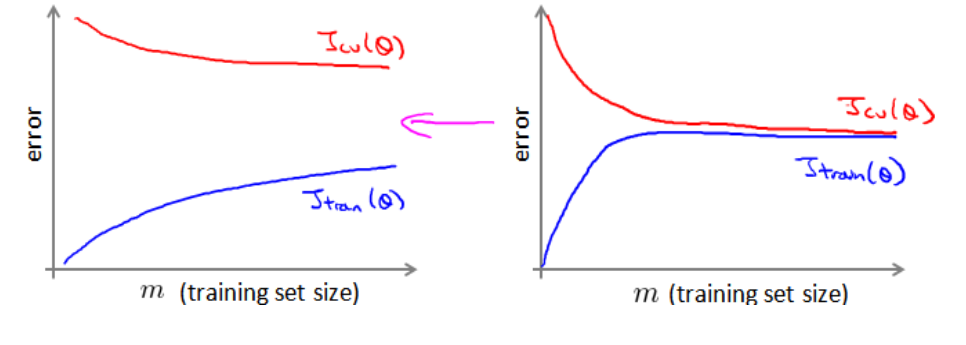
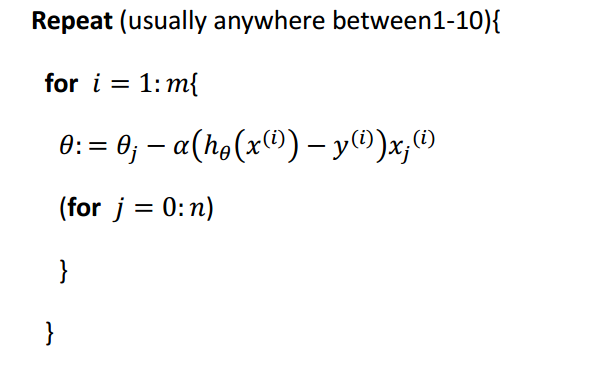
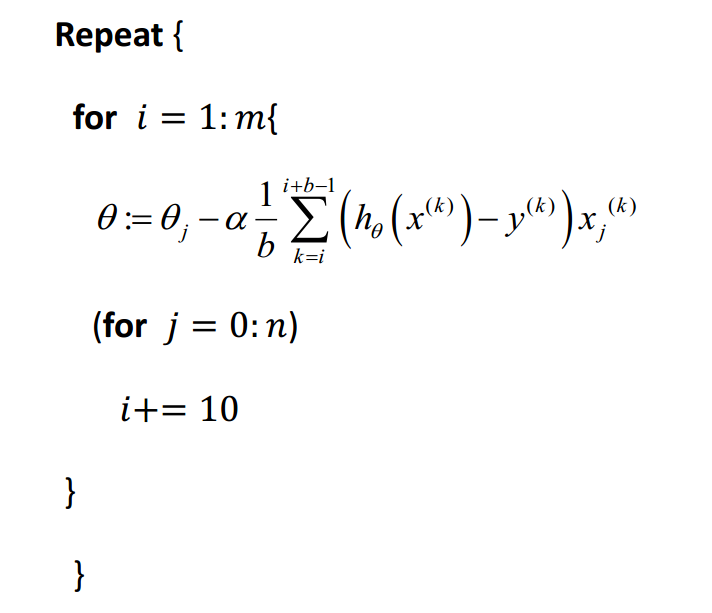
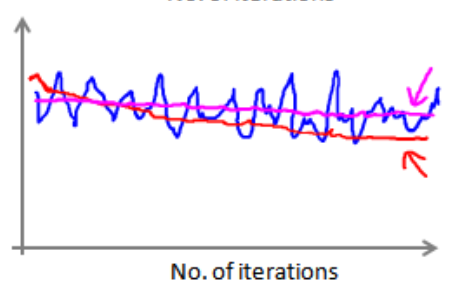


Spark获取当前分区的partitionId
版权声明:本文由董可伦首发于https://dongkelun.com,非商业转载请注明作者及原创出处。商业转载请联系作者本人。 https://blog.csdn.net/dkl12/article/details/80943341 我的原创地址:https://dongkelun.com/2018/06/28/sparkGetPartitionId/ 前言 本文讲解Spark如何获取当前分区的partitionId,这是一位群友提出的问题,其实只要通过TaskContext.get.partitionId(我是在官网上看到的),下面给出一些示例。 1、代码 下面的代码主要测试SparkSession,SparkContext创建的rdd和df是否都支持。 package com.dkl.leanring.partition import org.apache.spark.sql.SparkSession import org.apache.spark.TaskContext /** * 获取当前分区的partitionId */ object GetPartitionIdDemo ...