在当前的版本中,Pod水平自动伸缩支持基于CPU使用情况对Pod进行自动伸缩。Pod水平自动伸缩通过Kubernetes API资源和控制器进行实现。控制器会根据CPU的使用情况周期性的调整Pod的副本数量。
1、水平Pod自动伸缩是如何工作的?
![Horizontal Pod Autoscaler diagram]()
水平Pod自动伸缩被实现为控制周期循环,其周期由控制器管理器的–horizontal-pod-autoscaler-sync-period标志进行控制(默认值为30秒)。在每个周期间,控制器管理器会根据每个HorizontalPodAutoscaler定义中指定的度量标准查询资源利用率。控制器管理器从资源指标的API(针对每个窗格的资源指标)或自定义指标的API(针对所有其他指标)获取度量。
- 对于每个Pod资源指标(如CPU),控制器为HorizontalPodAutoscaler的目标Pod从资源指标API中获取指标。如果设置了目标利用率的值,则控制器将在会计算使用率,作为每个Pod中容器的等效资源请求的百分比。如果设置了目标原始值,则直接使用原始指标标准值。然后,控制器在所有目标Pod中获取利用率的平均值或原始值(取决于指定的目标类型),并产生用于缩放所需副本数量的比率。
需要注意的,如果某些Pod的容器没有设置相关的资源请求,则不会定义Pod的CPU利用率,并且autoscaler不会对该指标标准采取任何操作。
- 对于每个Pod自定义的指标,与每个pod资源指标的工作机理类似;不同之处在于它使用初始值,而不是使用率值。
- 对于对象指标和外部指标,将获取单个指标,该指标将描述相关对象。该指标将与目标值进行比较,以产生如上所述的比率。在
autoscaling/v2beta2API版本中,可以选择在进行比较之前将该值除以pod的数量。
HorizontalPodAutoscaler通常从一系列的API聚集中获取指标(
2、算法
从最基本的角度来看,HorizontalPodAutoscaler控制器根据所需指标与当前指标之间的比率进行操作:
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
例如,如果当前的指标值为200m,而期望的指标值为100m,则Pod的副本数量将会翻倍,即200/100=2;如果当前的指标值为50m,则会将Pod的副本数减半。如果比率足够接近1.0(在全局可配置的容差范围内,从–horizontal-pod-autoscaler-tolerance标志,默认为0.1),将会忽略缩放。当指定targetAverageValue或targetAverageUtilization时,currentMetricValue会通过所有Pod(HorizontalPodAutoscaler伸缩目标)获取给定指标的平均值来计算。当基于CPU进行伸缩时,如果任意Pod还未准备就绪,则此Pod放弃。currentMetricValue / desiredMetricValue伸缩比率基于保留的Pod进行计算,而不是放弃的Pod进行计算。如果在HorizontalPodAutoscaler中指定了多个指标,则会计算每一个指标,并选择期望副本数最大的指标。
3、在kubectl中使用水平Pod自动伸缩
与所有API资源一样,kubectl以标准方式支持水平Pod自动伸缩。可以使用kubectl create命令创建一个新的自动缩放器。通过kubectl get hpa可以列出自动伸缩器,通过kubectl describe hpa能够获得自动伸缩器的详细说明。最后,可以使用kubectl delete hpa删除自动缩放器。此外,还有一个特殊kubectl autoscale命令可以轻松创建HorizontalPodAutoscaler。
1)创建autoscale
$ kubectl autoscale deployment netdisk --min=2 --max=5 --cpu-percent=80
为部署netdisk创建一个自动伸缩器,目标CPU利用率设置为80%,副本数量介于2和5之间。
2)获取autoscale
获取default命名空间下的hpa
$ kubectl get hpa
![]()
3)查看autoscale
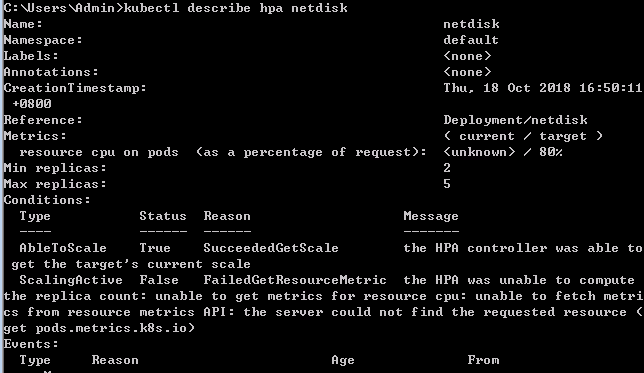
查看netdisk hpa的详细信息。
$ kubectl describe hpa netdisk
![]()
4)删除autoscale
$ kubectl delete hpa netdisk
4、kubectl autoscale命令
kubectl autoscale命令的使用方法
$ autoscale (-f FILENAME | TYPE NAME | TYPE/NAME) [--min=MINPODS] --max=MAXPODS [--cpu-percent=CPU]
字段说明
| 名称 |
Shorthand |
默认值 |
使用说明 |
| allow-missing-template-keys |
|
true |
如果值为真,则忽略模板中的任何错误。仅仅能够应用到golang和jsonpath输出格式。 |
| cpu-percent |
|
-1 |
The target average CPU utilization (represented as a percent of requested CPU) over all the pods. If it’s not specified or negative, a default autoscaling policy will be used. |
| dry-run |
|
false |
If true, only print the object that would be sent, without sending it. |
| filename |
f |
[] |
Filename, directory, or URL to files identifying the resource to autoscale. |
| generator |
|
horizontalpodautoscaler/v1 |
The name of the API generator to use. Currently there is only 1 generator. |
| max |
|
-1 |
The upper limit for the number of pods that can be set by the autoscaler. Required. |
| min |
|
-1 |
The lower limit for the number of pods that can be set by the autoscaler. If it’s not specified or negative, the server will apply a default value. |
| name |
|
|
The name for the newly created object. If not specified, the name of the input resource will be used. |
| output |
o |
|
Output format. One of: json|yaml|name|template|go-template|go-template-file|templatefile|jsonpath|jsonpath-file. |
| record |
|
false |
Record current kubectl command in the resource annotation. If set to false, do not record the command. If set to true, record the command. If not set, default to updating the existing annotation value only if one already exists. |
| recursive |
R |
false |
Process the directory used in -f, –filename recursively. Useful when you want to manage related manifests organized within the same directory. |
| save-config |
|
false |
If true, the configuration of current object will be saved in its annotation. Otherwise, the annotation will be unchanged. This flag is useful when you want to perform kubectl apply on this object in the future. |
| template |
|
|
Template string or path to template file to use when -o=go-template, -o=go-template-file. The template format is golang templates [http://golang.org/pkg/text/template/#pkg-overview]. |
参考材料
1.《Horizontal Pod Autoscaler》地址:https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
本文转自中文社区-kubernetes-水平Pod自动伸缩