条。
往期精彩回顾 :
并发编程的艺术01-面试中被问到并发基础知识打不上来?
并发编程的艺术02-过滤锁算法
并发编程的艺术03-Bakery互斥锁算法
并发编程的艺术04-TAS自旋锁算法
带你了解缓存一致性协议MESI
内存屏障究竟是个什么鬼?
关注微信公众号「黑帽子技术」
第一时间浏览技术干活文章
![]()