一、操作系统基础:
进程的概念起源于操作系统,操作系统其它所有概念都是围绕进程来的,所以我们了解进程之前先来了解一下操作系统
操作系统位于计算机硬件与应用软件之间,本质也是一个软件。操作系统由操作系统的内核(运行于内核态,管理硬件资源)以及系统调用(运行于用户态,为应用程序员写的应用程序提供系统调用接口)两部分组成
两大功能:
1.将复杂的硬件操作封装成简单的接口给应用程序或者用户去使用
2.将多个进程对硬件的竞争变得有序
操作系统处理进程的发展简略:
1.串行:一个任务完整的运行完毕才运行下一个任务
2.并发:多个任务看起来是同时运行的
3.多道技术(复用-->共享)
(1)空间上的复用:多个任务复用内存空间
(2)时间上的复用:多个任务复用cpu的时间
时间上的复用又分为两种:
-
一个任务占用时间过长会被操作系统剥夺走cpu的执行权限:比起串行执行反而降低效率
- 一个任务遇到IO操作也会被操作系统剥夺走cpu的执行权限:比起串行执行可以提升效率
二、进程
程序仅仅是一堆代码而已,而进程指的是程序运行的过程
(一)、进程的创建
开启进程的方式1:(直接使用Process)
![]()
![]()
from multiprocessing import Process
import time
def task(name):
print('%s is running'%name)
time.sleep(3)
print('%s is done'%name)
#在windows系统上,开启子进程的操作必须放到 if __name__ == '__main__':中,避免递归
if __name__ == '__main__':
p = Process(target=task,args=('egon',))
# Process(target=task,kwargs={'name':'egon'})
p.start()#只是向操作系统发送了一个开启子进程的信号
print('主')
View Code
开启进程的方式2:(继承Process来自定义类,重写run方法)
![]()
![]()
from multiprocessing import Process
import time
class Myprocess(Process):
def __init__(self,name):
super().__init__()
self.name = name
def run(self):
print('%s is running' % self.name)
time.sleep(3)
print('%s is done' % self.name)
if __name__ == '__main__':
p = Myprocess('egon')
p.start()
print('主')
View Code
结果都为:
主
egon is running
egon is done
注:run:如果在创建Process对象的时候不指定target,那么就会默认执行Process的run方法:
(二)、join方法
join阻塞当前进程,直到调用join方法的那个进程执行完,再继续执行当前进程
![]()
![]()
from multiprocessing import Process
import time
def task(name,n):
print('%s is running'%name)
time.sleep(n)
print('%s is done'%name)
if __name__ == '__main__':
start = time.time()
p_j =[]
for i in range(1,4):
p = Process(target=task,args=('egon',i))
p.start()
p_j.append(p)
for i in p_j:
i.join()
print(time.time() - start)
print('主')
View Code
当不加join方法时,主进程先运行完毕,加了join就会等子进程运行完毕后才运行主进程,先依次调用start启动进程,再依次调用join要求主进程等待子进程的结束。
为什么要先依次调用start再调用join,而不是start完了就调用join
![]()
![]()
from multiprocessing import Process
import time
def task(name,n):
print('%s is running'%name)
time.sleep(n)
print('%s is done'%name)
if __name__ == '__main__':
p1 = Process(target=task,args=('egon',1))
p2 = Process(target=task,args=('alex',2))
start = time.time()
p1.start()
p1.join()
p2.start()
p2.join()
print(time.time() - start)
print('主')
View Code
![]()
程序变成了串行执行,并不是并发了。
(三)进程直接的内存空间互相隔离
![]()
![]()
from multiprocessing import Process
import time
n=100
def task():
global n
n=0
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print(n)#100
View Code
主进程与子进程之间互不干扰,子进程是对主进程的拷贝。
(四)、进程对象其他相关属性或方法
进程pid(每一个进程在操作系统内都有一个唯一的id号)
使用multiprocessing内的current_process
![]()
![]()
from multiprocessing import Process,current_process
import time
def task():
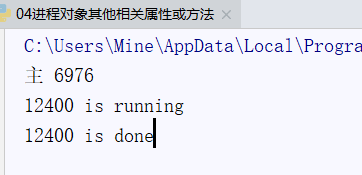
print('%s is running'%current_process().pid)
time.sleep(3)
print('%s is done'%current_process().pid)
if __name__ == '__main__':
p = Process(target=task)
p.start()
print('主 %s'%current_process().pid)
View Code
![]()
使用os模块下的getpid方法
![]()
![]()
from multiprocessing import Process,current_process
import time,os
def task():
print('%s is running'%os.getpid())
time.sleep(3)
print('%s is done'%os.getpid())
if __name__ == '__main__':
p = Process(target=task)
p.start()
print('主 %s'%os.getpid())
View Code
getppid()获取进程的主进程id号
![]()
![]()
from multiprocessing import Process,current_process
import time,os
def task():
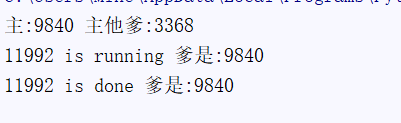
print('%s is running 爹是:%s' %(os.getpid(),os.getppid()))
time.sleep(30)
print('%s is done 爹是:%s' %(os.getpid(),os.getppid()))
if __name__ == '__main__':
p=Process(target=task)
p.start()
print('主:%s 主他爹:%s' %(os.getpid(),os.getppid()))
View Code
![]()
from multiprocessing import Process,current_process
import time,os
def task():
print('%s is running'%os.getpid())
time.sleep(3)
print('%s is done'%os.getpid())
if __name__ == '__main__':
p = Process(target=task,name='子进程1')
p.start()
print(p.name)#查看进程名
# p.terminate()杀死子进程
print(p.is_alive())#查看子进程是否存活
print('主 %s'%os.getpid())
(五)、僵尸进程与孤儿进程
僵尸进程:子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程 到底什么时候结束。在 unix 或 linux 的系统中,当一个子进程退出后,它就会变成一个僵尸进程,如果父进程没有通过 wait 或者waitpid()系统调用来读取这个子进程的退出状态的话,这个子进程就会一直维持僵尸进程状态。
僵尸进程的危害:如果进程不调用wait / waitpid的话, 那么保留的那段信息就不会释放,其进程号就会一直被占用,但是系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
孤儿进程:如果一个子进程的父进程先于子进程结束,则该子进程将变成孤儿进程。它将由init进程收养,称为init进程的子进程。init就是孤儿院
清除僵尸进程:方法1,结束父进程(主进程),当父进程退出的时候,僵尸进程也会被清除
方法2,在处理程序中调用 wait 系统调用来清除僵尸进程
(六)、守护进程
守护进程本质就是一个“子进程”,该“子进程”的什么周期小于等于被守护进程的生命周期
p.daemon = True#放在start前面
![]()
![]()
from multiprocessing import Process
import time
def task(name):
print('太监 %s活着。。。'%name)
time.sleep(3)
print('太监 %s死了。。。'%name)
if __name__ == '__main__':
p = Process(target=task,args=('lxx',))
p.daemon = True#放在start前面
p.start()
print('egon 正在死...')
View Code
(七)、互斥锁
每个进程互相独立,相互之间没有任何关系,某个进程要更改共享数据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成“非锁定”,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
![]()
![]()
import json
import time,random
from multiprocessing import Process,Lock
def search(name):
with open('db.json','rt',encoding='utf-8') as f:
dic=json.load(f)
time.sleep(1)
print('%s 查看到余票为 %s' %(name,dic['count']))
def get(name):
with open('db.json','rt',encoding='utf-8') as f:
dic=json.load(f)
if dic['count'] > 0:
dic['count'] -= 1
time.sleep(random.randint(1,3))
with open('db.json','wt',encoding='utf-8') as f:
json.dump(dic,f)
print('%s 购票成功' %name)
else:
print('%s 查看到没有票了' %name)
def task(name,mutex):
search(name) #并发
mutex.acquire()
get(name) #串行
mutex.release()
# with mutex:
# get(name)
if __name__ == '__main__':
mutex = Lock()
for i in range(10):
p=Process(target=task,args=('路人%s' %i,mutex))
p.start()
# p.join() # join只能将进程的任务整体变成串行
View Code
焚膏油以继晷,恒兀兀以穷年。