本文主要分析 SpringCloud 中 Ribbon 负载均衡流程和原理。
SpringCloud版本为:Edgware.RELEASE。
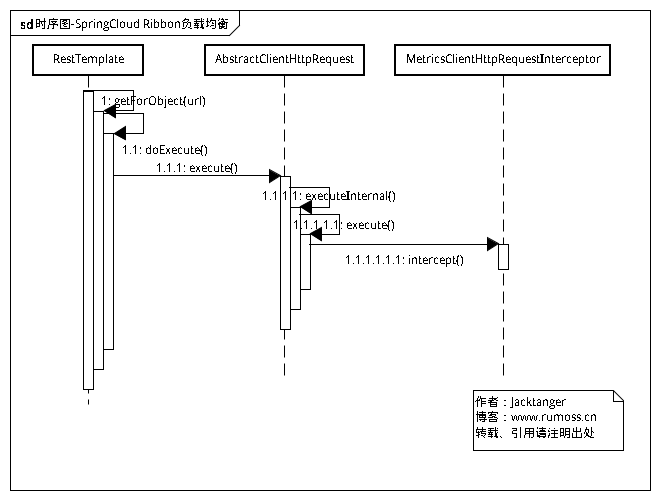
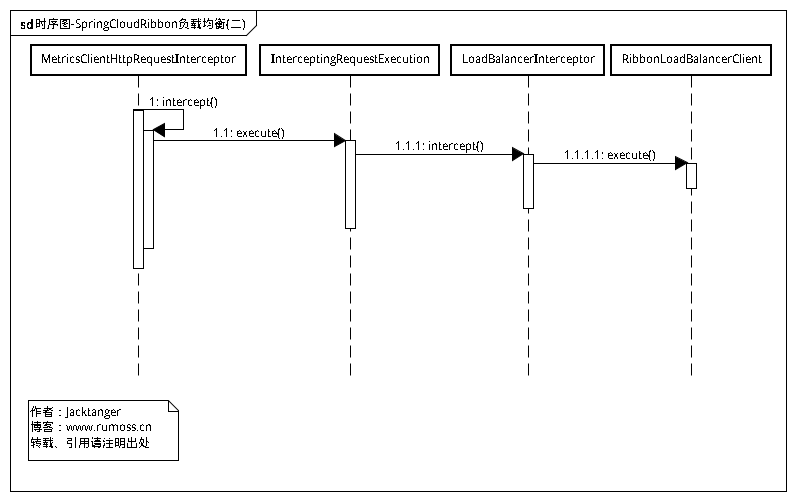
一.时序图
和以前一样,先把图贴出来,直观一点:
![]()
![]()
二.源码分析
我们先从 contoller 里面看如何使用 Ribbon 来负载均衡的:
@GetMapping("/user/{id}")
public User findById(@PathVariable Long id) {
//return this.restTemplate.getForObject("http://192.168.2.110:8001/" + id, User.class);
return this.restTemplate.getForObject("http://microservice-provider-user/" + id, User.class);
}
可以看到,在整合 Ribbon 之前,请求Rest是通过IP端口直接请求。整合 Ribbon 之后,请求的地址改成了 http://applicationName ,官方取名为虚拟主机名(virtual host name),当 Ribbon 和 Eureka 配合使用时,会自动将虚拟主机名转换为微服务的实际IP地址,我们后面会分析这个过程。
首先从 RestTemplate#getForObject 开始:
public <T> T getForObject(String url, Class<T> responseType, Object... uriVariables) throws
RestClientException {
// 设置RequestCallback的返回类型responseType
RequestCallback requestCallback = acceptHeaderRequestCallback(responseType);
// 实例化responseExtractor
HttpMessageConverterExtractor<T> responseExtractor =
new HttpMessageConverterExtractor<T>(responseType, getMessageConverters(), logger);
return execute(url, HttpMethod.GET, requestCallback, responseExtractor, uriVariables);
}
接着执行到 RestTemplate 的 execute,主要是拼装URI,如果存在baseUrl,则插入baseUrl。拼装好后,进入实际"执行"请求的地方:
public <T> T execute(String url, HttpMethod method, RequestCallback requestCallback,
ResponseExtractor<T> responseExtractor, Object... uriVariables) throws
RestClientException {
// 组装 URI
URI expanded = getUriTemplateHandler().expand(url, uriVariables);
// 实际"执行"的地方
return doExecute(expanded, method, requestCallback, responseExtractor);
}
RestTemplate#doExecute,实际“执行”请求的地方,执行超过后,返回 response:
protected <T> T doExecute(URI url, HttpMethod method, RequestCallback requestCallback,
ResponseExtractor<T> responseExtractor) throws RestClientException {
ClientHttpResponse response = null;
try {
// 实例化请求,url为请求地址,method为GET
ClientHttpRequest request = createRequest(url, method);
if (requestCallback != null) {// AcceptHeaderRequestCallback
requestCallback.doWithRequest(request);
}
// 实际处理请求的地方
response = request.execute();
// 处理response,记录日志和调用对应的错误处理器
handleResponse(url, method, response);
if (responseExtractor != null) {// 使用前面的HttpMessageConverterExtractor从Response里面抽取数据
return responseExtractor.extractData(response);
}
else {
return null;
}
}
......
}
到了请求被执行的地方,AbstractClientHttpRequest#execute,跳转到 executeInternal:
public final ClientHttpResponse execute() throws IOException {
// 断言请求还没被执行过
assertNotExecuted();
// 跳转到 executeInternal 处理请求
ClientHttpResponse result = executeInternal(this.headers);
// 标记请求为已经执行过
this.executed = true;
return result;
}
AbstractBufferingClientHttpRequest#executeInternal,AbstractBufferingClientHttpRequest是AbstractClientHttpRequest的子抽象类,作用是缓存output,使用了一个字节数组输出流:
protected ClientHttpResponse executeInternal(HttpHeaders headers) throws IOException {
// 首次进来,bytes内容为空
byte[] bytes = this.bufferedOutput.toByteArray();
if (headers.getContentLength() < 0) {
// 设置 Content-Length 为 1
headers.setContentLength(bytes.length);
}
// 模板方法,跳转到了实现类中的方法,InterceptingClientHttpRequest#executeInternal
ClientHttpResponse result = executeInternal(headers, bytes);
// 拿到结果后,清空缓存
this.bufferedOutput = null;
return result;
}
executeInternal是一个抽象方法,跳转到了其实现类InterceptingClientHttpRequest#executeInternal:
protected final ClientHttpResponse executeInternal(HttpHeaders headers, byte[] bufferedOutput)
throws IOException {
InterceptingRequestExecution requestExecution = new InterceptingRequestExecution();
// InterceptingRequestExecution是一个内部类
return requestExecution.execute(this, bufferedOutput);
}
// 内部类,负责执行请求
private class InterceptingRequestExecution implements ClientHttpRequestExecution {
private final Iterator<ClientHttpRequestInterceptor> iterator;// 所有HttpRequest的拦截器
public InterceptingRequestExecution() {
this.iterator = interceptors.iterator();
}
@Override
public ClientHttpResponse execute(HttpRequest request, byte[] body) throws IOException {
if (this.iterator.hasNext()) {// 如果还有下一个拦截器,则执行其拦截方法
// 这里的拦截器是 MetricsClientHttpRequestInterceptor,对应"metrics"信息,记录执行时间和结果
ClientHttpRequestInterceptor nextInterceptor = this.iterator.next();
// 执行拦截方法
return nextInterceptor.intercept(request, body, this);
}
......
}
}
跳转到了拦截器 MetricsClientHttpRequestInterceptor 的拦截方法:
public ClientHttpResponse intercept(HttpRequest request, byte[] body,
ClientHttpRequestExecution execution) throws IOException {
long startTime = System.nanoTime();// 标记开始执行时间
ClientHttpResponse response = null;
try {
// 传入请求和Body,处理执行,又跳转回 InterceptingRequestExecution
response = execution.execute(request, body);
return response;
}
finally {// 在执行完方法,返回response之前,记录一下执行的信息
SmallTagMap.Builder builder = SmallTagMap.builder();
for (MetricsTagProvider tagProvider : tagProviders) {
for (Map.Entry<String, String> tag : tagProvider
.clientHttpRequestTags(request, response).entrySet()) {
builder.add(Tags.newTag(tag.getKey(), tag.getValue()));
}
}
MonitorConfig.Builder monitorConfigBuilder = MonitorConfig
.builder(metricName);
monitorConfigBuilder.withTags(builder);
// 记录执行时间
servoMonitorCache.getTimer(monitorConfigBuilder.build())
.record(System.nanoTime() - startTime, TimeUnit.NANOSECONDS);
}
}
又跳转回了 InterceptingRequestExecution,下个拦截器是 - LoadBalancerInterceptor,最后的Boss,调用LoadBalancerClient完成请求的负载。
LoadBalancerInterceptor#intercept,主角登场了,终于等到你,还好没放弃:
public ClientHttpResponse intercept(final HttpRequest request, final byte[] body,
final ClientHttpRequestExecution execution) throws IOException {
// 获取原始URI
final URI originalUri = request.getURI();
// 获取请求中的服务名字,也就是所谓的"虚拟主机名"
String serviceName = originalUri.getHost();
// 转由 LoadBalancerClient 处理请求
return this.loadBalancer.execute(serviceName, requestFactory.createRequest(request, body, execution));
}
下面空一行先停下来休息一下,然后看看,负载均衡是怎样实现的。
LoadBalancerInterceptor这里默认的实现是 RibbonLoadBalancerClient,Ribbon是Netflix发布的负载均衡器。
RibbonLoadBalancerClient#execute,负载均衡算法选出实际处理请求的Server:
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {
// serviceId即前面的虚拟主机名 "microservice-provider-user",获取loadBalancer
//这里获取到的是 DynamicServerListLoadBalancer
ILoadBalancer loadBalancer = getLoadBalancer(serviceId);
// 基于loadBalancer,选择实际处理请求的服务提供者
Server server = getServer(loadBalancer);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonServer ribbonServer = new RibbonServer(serviceId, server, isSecure(server,
serviceId), serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
}
RibbonLoadBalancerClient#getServer,转交 loadBalancer 选择Server:
protected Server getServer(ILoadBalancer loadBalancer) {
if (loadBalancer == null) {
return null;
}
// 由 loadBalancer 完成选Server的重任,这里的 key 是默认值 "default"
return loadBalancer.chooseServer("default"); // TODO: better handling of key
}
chooseServer也是一个抽象的模板方法,最后的实现是 ZoneAwareLoadBalancer#chooseServer:
public Server chooseServer(Object key) {
if (!ENABLED.get() || getLoadBalancerStats().getAvailableZones().size() <= 1) {
logger.debug("Zone aware logic disabled or there is only one zone");
// 到了 BaseLoadBalancer的chooseServer
return super.chooseServer(key);
}
......
}
BaseLoadBalancer#chooseServer,转交规则来选择Server:
public Server chooseServer(Object key) {
if (counter == null) {
counter = createCounter();
}
// counter是一个计数器,起始值是"0",下面自增一次,变为 "1"
counter.increment();
if (rule == null) {
return null;
} else {
try {
// 默认的挑选规则是 "ZoneAvoidanceRule"
return rule.choose(key);
} catch (Exception e) {
logger.warn("LoadBalancer [{}]: Error choosing server for key {}", name, key, e);
return null;
}
}
}
PredicateBasedRule是ZoneAvoidanceRule的父类。PredicateBasedRule#choose,可以看到,基础负载规则采用的是"RoundRobin"即轮询的方式:
public Server choose(Object key) {
ILoadBalancer lb = getLoadBalancer();
Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);
if (server.isPresent()) {
return server.get();
} else {
return null;
}
}
下面分析"轮询"的过程,AbstractServerPredicate#chooseRoundRobinAfterFiltering,传入Server列表的长度,自增取模实现:
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {
// 首先拿到所有"合格"的Server
List<Server> eligible = getEligibleServers(servers, loadBalancerKey);
if (eligible.size() == 0) {
return Optional.absent();
}
// 在 incrementAndGetModulo 中获取,"自增取模"
return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));
}
AbstractServerPredicate#incrementAndGetModulo,维护了一个nextIndex,记录下次请求的下标:
private int incrementAndGetModulo(int modulo) {
for (;;) {
int current = nextIndex.get();// 第一次 current是"0"
int next = (current + 1) % modulo;// current+1对size取模,作为下次的"current"
// "0" == current,则以原子方式将该值设置为 next
if (nextIndex.compareAndSet(current, next))
return current;
}
}
最后,我们通过控制台来验证一下请求是不是"轮询"分配到服务提供者的,本地启动了8000和8001两个Provider:
2018-12-09 18:55:30.794 c.i.c.s.user.controller.MovieController : microservice-provider-user:192.168.2.117:8001
2018-12-09 18:55:33.196 c.i.c.s.user.controller.MovieController : microservice-provider-user:192.168.2.117:8000
2018-12-09 18:55:34.713 c.i.c.s.user.controller.MovieController : microservice-provider-user:192.168.2.117:8001
2018-12-09 18:55:34.975 c.i.c.s.user.controller.MovieController : microservice-provider-user:192.168.2.117:8000
2018-12-09 18:55:35.175 c.i.c.s.user.controller.MovieController : microservice-provider-user:192.168.2.117:8001
2018-12-09 18:55:35.351 c.i.c.s.user.controller.MovieController : microservice-provider-user:192.168.2.117:8000
2018-12-09 18:55:35.534 c.i.c.s.user.controller.MovieController : microservice-provider-user:192.168.2.117:8001
可以看到,请求确实被轮询给两个Provider处理的。
至此,我们完成了 SpringCloud 中 Ribbon 负载均衡的过程,知道了默认采用的是"轮询"的方式,实现是通过维护一个index,自增后取模来作为下标挑选实际响应请求的Server。除了轮询的方式,还有随机等算法。感兴趣可以按照类似思路分析测试一下。