在日前举行的Computex 2018媒体发布会上,AMD有些出人意料地进行了高规格的产品发布,公开的产品包括下一代使用7nm工艺的VEGA GPU,以及使用7nm的Zen 2处理器。目前,7nm VEGA GPU是全球第一个使用7nm工艺的GPU,现在已经开始样品出货,预计在今年下半年开始大规模出货。这比之前预期的时间表提前了不少,也打了Nvidia一个措手不及,让AMD以迅雷不及掩耳之势抢得了“全球第一块7nm GPU”。
![34c6b505794522cd534e9b81739b1b751970b967]()
除了GPU之外,AMD还公布了下一代使用7nm工艺的Zen 2处理器EPYC,该处理器目前已经完成流片正处于实验室测试中,预计将于2018年下半年进入工程样品阶段并于2019年进入大规模出货阶段。
随着桌面PC市场被移动设备日渐蚕食,在本世纪初热闹非凡的Computex会议已经几乎被人遗忘。而AMD此次在Computex会议上举行的高规格产品发布无疑是为之前有些疲软的计算机市场和Computex会议带来了一阵新风。这也释放了一个重要信号:以数据中心为主要应用场景的高性能计算市场正在接过PC的接力棒,将会成为计算机在下一个十年发展的主要动力。
数据中心的想象空间
![1d07c682e3a89087deee240420a138c78a11bca8]()
随着大数据和深度学习的高速发展,数据正在成为新时代的原油而算力正在成为下一代的基础设施。AMD在发布会上指出,到2025年的数据将会增长50倍:可穿戴设备、IoT、5G设备正在普及,这些设备都会产生大量的数据。除此之外,我们对于这些数据的处理方式也越来越复杂,机器学习领域的新算法层出不穷,能够从数据中提取更多有用信息,从而在智慧城市、医疗、金融、安保等领域引入革命性的变化。随着数据量和算法复杂度的飞速提升,对于算力的需求也在高速增长。
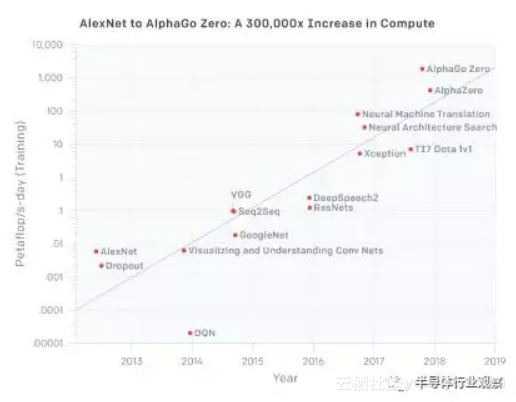
![b2103b4c24e9e8121eb9c063b371d0c9dd17e54b]()
OpenAI公布的深度学习算法算力需求,6年增长了30万倍
大数据算力的主要基础设施在于数据中心。数据中心对于处理器的需求目前主要包括CPU和GPU。CPU是传统计算硬件,可以支持通用计算,也是数据中心必不可少的一部分。AMD此次公布的EPYC CPU每个socket至多可以支持32个核。除了核心数多之外,CPU的内存存取和CPU间通信在需要高效执行分布式计算的数据中心也是重要要素,而EPYC每个CPU能支持至多8个内存通道和128条PCIe通道,可谓性能强大。众所周知,AMD在数据中心CPU领域并非传统强项,在Intel牢牢把持着市场的情况下AMD如何打入数据中心CPU生态也就成了大家关注的要点之一。在本次发布会上,AMD宣布了EPYC已经进入了CISCO,HP和腾讯云等重要客户的产品中。虽然比起Intel在数据中心的市场份额来说AMD还有很大的差距,但是这也是个不错的出发点。
![9fa54f28e66531cf73e7465a55d9cddda4b8b577]()
除了CPU之外,GPU是数据中心想象空间更大的部分。在大数据时代,CPU并不能高效支持所有运算:在CPU的芯片上,为了满足通用算法的支持,有很大一部分芯片面积都用来做缓存和控制逻辑(如分支判断等),而用于计算单元的面积并不大。而在大数据算法中,大量数据是可以并行处理的(例如来自不同设备产生的独立数据就可以并行处理而不会互相影响),因此大数据算法往往比较规整,而CPU芯片上的许多控制逻辑对于大数据算法就显得多余。这时候擅长并行计算处理的GPU就脱颖而出。GPU的设计中控制逻辑比较简单,而绝大部分芯片面积都用来做计算单元,因此一个GPU往往包含了数千个计算核心,可以提供超高效并行计算,对于合适的大数据算法GPU的执行速度比同代CPU要快两到三个数量级。
GPU在数据中心中执行大数据算法的标志性事件是2012年的深度学习算法AlexNet的训练。AlexNet是深度学习的标志性算法,其贡献第一是证明在数据量足够的情况下深度神经网络在图像分类等任务中的性能远好于传统的支持向量机(SVM)等算法,可谓是开启了这一波深度学习热潮;除此之外AlexNet还提出了使用GPU去训练深度学习网络,相比CPU可以将训练时间降低两到三个数量级从而进入合理的范围(时间从数年下降到了几天)。可以说以深度学习离不开GPU的支持,而随着深度学习的继续普及,数据中心对于GPU的需求也在持续上升。
深度学习的普及是GPU在数据中心需求量持续上升的一个要素。除此之外,深度学习以外的其他需要GPU的算法也在推动GPU需求。众所周知的是区块链算法对于GPU也有很大的需求量,在区块链和加密货币最火的2017年各大矿场对于GPU的需求甚至让GPU卖到断货(AMD从中也是获利颇丰),之后虽然加密货币逐渐回归理性但是对于GPU的需求却在稳步上升。除了区块链之外,数据库等传统应用也在逐渐拥抱GPU加速。可以说目前数据中心对于GPU的需求是以深度学习为首,而在其他领域也在逐渐跟上。Nvidia目前在数据中心GPU市场几乎是处于垄断地位,与之相应数据中心业务在Nvidia的财报中也越来越重要,2017财年的数据中心业务增长高达245%,在2018财年的增长也有233%,收入接近20亿美元。AMD当然不会对数据中心这块市场坐视不管,这次抢先Nvidia发布7nm VEGA GPU以及Radeon Instinct数据中心加速卡也是对Nvidia一个强烈的挑战信号。
除了硬件之外,
开发生态同样重要
在数据中心市场,事实上BAT等各大客户也希望AMD能打破Nvidia的垄断地位,从而让高性能GPU的价格能回归合理的范围。AMD这次发布的7nm VEGA GPU以及Radeon Instinct加速卡可谓性能强大,Radeon Instinct加速卡使用了32GB HBM高速显存,并且VEGA GPU对于人工智能和机器学习也加入了硬件支持,具体性能值得期待。
在硬件性能之外,开发者生态也是决定性因素。Nvidia的战略眼光极其深远,在绝大部分人对于GPU的认识还局限于游戏图形加速的时候,Nvidia就已经看到了GPU在其他领域的潜力,于是开始了GPGPU(通用GPU)战略并开始了CUDA的开发。在经过数年的开发积累之后,又遇到了深度学习的大热,Nvidia的CUDA凭借着稳定的性能,易用的API接口,完整的文档和多年的开发者社区运营成为了相关开发者的首选,配合其GPU因此成为了数据中心的标配。另一方面,AMD对于GPGPU类的技术投入之前一直处于不温不火的状态,和高通等其他几个合作厂商在推广与CUDA相似的OpenCL但是其性能和易用性一直被开发者社区诟病。除此之外AMD在GPGPU领域的另一个举措是推出异构系统架构HSA(heterogeneous system architecture),HSA的初衷是打通CPU和GPU的内存空间,用于解决CPU和GPU之间内存互访造成的性能损失,然而至今HSA也只能说是普普通通并未引起太多波澜。
AMD当然也认识到了其开发生态不足造成的问题,因此在这次发布会上也特意提到了其GPGPU的最新举措即Radeon Open Ecosystem,可以支持TensorFlow,PyTorch,Caffe,MxNet等主流机器学习平台并将提供优化的库支持。然而,在开发生态领域AMD仍然是处于追赶地位,尤其是在Nvidia在数据中心的生态已经开始在探索GPU数据库等蓝海的情况下,AMD如何迎头赶上值得我们关注。
![00e2df0c7355e250a74d38437df9b2f3e6172d06]()
7nm提升有限,
封装技术同样重要
从芯片角度,这次AMD的发布也让我们看到了半导体制程发展的趋势。
![8efe2ee80b7135550b9cbcec9122cbc217aceb0e]()
AMD发布了7nm VEGA GPU的数据。耐人寻味的是,其性能相对于上一代14nm的VEGA仅仅提升了35%。在特征尺寸缩小一半加上设计也有改善的情况下,其性能的提升幅度并不大:7nm半导体工艺节点中虽然特征尺寸缩小晶体管开关速度会加快但是金属互联线带来的延迟也变大,因此对于芯片性能的帮助有限。另一方面,其晶体管密度和功耗改善有两倍之多,这基本延续了之前摩尔定律的势头。
在特征尺寸对于芯片性能提升帮助有限的情况下,封装技术将会成为芯片性能提升的另一个推力。在本次发布会上,AMD发布的Radeon Instinct加速卡中一个最重要的关键词就是32GB HBM内存。HBM使用高级封装技术,将处理器和DRAM做在同一个封装内,可以大大降低走线长度,增加走线密度和总线宽度,从而提供远高于传统DDR标准的内存带宽。事实上,目前内存带宽已经成为了阻碍处理器完全发挥峰值计算能力的重要瓶颈,因此HBM内存将会成为处理器性能提升的重要技术。
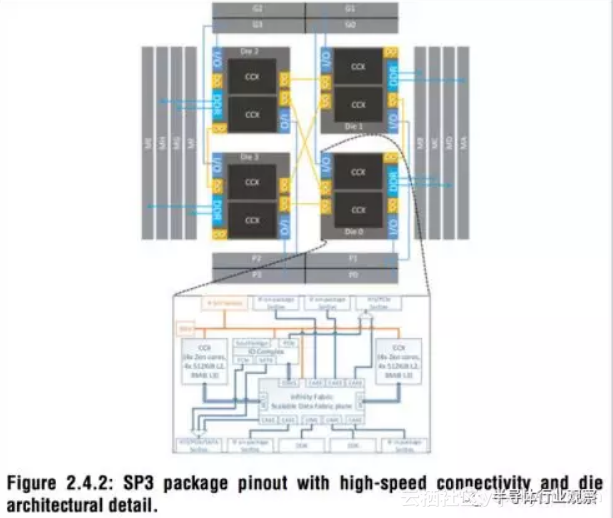
![73ad23cb7df71657a469310b9a45c4ac0ace9ed6]()
AMD在今年ISSCC发布的Zeppelin架构
此外,AMD还宣布将会在7nm VEGA GPU中使用Infinity Fabric。Infinity Fabric与Nvidia的NVLink有相似也有不同的地方,NVLink主要是用于加速多块GPU间的数据通信,而Infinity Fabric则即可以用于片上网络(NoC),也可以用于封装内的互联或者片外互联。除了在VEGA GPU内使用之外,AMD还将在其CPU中搭配Zeppelin架构使用Infinity Fabric。Zeppelin是AMD今年在ISSCC会议上发布的新架构,通过高级封装技术和Infinity Fabric互联技术可以在封装内高效集成多块芯片,从而实现灵活的集成模式,根据需求可以集成多块处理器芯片或者是多块不同的芯片。在高级封装领域,AMD非常重视,在几年前的GPU中用上了HBM内存,而随着Zeppelin架构的发展我们看到AMD正在往封装方向继续深挖潜力。当然,Intel也并不落后,其EMIB高级封装技术也处于领先位置。AMD、Intel和Nvidia在高级封装领域的竞争,我们还将继续关注追踪。
结语
AMD此次在Computex上发布的7nm产品彰显了其进军数据中心应用的决心,而数据中心应用可望能接过PC的大旗成为计算机市场的下一个发展动力。在芯片技术方面,7nm工艺提供的优势主要在于集成度和功耗,对于性能的提升除了特征尺寸缩小之外还得依靠封装技术。
原文发布时间为:2018-06-12
本文作者:李飞
本文来自云栖社区合作伙伴“半导体行业观察”,了解相关信息可以关注“半导体行业观察”。