DLedger 基于 raft 协议,故天然支持主从切换,即主节点(Leader)发生故障,会重新触发选主,在集群内再选举出新的主节点。
RocketMQ 中主从同步,从节点不仅会从主节点同步数据,也会同步元数据,包含 topic 路由信息、消费进度、延迟队列处理队列、消费组订阅配置等信息。那主从切换后元数据如何同步呢?特别是主从切换过程中,对消息消费有多大的影响,会丢失消息吗?
> 温馨提示:本文假设大家已经对 RocketMQ4.5 版本之前的主从同步实现有一定的了解,这部分内容在《RocketMQ技术内幕》一书中有详细的介绍,大家也可以参考如下两篇文章: > 1、 RocketMQ HA机制(主从同步) 。 > 2、RocketMQ 整合 DLedger(多副本)即主从切换实现平滑升级的设计技巧
1、BrokerController 中与主从相关的方法详解
本节先对 BrokerController 中与主从切换相关的方法。
1.1 startProcessorByHa
BrokerController#startProcessorByHa
private void startProcessorByHa(BrokerRole role) {
if (BrokerRole.SLAVE != role) {
if (this.transactionalMessageCheckService != null) {
this.transactionalMessageCheckService.start();
}
}
}
感觉该方法的取名较为随意,该方法的作用是开启事务状态回查处理器,即当节点为主节点时,开启对应的事务状态回查处理器,对PREPARE状态的消息发起事务状态回查请求。
1.2 shutdownProcessorByHa
BrokerController#shutdownProcessorByHa
private void shutdownProcessorByHa() {
if (this.transactionalMessageCheckService != null) {
this.transactionalMessageCheckService.shutdown(true);
}
}
关闭事务状态回查处理器,当节点从主节点变更为从节点后,该方法被调用。
1.3 handleSlaveSynchronize
BrokerController#handleSlaveSynchronize
private void handleSlaveSynchronize(BrokerRole role) {
if (role == BrokerRole.SLAVE) { // [@1](https://my.oschina.net/u/1198)
if (null != slaveSyncFuture) {
slaveSyncFuture.cancel(false);
}
this.slaveSynchronize.setMasterAddr(null); //
slaveSyncFuture = this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
[@Override](https://my.oschina.net/u/1162528)
public void run() {
try {
BrokerController.this.slaveSynchronize.syncAll();
} catch (Throwable e) {
log.error("ScheduledTask SlaveSynchronize syncAll error.", e);
}
}
}, 1000 * 3, 1000 * 10, TimeUnit.MILLISECONDS);
} else { // @2
//handle the slave synchronise
if (null != slaveSyncFuture) {
slaveSyncFuture.cancel(false);
}
this.slaveSynchronize.setMasterAddr(null);
}
}
该方法的主要作用是处理从节点的元数据同步,即从节点向主节点主动同步 topic 的路由信息、消费进度、延迟队列处理队列、消费组订阅配置等信息。
代码@1:如果当前节点的角色为从节点:
- 如果上次同步的 future 不为空,则首先先取消。
- 然后设置 slaveSynchronize 的 master 地址为空。不知大家是否与笔者一样,有一个疑问,从节点的时候,如果将 master 地址设置为空,那如何同步元数据,那这个值会在什么时候设置呢?
- 开启定时同步任务,每 10s 从主节点同步一次元数据。
代码@2:如果当前节点的角色为主节点,则取消定时同步任务并设置 master 的地址为空。
1.4 changeToSlave
BrokerController#changeToSlave
public void changeToSlave(int brokerId) {
log.info("Begin to change to slave brokerName={} brokerId={}", brokerConfig.getBrokerName(), brokerId);
//change the role
brokerConfig.setBrokerId(brokerId == 0 ? 1 : brokerId); //TO DO check // @1
messageStoreConfig.setBrokerRole(BrokerRole.SLAVE); // @2
//handle the scheduled service
try {
this.messageStore.handleScheduleMessageService(BrokerRole.SLAVE); // @3
} catch (Throwable t) {
log.error("[MONITOR] handleScheduleMessageService failed when changing to slave", t);
}
//handle the transactional service
try {
this.shutdownProcessorByHa(); // @4
} catch (Throwable t) {
log.error("[MONITOR] shutdownProcessorByHa failed when changing to slave", t);
}
//handle the slave synchronise
handleSlaveSynchronize(BrokerRole.SLAVE); // @5
try {
this.registerBrokerAll(true, true, brokerConfig.isForceRegister()); // @6
} catch (Throwable ignored) {
}
log.info("Finish to change to slave brokerName={} brokerId={}", brokerConfig.getBrokerName(), brokerId);
}
Broker 状态变更为从节点。其关键实现如下:
- 设置 brokerId,如果broker的id为0,则设置为1,这里在使用的时候,注意规划好集群内节点的 brokerId。
- 设置 broker 的状态为 BrokerRole.SLAVE。
- 如果是从节点,则关闭定时调度线程(处理 RocketMQ 延迟队列),如果是主节点,则启动该线程。
- 关闭事务状态回查处理器。
- 从节点需要启动元数据同步处理器,即启动 SlaveSynchronize 定时从主服务器同步元数据。
- 立即向集群内所有的 nameserver 告知 broker 信息状态的变更。
1.5 changeToMaster
BrokerController#changeToMaster
public void changeToMaster(BrokerRole role) {
if (role == BrokerRole.SLAVE) {
return;
}
log.info("Begin to change to master brokerName={}", brokerConfig.getBrokerName());
//handle the slave synchronise
handleSlaveSynchronize(role); // @1
//handle the scheduled service
try {
this.messageStore.handleScheduleMessageService(role); // @2
} catch (Throwable t) {
log.error("[MONITOR] handleScheduleMessageService failed when changing to master", t);
}
//handle the transactional service
try {
this.startProcessorByHa(BrokerRole.SYNC_MASTER); // @3
} catch (Throwable t) {
log.error("[MONITOR] startProcessorByHa failed when changing to master", t);
}
//if the operations above are totally successful, we change to master
brokerConfig.setBrokerId(0); //TO DO check // @4
messageStoreConfig.setBrokerRole(role);
try {
this.registerBrokerAll(true, true, brokerConfig.isForceRegister()); // @5
} catch (Throwable ignored) {
}
log.info("Finish to change to master brokerName={}", brokerConfig.getBrokerName());
}
该方法是 Broker 角色从从节点变更为主节点的处理逻辑,其实现要点如下:
- 关闭元数据同步器,因为主节点无需同步。
- 开启定时任务处理线程。
- 开启事务状态回查处理线程。
- 设置 brokerId 为 0。
- 向 nameserver 立即发送心跳包以便告知 broker 服务器当前最新的状态。
主从节点状态变更的核心方法就介绍到这里了,接下来看看如何触发主从切换。
2、如何触发主从切换
从前面的文章我们可以得知,RocketMQ DLedger 是基于 raft 协议实现的,在该协议中就实现了主节点的选举与主节点失效后集群会自动进行重新选举,经过协商投票产生新的主节点,从而实现高可用。
BrokerController#initialize
if (messageStoreConfig.isEnableDLegerCommitLog()) {
DLedgerRoleChangeHandler roleChangeHandler = new DLedgerRoleChangeHandler(this, (DefaultMessageStore) messageStore);
((DLedgerCommitLog)((DefaultMessageStore) messageStore).getCommitLog()).getdLedgerServer().getdLedgerLeaderElector().addRoleChangeHandler(roleChangeHandler);
}
上述代码片段截取自 BrokerController 的 initialize 方法,我们可以得知在 Broker 启动时,如果开启了 多副本机制,即 enableDLedgerCommitLog 参数设置为 true,会为 集群节点选主器添加 roleChangeHandler 事件处理器,即节点发送变更后的事件处理器。
接下来我们将重点探讨 DLedgerRoleChangeHandler 。
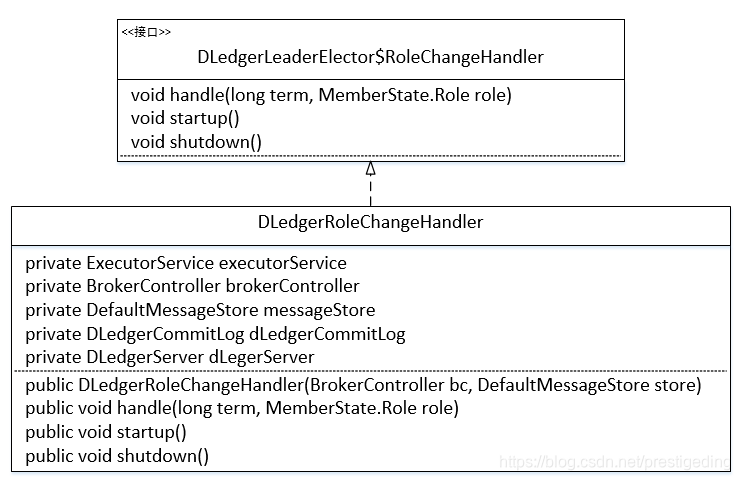
2.1 类图
![在这里插入图片描述]()
DLedgerRoleChangeHandler 继承自 RoleChangeHandler,即节点状态发生变更后的事件处理器。上述的属性都很简单,在这里就重点介绍一下 ExecutorService executorService,事件处理线程池,但只会开启一个线程,故事件将一个一个按顺序执行。
接下来我们来重点看一下 handle 方法的执行。
2.2 handle 主从状态切换处理逻辑
DLedgerRoleChangeHandler#handle
public void handle(long term, MemberState.Role role) {
Runnable runnable = new Runnable() {
public void run() {
long start = System.currentTimeMillis();
try {
boolean succ = true;
log.info("Begin handling broker role change term={} role={} currStoreRole={}", term, role, messageStore.getMessageStoreConfig().getBrokerRole());
switch (role) {
case CANDIDATE: // @1
if (messageStore.getMessageStoreConfig().getBrokerRole() != BrokerRole.SLAVE) {
brokerController.changeToSlave(dLedgerCommitLog.getId());
}
break;
case FOLLOWER: // @2
brokerController.changeToSlave(dLedgerCommitLog.getId());
break;
case LEADER: // @3
while (true) {
if (!dLegerServer.getMemberState().isLeader()) {
succ = false;
break;
}
if (dLegerServer.getdLedgerStore().getLedgerEndIndex() == -1) {
break;
}
if (dLegerServer.getdLedgerStore().getLedgerEndIndex() == dLegerServer.getdLedgerStore().getCommittedIndex()
&& messageStore.dispatchBehindBytes() == 0) {
break;
}
Thread.sleep(100);
}
if (succ) {
messageStore.recoverTopicQueueTable();
brokerController.changeToMaster(BrokerRole.SYNC_MASTER);
}
break;
default:
break;
}
log.info("Finish handling broker role change succ={} term={} role={} currStoreRole={} cost={}", succ, term, role, messageStore.getMessageStoreConfig().getBrokerRole(), DLedgerUtils.elapsed(start));
} catch (Throwable t) {
log.info("[MONITOR]Failed handling broker role change term={} role={} currStoreRole={} cost={}", term, role, messageStore.getMessageStoreConfig().getBrokerRole(), DLedgerUtils.elapsed(start), t);
}
}
};
executorService.submit(runnable);
}
代码@1:如果当前节点状态机状态为 CANDIDATE,表示正在发起 Leader 节点,如果该服务器的角色不是 SLAVE 的话,需要将状态切换为 SLAVE。
代码@2:如果当前节点状态机状态为 FOLLOWER,broker 节点将转换为 从节点。
代码@3:如果当前节点状态机状态为 Leader,说明该节点被选举为 Leader,在切换到 Master 节点之前,首先需要等待当前节点追加的数据都已经被提交后才可以将状态变更为 Master,其关键实现如下:
- 如果 ledgerEndIndex 为 -1,表示当前节点还未又数据转发,直接跳出循环,无需等待。
- 如果 ledgerEndIndex 不为 -1 ,则必须等待数据都已提交,即 ledgerEndIndex 与 committedIndex 相等。
- 并且需要等待 commitlog 日志全部已转发到 consumequeue中,即 ReputMessageService 中的 reputFromOffset 与 commitlog 的 maxOffset 相等。
等待上述条件满足后,即可以进行状态的变更,需要恢复 ConsumeQueue,维护每一个 queue 对应的 maxOffset,然后将 broker 角色转变为 master。
经过上面的步骤,就能实时完成 broker 主节点的自动切换。由于单从代码的角度来看主从切换不够直观,下面我将给出主从切换的流程图。
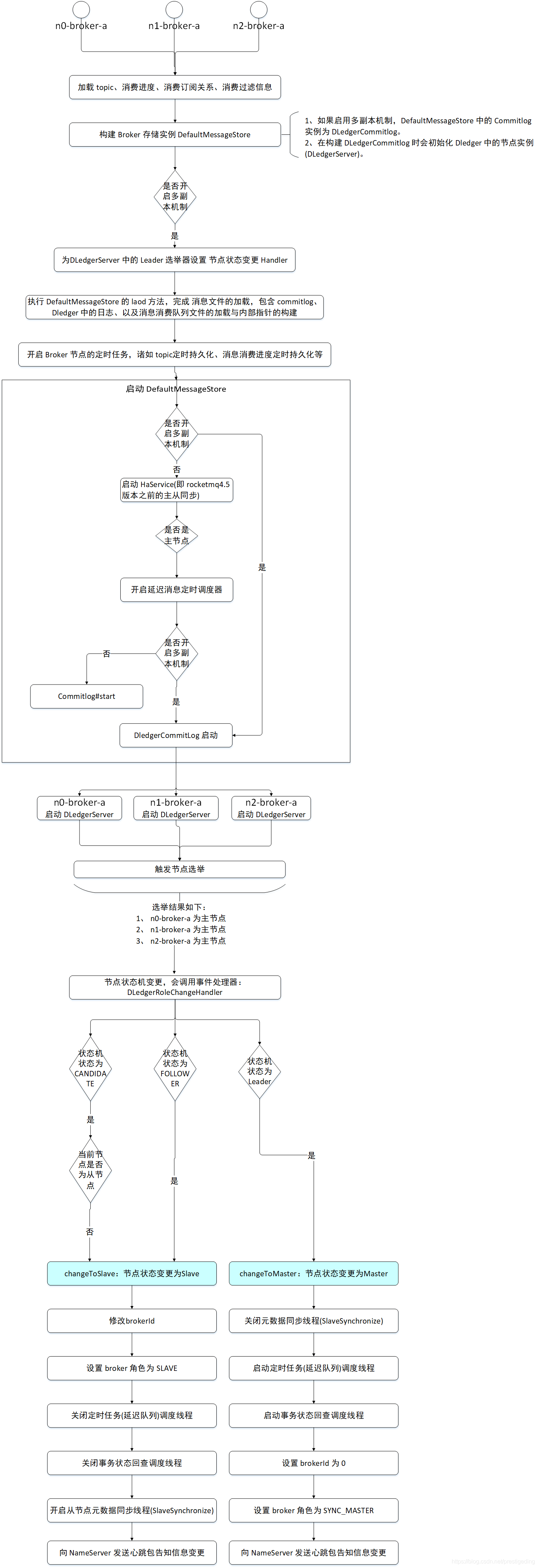
2.3 主从切换流程图
由于从源码的角度或许不够直观,故本节给出其流程图。
> 温馨提示:该流程图的前半部分在 源码分析 RocketMQ 整合 DLedger(多副本)实现平滑升级的设计技巧 该文中有所阐述。
![在这里插入图片描述]()
3、主从切换若干问题思考
我相信经过上面的讲解,大家应该对主从切换的实现原理有了一个比较清晰的理解,我更相信读者朋友们会抛出一个疑问,主从切换会不会丢失消息,消息消费进度是否会丢失而导致重复消费呢?
3.1 消息消费进度是否存在丢失风险
首先,由于 RocketMQ 元数据,当然也包含消息消费进度的同步是采用的从服务器定时向主服务器拉取进行更新,存在时延,引入 DLedger 机制,也并不保证其一致性,DLedger 只保证 commitlog 文件的一致性。
当主节点宕机后,各个从节点并不会完成同步了消息消费进度,于此同时,消息消费继续,此时消费者会继续从从节点拉取消息进行消费,但汇报的从节点并不一定会成为新的主节点,故消费进度在 broker 端存在丢失的可能性。当然并不是一定会丢失,因为消息消费端只要不重启,消息消费进度会存储在内存中。
综合所述,消息消费进度在 broker 端会有丢失的可能性,存在重复消费的可能性,不过问题不大,因为 RocketMQ 本身也不承若不会重复消费。
3.2 消息是否存在丢失风险
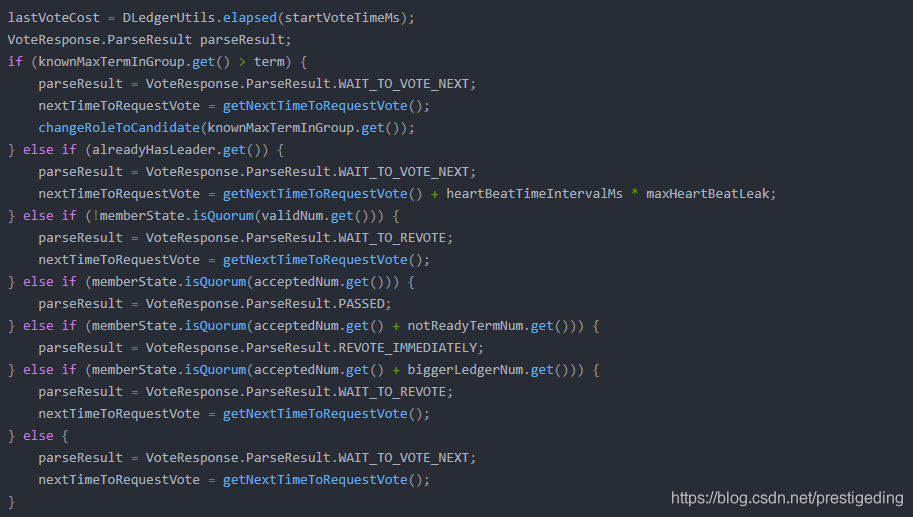
消息会不会丢失的关键在于,日志复制进度较慢的从节点是否可以被选举为主节点,如果在一个集群中,从节点的复制进度落后与从主节点,但当主节点宕机后,如果该从节点被选举成为新的主节点,那这将是一个灾难,将会丢失数据。关于一个节点是否给另外一个节点投赞成票的逻辑在 源码分析 RocketMQ DLedger 多副本之 Leader 选主 的 2.4.2 handleVote 方法中已详细介绍,在这里我以截图的方式再展示其核心点: ![在这里插入图片描述]()
![在这里插入图片描述]()
从上面可以得知,如果发起投票节点的复制进度比自己小的话,会投拒绝票。
![在这里插入图片描述]()
![在这里插入图片描述]()
必须得到集群内超过半数节点认可,即最终选举出来的主节点的当前复制进度一定是比绝大多数的从节点要大,并且也会等于承偌给客户端的已提交偏移量。故得出的结论是不会丢消息。
本文的介绍就到此为止了,最后抛出一个思考题与大家相互交流学习,也算是对 DLedger 多副本即主从切换一个总结回顾。答案我会以留言的方式或在下一篇文章中给出。
4、思考题
例如一个集群内有5个节点的 DLedgr 集群。 Leader Node: n0-broker-a folloer Node: n1-broker-a,n2-broker-a,n3-broker-a,n4-broker-a
从节点的复制进度可能不一致,例如: n1-broker-a复制进度为 100 n2-broker-a复制进度为 120 n3-broker-a复制进度为 90 n4-broker-a负载进度为 90
如果此时 n0-broker-a 节点宕机,触发选主,如果 n1率先发起投票,由于 n1,的复制进度大于 n3,n4,再加上自己一票,是有可能成为leader的,此时消息会丢失吗?为什么?
欢迎大家以留言的方式进行交流,也可以加我微信号 dingwpmz 与我进行探讨,最后如果这篇文章对大家有所帮助的话,麻烦点个赞,谢谢大家。
> 作者简介:《RocketMQ技术内幕》作者,RocketMQ 社区布道师,维护公众号:中间件兴趣圈,重点关注JAVA集合、JAVA并发包、Netty、Dubbo、RocketMQ、Mybatis、Elasticsearch、Netty。可扫描如下二维码与作者进行互动。
![]()