对于刚接触TCP网络编程的人有时候碰到一些问题,比如当客服端发送一串消息到服务端,服务端只收到消息的一半,或者当连续发送两个消息到服务端,服务端同时收到这两个消息但无法解析。这就是今天要讲的TCP拆包粘包现象。
拆包粘包产生的原因
我们可以通过以下图进行说明
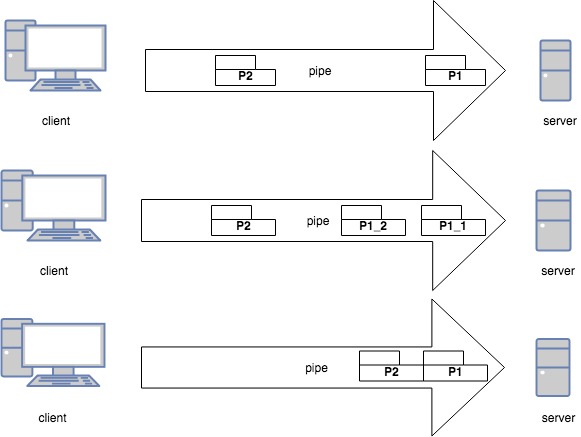
![]()
1.图一是正常的情况下包的发送和接受,客户端发送p1,p2包,服务端先后接受到p1,p2包,没有发生粘包和拆包。
2.图二是发生了拆包的现象。客户端发送p1,p2包,客户端对p1拆包分成p1_1和p1_2,服务端先后收到p1_1,p1_2和p2包。 拆包发生原因分2种情况:
- (1)发送的数据大于套接字缓冲区剩余大小。
- (2)发送的数据大于MTU(最大传输单元)大小。
在TCP通讯协议中TCP的每个包的头的长度都是固定的,总长度不能超过MTU(最大传输单元),且数据长度不能超过MSS(MSS=MTU-20bytes(IP包头)-20bytes(TCP包头))。如果超过了MTU系统会进行拆包处理。以图二举个例子:
- (1)假设MTU设置的长度为1500bytes则MSS为1460bytes。
- (2)客户端发送了p1包数据大小2000bytes。
- (3)系统判断总长度超过了MTU大小,需要拆包处理。
- (4)拆成2个包p1_1和p1_2,p1_1的总长度=1460+20+20=1500,p1_2的总长度=2000-1460+20+20=580。
- (5)发送包p1_1和包p1_2。
3.图三是发生了粘包的现象。客户端发送p1,p2包,p1,p2包到达接收端的缓存,服务端应用读取缓存时无法区分p1,p2各自的大小。因为在TCP通讯协议中TCP是面向流的,包和包之间没有界限。粘包可发生在发送端也可发生在接收端以图三各举例子:
- (1)发送端原因导致的粘包,客户端在发送p1包时,先将p1包放入发送缓存,由于Nagle算法判断其发送的可用数据(去头数据)过小等待一小段时间,这时又发送了p2包,系统将p1和p2合成一个大包发送给服务端。服务端读到大包,无法区分p1和p2包。
- (2)接收端原因导致的粘包,服务端缓存接收到客户端发送的p1包,服务端应用未能及时读取缓存,此时服务端缓存又接收到客户端发送的p2包,服务端应用读取缓存,无法区分p1和p2包。
解决方案
无论拆包还是粘包本质问题都是无法区分包界限,解决包界限的问题主要有以下几种方式:
- (1)消息数据的定长,比如定长100字节,不足补空格,接收方收到后解析100字节数据即为完整数据。但这样的做的缺点是浪费了部分存储空间和带宽。
- (2)消息数据使用特定分割符区分界限,比如使用换号符号做分割。
- (3)把消息数据分成消息头和消息体,消息头带消息的长度,接收方收到后根据消息头中的长度解析数据。
在实际开发中很多网络框架对TCP拆包粘包问题的解决做了很多支持,比如netty中LineBasedFrameDecoder解析器就是利用换号符号做分割。