文章摘自github,本次测试选用 HanLP 1.6.0 , LTP 3.4.0
测试思路
使用同一份语料训练两个分词库,同一份测试数据测试两个分词库的性能。
语料库选取1998年01月的人民日报语料库。199801人民日报语料
该词库带有词性标注,为了遵循LTP的训练数据集格式,需要处理掉词性标注。
测试数据选择SIGHan2005提供的开放测试集。
SIGHan2005的使用可以参见其附带的readme。
HanLP
java -cp libs/hanlp-1.6.0.jar com.hankcs.hanlp.model.perceptron.Main -task CWS -train -reference ../OpenCorpus/pku98/199801.txt -model cws.bin
mkdir -p data/model/perceptron/pku199801
mv -f cws.bin data/model/perceptron/pku199801/cws.bin
默认情况下,训练的迭代次数为5。
修改 src/main/resouces 文件:
root=../test-hanlp-ltp
打包命令:
gradle clean build
SIGHan2005的MSR测试集
执行命令:
java -cp build/libs/test-hanlp-ltp-1.0-SNAPSHOT.jar com.zongwu33.test.TestForSIGHan2005 ../NLP/icwb2-data/testing/msr_test.utf8 segment-msr-result.txt
将分词的结果生成到segment-msr-result.txt文件里。 利用SIGHan2005的脚本生成分数:
perl ../NLP/icwb2-data/scripts/score ../NLP/icwb2-data/gold/msr_training_words.utf8 \
../NLP/icwb2-data/gold/msr_test_gold.utf8 segment-msr-result.txt > score-msr.ut8
可以得到 HanLP在MSR数据集上的测试结果:
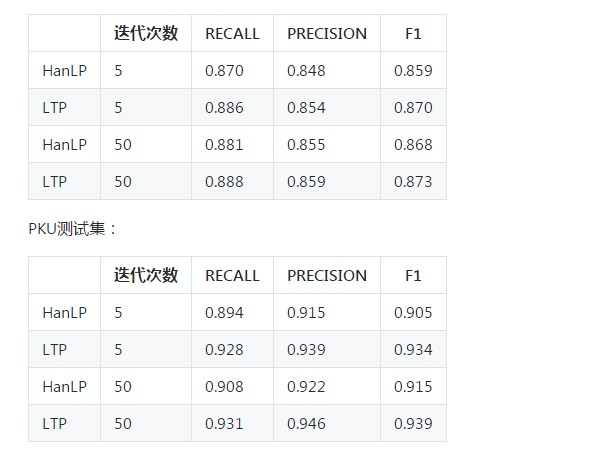
=== TOTAL TRUE WORDS RECALL: 0.870
=== TOTAL TEST WORDS PRECISION: 0.848
=== F MEASURE: 0.859
SIGHan2005的PKU测试集
java -cp build/libs/test-hanlp-ltp-1.0-SNAPSHOT.jar com.zongwu33.test.TestForSIGHan2005 ../NLP/icwb2-data/testing/pku_test.utf8 segment-pku-result.txt
perl ../NLP/icwb2-data/scripts/score ../NLP/icwb2-data/gold/pku_training_words.utf8 ../NLP/icwb2-data/gold/pku_test_gold.utf8 segment-pku-result.txt > score-pku.utf8
结果:
=== TOTAL TRUE WORDS RECALL: 0.894
=== TOTAL TEST WORDS PRECISION: 0.915
=== F MEASURE: 0.905
Docker安装 LTP
LTP
生成符合LTP训练格式的训练集文件:
java -cp build/libs/test-hanlp-ltp-1.0-SNAPSHOT.jar com.zongwu33.test.CreateSimpleCorpus ../OpenCorpus/pku98/199801.txt simple-199801.txt
simple-199801.txt 即为结果。 训练集 和开发集都指定为这个文件:
../LTP/ltp-3.4.0/tools/train/otcws learn --model model-test --reference simple-199801.txt --development simple-199801.txt --max-iter 5
SIGHan2005的MSR测试集
测试:
../LTP/ltp-3.4.0/tools/train/otcws test --model model-test --input /data/testLTP/icwb2-data/testing/msr_test.utf8 > msr_result.txt
利用SIGHan2005的脚本生成分数:
perl icwb2-data/scripts/score icwb2-data/gold/msr_training_words.utf8 \
icwb2-data/gold/msr_test_gold.utf8 msr_result.txt > ltp-msr-score.utf8
查看ltp-msr-score.utf8 :
=== TOTAL TRUE WORDS RECALL: 0.886
=== TOTAL TEST WORDS PRECISION: 0.854
=== F MEASURE: 0.870
SIGHan2005的PKU测试集
../LTP/ltp-3.4.0/tools/train/otcws test --model model-test --input /data/testLTP/icwb2-data/testing/pku_test.utf8 > pku_result.txt
perl icwb2-data/scripts/score icwb2-data/gold/pku_training_words.utf8 \
icwb2-data/gold/pku_test_gold.utf8 pku_result.txt > ltp-pku-score.ut8
=== TOTAL TRUE WORDS RECALL: 0.928
=== TOTAL TEST WORDS PRECISION: 0.939
=== F MEASURE: 0.934
对比
MSR测试集:
![230b6a40680b7ea9280c9ec722511c831e65412c]()
性能测试
阿里云ECS机器配置:
机器配置:Intel Xeon CPU *4 2.50GHz,内存16G
测试数据集 20M的网络小说,约140315句(不含空行)。
HanLP
java -cp test-hanlp-ltp-1.0-SNAPSHOT.jar com.zongwu33.test.PerformanceTest ../NLP/strict-utf8-booken.txt
init model: 313 ms
total time:15677 ms
total num:140315
需要15.677 s,可以计算得到处理速度 1375k/s 。
LTP
../LTP/ltp-3.4.0/tools/train/otcws test --model model-test --input strict-utf8-booken.txt > /dev/null
[INFO] 2018-03-26 17:04:19 ||| ltp segmentor, testing ...
[INFO] 2018-03-26 17:04:19 report: input file = strict-utf8-booken.txt
[INFO] 2018-03-26 17:04:19 report: model file = model-test
[INFO] 2018-03-26 17:04:19 report: evaluate = false
[INFO] 2018-03-26 17:04:19 report: sequence probability = false
[INFO] 2018-03-26 17:04:19 report: marginal probability = false
[INFO] 2018-03-26 17:04:19 report: number of labels = 4
[INFO] 2018-03-26 17:04:19 report: number of features = 491820
[INFO] 2018-03-26 17:04:19 report: number of dimension = 1967296
[INFO] 2018-03-26 17:05:13 Elapsed time 53.680000
需要53s。处理速度389k/s。
对比
![33155d2c5d65d8c1e769f2bc0d7ac87576a0d00f]()
开源协议
Apache License Version 2.0