![img_18136a158a80284c18344115a1080558.png]()
第一章 基础
1.1 基础编程模型
1.1节的内容主要为介绍Java的基本语法以及书中会用到的库。
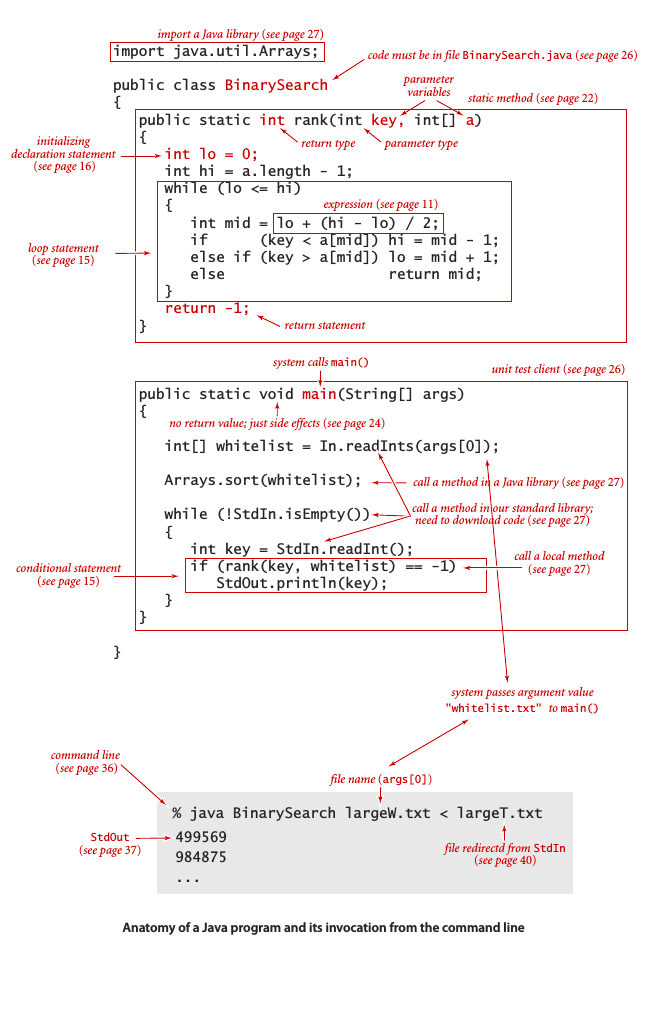
下图为一个Java程序示例和相应的注解:
![img_5dbe5c6b7f2aa00f316eb6d782e41b38.png]()
本书用到的几种基本语法:
- 初始数据类型 (primitive data tyoes):整型 (int),浮点型 (double),布尔型 (boolean),字符型 (char)以及组合起来的表达式。
- 语句 (statements):声明 (declarations),赋值 (assignments),条件 (conditionals),循环 (loops),调用 (calls),返回 (returns)。
- 数组 (arrays)
- 静态方法 (static methods):即函数。
- 字符串 (strings)
- 标准输入/输出 (input/output)
- 数据抽象 (data abstraction)
- Java的
int为32位,double为64位
- 除
int和double以外的其他初始数据类型:
- 64位整数 (long)
- 16位整数 (short)
- 16位字符 (char)
- 8位整数 (byte)
- 32位单精度实数 (float)
- i++和++i的区别:
++i等价于i = i + 1和i += 1,即先+1,再进行运算;而i++是先运算再+1。下面演示一下:
public class i_test
{
public static void main(String[] args)
{
int i = 0;
int j = 0;
System.out.printf("%s: %d%n","++i",++i);
System.out.printf("%s: %d%n","i++",j++);
}
}
/**输出:
++i: 1
i++: 0
*/
数组
1. 创建数组
double[] a;
a = new double[N];
for (int i = 0; i < N; i++)
a[i] = 0.0
double[] a = new double[N];
int[] a = {1,1,2,3,6}
double[][] a = new double[M][N];
2. 别名
数组名表示的是整个数组,如果将一个数组变量赋给另外一个变量,则两个变量将会指向同一个数组:
int[] a = new int[N];
a[i] = 1234;
int[] b = a;
b[i] = 5678 // a[i]也变成5678, 不改变原数组的复制方法见下文
3. 几种数组操作
1)找最大值
double max = a[0];
for (int i = 1;i < a.length; i++)
if (a[i] > max) max = a[i];
2)计算平均值
int N = a.length;
double sum = 0.0;
for (int i = 0; i < N; i++)
sum += a[i];
double average = sum / N;
3)复制数组
int N = a.length;
double[] b = new double[N];
for (int i = 0; i < N; i++)
b[i] = a[i];
4)反转数组中元素
int N = a.length;
for (int i = 0; i < N/2; i++)
{
double temp = a[i];
a[i] = a[N-i-1];
a[N-i-1] = temp;
}
5)矩阵乘法
int N = a.length;
double[][] c = new double[N][N];
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
{// Compute dot product of row i and column j
for (int k = 0; k < N; k++)
c[i][j] += a[i][k]*b[k][j];
}
静态方法
典型的静态方法如下图所示:
![img_ebe54c912ea5a876156571323f39f7da.png]()
1. 几种静态方法实现
1)判断是否为素数
public static boolean isPrime(int N)
{
if (N < 2) return false;
for (int N = 2; i*i <= N; i++)
if (N % i == 0) return false;
return true;
}
2)计算调和级数
public static double H(int N)
{
double sum = 0.0;
for (int i = 1; i < N; i++)
sum += 1.0 / i;
return sum;
}
输入与输出
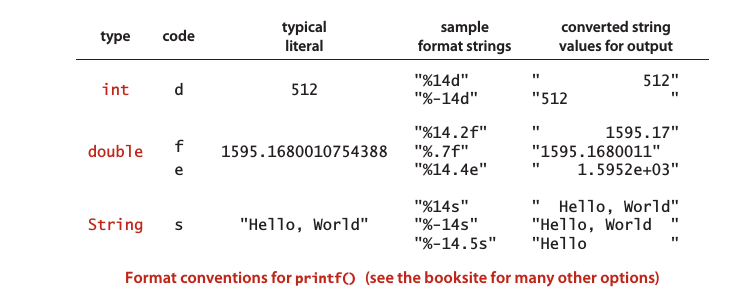
1. 格式化输出:
![img_d78e33c4ee1a801f60836997bc9228b1.png]()
2. 标准输入
![img_76ceb990abdc905a2227ee9ad6be2ad1.png]()
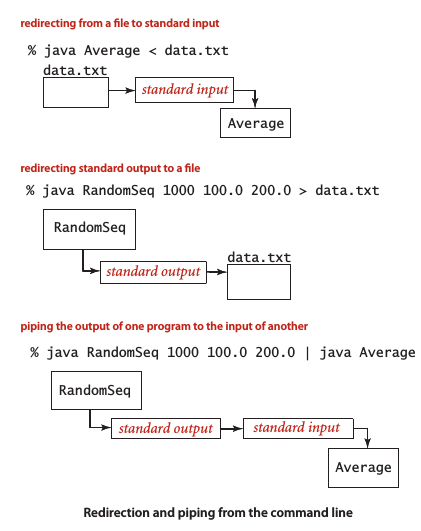
3. 重定向和管道
"<" 表示从文件读取,">"表示写入文件
![img_4b0e9c8a53c317fa8a2c59e614400cbe.png]()
4. 从文件输入输出
![img_9be6a8c56f5093f19e7779fb999aba8a.png]()
1.2 数据抽象
数据类型是指一组值和一组对值的操作的集合,对象是能够存储任意该数据类型的实体,或数据类型的实例。
一个数据类型的例子:
![img_b9b3b7355ee99dd5c8a7eb02ef53ce84.png]()
抽象数据类型和静态方法的相同点:
- 两者的实现均为Java类
- 实例方法可能接受0个或多个指定类型的参数,在括号中以逗号分隔
- 可能返回一个指定类型的值,也可能不会(用void表示)
不同点:
- API中可能会出现名称与类名相同且没有返回值的函数,这些特殊的函数被称为构造函数。在上例中,Counter对象有一个接受一个String参数的构造函数
- 实例方法不需要static关键字,它们不是静态方法,它们的目的是操作该数据类型中的值
- 某些实例方法的存在是为了符合Java的习惯,我们将此类方法称为_继承_方法,如上例的toString方法
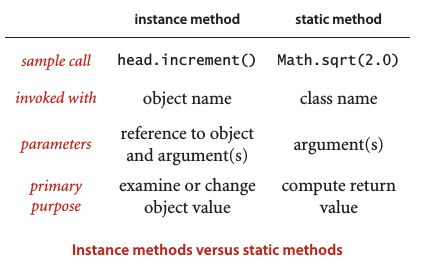
实例方法和静态方法 :
![img_754335d9755ebadec89cc3b1d80c389d.png]()
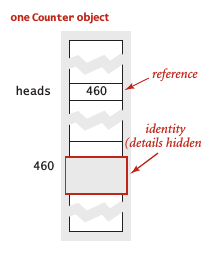
对象
Java中,所有非原始数据类型的值都是对象。对象的三大特性:状态、标识、行为。
引用 (reference) 是访问对象的一种方式,如图所示:
![img_12dc3deed64ddbdfa0fba4ec6c434076.png]()
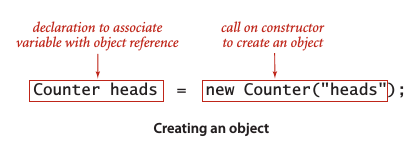
创建对象
要创建 (或实例化) 一个对象,用关键字new并紧跟类名以及 () 来触发它的构造函数。每当用例调用new (),系统都会:1. 为新对象分配内存空间。 2. 调用构造函数初始化对象中的值。 3. 返回该对象的一个引用。
创建一个对象,并通过声明语句将变量与对象的引用关联起来:
![img_32ebd72f0af7d2a852e0461a664a4259.png]()
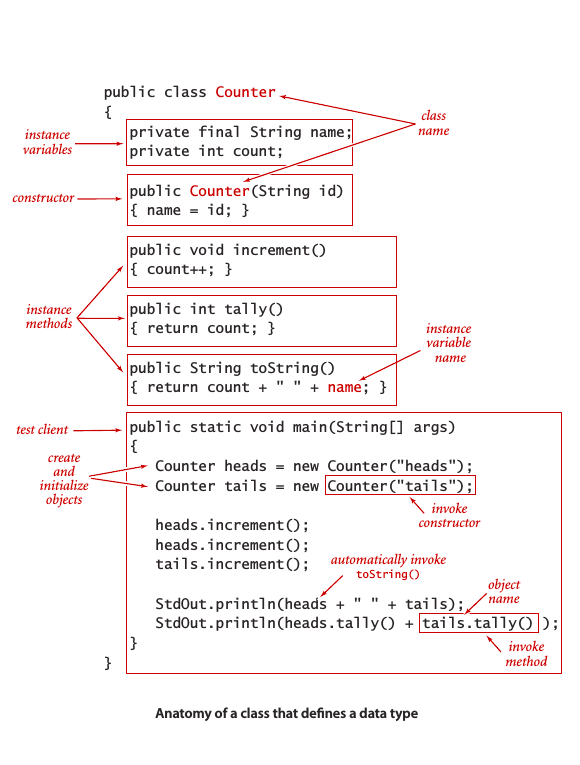
抽象数据类型的实现
组成部分:私有实例变量 (private instance variable),构造函数 (constructor),实例方法 (instance method) 和一个测试用例(client) 。
![img_7ccdb427407f8a20cc41caf7cd19f7fd.png]()
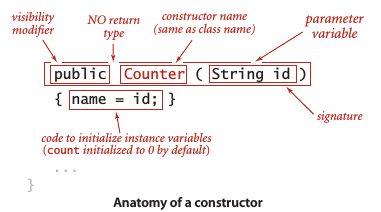
构造函数
![img_513cd58026559d1cb9d0a7dda7cd5933.png]()
每个Java类都至少含有一个构造函数以创建一个对象的标识。一般来说,构造函数的作用是初始化实例变量。如果没有定义构造函数,类将会隐式将所有实例变量初始化为默认值,原始数字类型默认值为0,布尔型为false,引用类型变量为null。
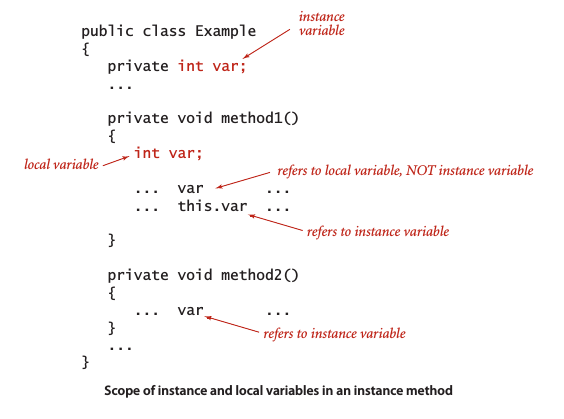
作用域
在方法中调用实例变量,若出现二义性,可使用 this 来区别:
![img_bbf897095fb88bc6e97ce6c97aec1c22.png]()
1.3 背包、队列和栈
![img_ac18790d36388581d9672517d186faa3.png]()
链表 (Linked List)
链表是一种递归的数据结构,它或者为空 (Null),或者是指向一个结点 (Node) 的引用,该结点包含一个泛型元素和一个指向另一条链表的引用。
使用嵌套类定义结点的抽象数据类型:
private class Node
{
Item item;
Node next;
}
一个Node对象包含两个实例变量,类型分别为Item (参数类型) 和Node,通过new Node () 触发构造函数来创建一个Node类型的对象。调用的对象是一个指向Node对象的引用,它的实例变量均被初始化为null。
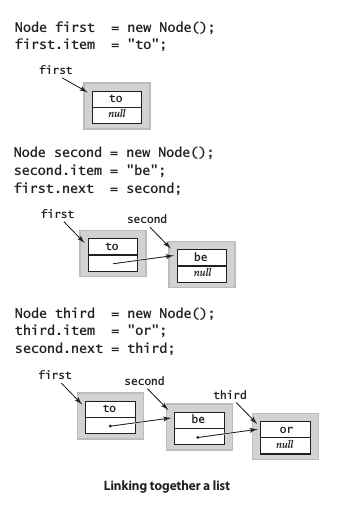
构造链表
构造一条含有元素to、be和or的链表,首先为每个元素创建结点:
Node first = new Node();
Node second = new Node();
Node third = new Node();
将每个结点的item域设为所需的值:
first.item = "to";
second.item = "be";
third.item = "or";
然后用next域构造链表:
first.next = second;
second.next = third;
![img_e13c5e9427c0af3240a6fc65ecb47095.png]()
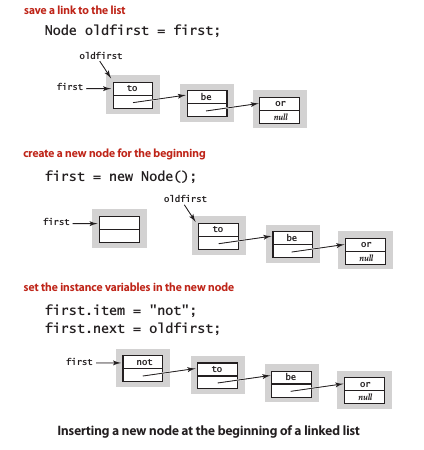
在表头插入结点
![img_9accd4811e4d9c5aef96353a9d9c58c0.png]()
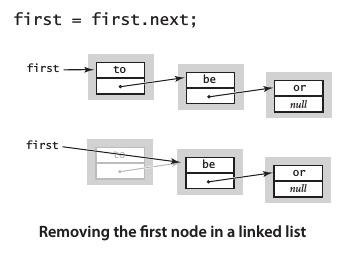
在表头删除节点
将first指向first.next:
![img_d71c2f16a411f5e6c2b034d61c9856b1.png]()
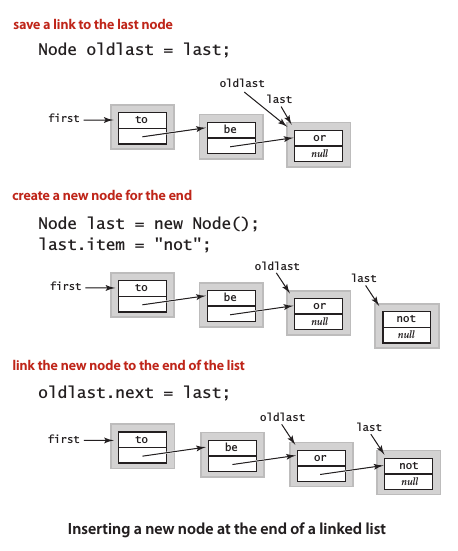
在表尾插入节点
![img_64635168b909f1d3d2ffdeef513265c3.png]()
链表的遍历
一般数组a[] 的遍历:
for (int i = 0; i < N; i++)
{
// Process a[i].
}
链表的遍历:
for (Node x = first; x != null; x = x.next)
{
// Process x.item.
}
栈 (stack)
栈是一种基于后进先出 (LIFO) 策略的集合类型。
栈的链表实现:
public class Stack<Item>
{
private Node first;
private int N;
private class Node
{
Item item;
Node next;
}
public boolean isEmpty() { return first == null; }
public int size() { return N; }
public void push(Item item)
{
Node oldfirst = first;
first = new Node();
first.item = item;
first.next = oldfirst;
N++;
}
public Item pop()
{
Item item = first.item;
first = first.next;
N--;
return item;
}
}
栈测试用例:
public static void main(String[] args)
{ // Create a stack and push/pop strings as directed on StdIn.
Stack<String> s = new Stack<String>();
while (!StdIn.isEmpty())
{
String item = StdIn.readString();
if (!item.equals("-"))
s.push(item);
else if (!s.isEmpty()) StdOut.print(s.pop() + " ");
}
StdOut.println("(" + s.size() + " left on stack)");
}
用链表实现栈的优点:
- 可以处理任意类型的数据
- 所需的空间总与集合的大小成正比
- 操作所需的时间和集合的大小无关
队列 (queues)
队列是一种基于先进先出(FIFO)策略的集合类型。
队列的链表实现:
public class Queue<Item>
{
private Node first;
private Node last;
private int N;
private class Node
{
Item item;
Node next;
}
public boolean isEmpty() { return first == null; }
public int size() { return N; }
public void enqueue(Item item)
{
Node oldlast = last;
last = new Node();
last.item = item;
last.next = null;
if (isEmpty()) first = last;
else oldlast.next = last;
N++;
}
public Item dequeue()
{
Item item = first.item;
first = first.next;
if (isEmpty()) last = null;
N--;
return item;
}
}
队列测试用例:
public static void main(String[] args)
{ // Create a queue and enqueue/dequeue strings.
Queue<String> q = new Queue<String>();
while (!StdIn.isEmpty())
{
String item = StdIn.readString();
if (!item.equals("-"))
q.enqueue(item);
else if (!q.isEmpty()) StdOut.print(q.dequeue() + " ");
}
StdOut.println("(" + q.size() + " left on queue)");
}
背包 (bag)
背包是一种不支持从中删除元素的集合数据类型,它的目的是收集元素并迭代遍历所有收集到的元素。使用背包说明元素的处理顺序不重要。
背包的链表实现 + 迭代
import java.util.Iterator;
public class Bag<Item> implements Iterable<Item>
{
private Node first;
private class Node
{
Item item;
Node next;
}
public void add(Item item)
{
Node oldfirst = first;
first = new Node();
first.item = item;
first.next = oldfirst;
}
public Iterator<Item> iterator()
{ return new ListIterator(); }
private class ListIterator implements Iterator<Item>
{
private Node current = first;
public boolean hasNext()
{ return current != null; }
public void remove() { }
public Item next()
{
Item item = current.item;
current = current.next;
return item;
}
}
}
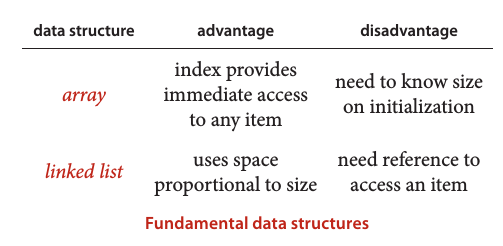
两种基本的数据结构
- 数组,顺序存储 (sequential allocation)
- 链表,链式存储 (linked allocation)
![img_fbe6da95e0d555534fe0a40a46c99bdb.png]()
本书所采取的研究新应用的步骤
- 定义API
- 根据特定的应用场景开发用例代码
- 描述一种数据结构 (一组值的表示),在此基础上定义类的实例变量,该类将实现一种抽象数据类型来满足API中的说明
- 描述一种算法 (实现一组操作的方式),在此基础上实现类的实例方法
- 分析算法的性能特点
![img_239acd95eccb277a946592cd9419ceb3.png]()
1.4 算法分析
计时器 —— Stopwatch实现
基于Java中的currentTimeMillis() 方法,该方法能返回以毫秒计数的当前时间。
![img_7fb8c0130c12225ebdd540c7c002bee3.png]()
常见的增长数量级函数
![img_75ff6770d0b1d20dc9bf80602a67ebf0.png]()
成本模型 (cose model)
本书使用成本模型来评估算法的性质,这个模型定义了算法中的基本操作。例如3-sum问题的成本模型是访问数组元素的次数。
得到运行时间的数学模型,步骤如下:
1. 确定输入模型,定义问题的规模
2. 识别内循环
3. 根据内循环中的操作确定成本模型
4. 对于给定的输入,判断这些操作的执行频率
算法分析的常见函数:
![img_a0ead114ca5444cfef850f7a31cfc6c0.png]()
常见增长数量级:
![25.png]()
原始数据类型的内存:
![img_79101824cf3134f8a47cb1bac4cf9f35.png]()