导读:高德地图作为中国领先的出行领域解决方案提供商,导航是其核心用户场景。路线规划作为导航的前提,是根据起点、终点以及路径策略设置,为用户量身定制出行方案。
起点抓路,作为路线规划的初始必备环节,其准确率对于路线规划质量及用户体验至关重要。本文将介绍高德地图针对起点抓路准确率的提升,尤其是在引入机器学习算法模型方面所进行的一些探索与实践。
什么是起点抓路
首先,我们来简单介绍一下什么是起点抓路。起点抓路是指针对用户发起的路线规划请求,通过获取到的用户定位信息,将其起点位置绑定至实际所在的道路。
从高德地图App可以看到,用户进行路线规划时选择起点的方式有以下三种:
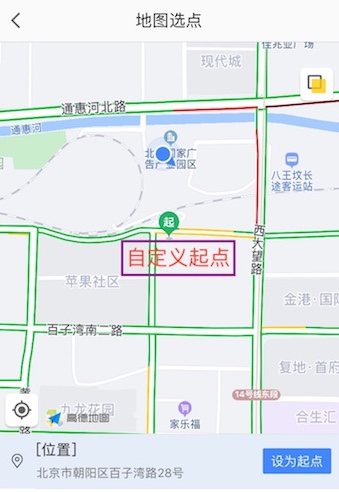
1.手动选点(用户在地图上手动标注所处位置)。
![]()
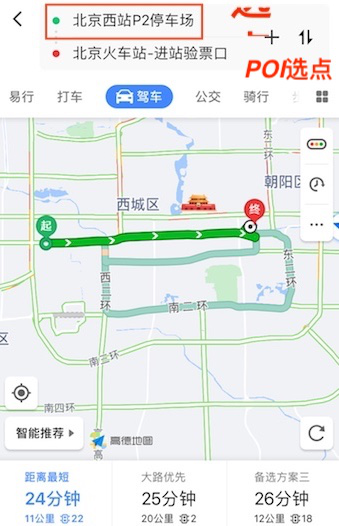
2.POI选点(Point of Interest,兴趣点,在地理信息系统中可以是商铺、小区、公交站等地理位置标注信息)。
![]()
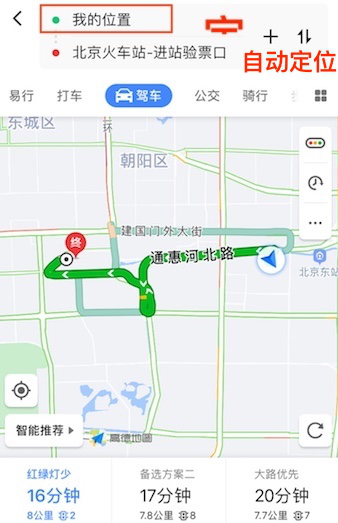
3.自动定位(通过GPS、基站或WiFi等方式自动定位所在位置)。
![]()
三种方式中,用户手动选点及POI选点这两种方式的位置信息相对准确,起点抓路准确率相对较高。
而自动定位起点的方式,由于受GPS、基站、网络定位精度影响,定位坐标易发生漂移,定位设备抓取的位置与用户实际所处道路可能相差几米、几十米甚至几百米。如何在有限信息下,将用户准确定位到真实所在道路,就是我们所要解决的主要问题。
为什么要引入机器学习
引入机器学习之前,起点抓路对候选道路的排序采用了人工规则。核心思路是:以距离为主要特征,结合角度、速度等特征,加权计算得分,进而影响排序,人工规则中所涉及到的权重及阈值等是经综合实战经验人工拍定而成。
随着高德地图业务的不断增长,规划请求数量及场景的增多,人工规则的局限性越来越明显,具体表现在以下方面:
- 即使包含了众多经验在内,人工设定的阈值、权重仍不够完善,易发生偏移或存在盲区是不可改变的事实。
- 策略维护方面,面对上游数据的更新,新特征无法用最快速度加入到策略中。
- 人工规则拍定对经验要求较高,对于人员的更迭,很难做出最敏捷的响应。
在大数据和人工智能时代,利用数据的力量代替部分人力工作,实现流程的自动化,提高工作效率是必然趋势。
因此,基于起点抓路人工规则的现状及问题,我们引入了机器学习模型,自动学习特征与抓路结果之间的关系。一方面,拥有大量规划及实走数据,对于机器学习模型的训练数据获取,高德有天然优势;另一方面,机器学习模型有更强的表达力,能够学习到特征之间的复杂关系,提高抓路准确率。
如何实现机器学习化
回归机器学习本身,下面来介绍我们如何建立起点抓路机器学习模型。一般来讲,运用机器学习方法解决实际问题分为以下几个方面:
- 目标问题的定义
- 数据获取与特征工程
- 模型选择
- 模型训练及效果评估
1.目标问题定义
在引入机器学习模型之前,需要将待解决问题进行数学抽象。
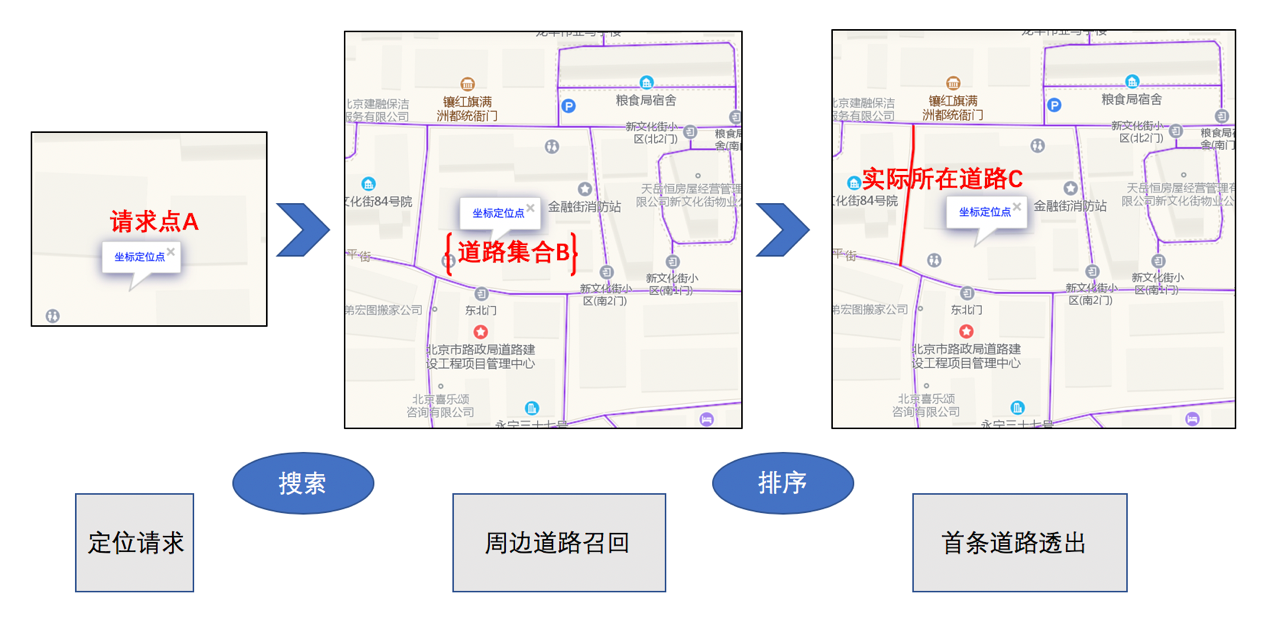
![]()
分析起点抓路问题,如上图所示,我们可以看到当用户在A点发起路线规划请求时,其定位位置A所对应的周边道路是一个独立的集合B,而用户所在的实际道路是这个集合中的唯一一个元素C。
这样,起点抓路问题转化为在定位点周边道路集合中选出一条最有可能是用户实际所在的道路。
整个过程类似搜索排序,因此,我们在制定建模方案时也采用了搜索排序的方式。
- 提取用户路线规划请求中的定位信息A。
- 对定位点周边一定范围内的道路进行召回,组成备选集合B。
- 对备选道路进行排序,最终排在首条的备选道路为模型输出结果,即用户实际所在道路C。
最终,我们将起点抓路定义为一个有监督的搜索排序问题。明确了需要达到的目标,我们开始考虑数据获取及特征工程问题。
2.数据获取与特征工程
业界常言,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限。可见对于项目最终效果,数据和特征至关重要。
训练起点抓路机器学习模型,我们需要从原始数据中获取两类数据:
- 真值数据,即用户发送路线规划请求时实际所处道路信息。
机器学习应用于起点抓路项目,第一个问题就是真值数据的获取。用户在某个位置A发起路线规划请求,由于定位精度限制,我们无法确认其实际所在位置,但如果用户在发起规划请求附近有实走信息,可以将实走信息匹配到路网生成一条运动轨迹,通过这条轨迹我们就可以获取到请求定位点所处的实际道路。
我们针对高德地图的导航请求数据进行相关挖掘,将用户实走与路线规划信息相结合,得到了请求与真值一一映射的数据集。
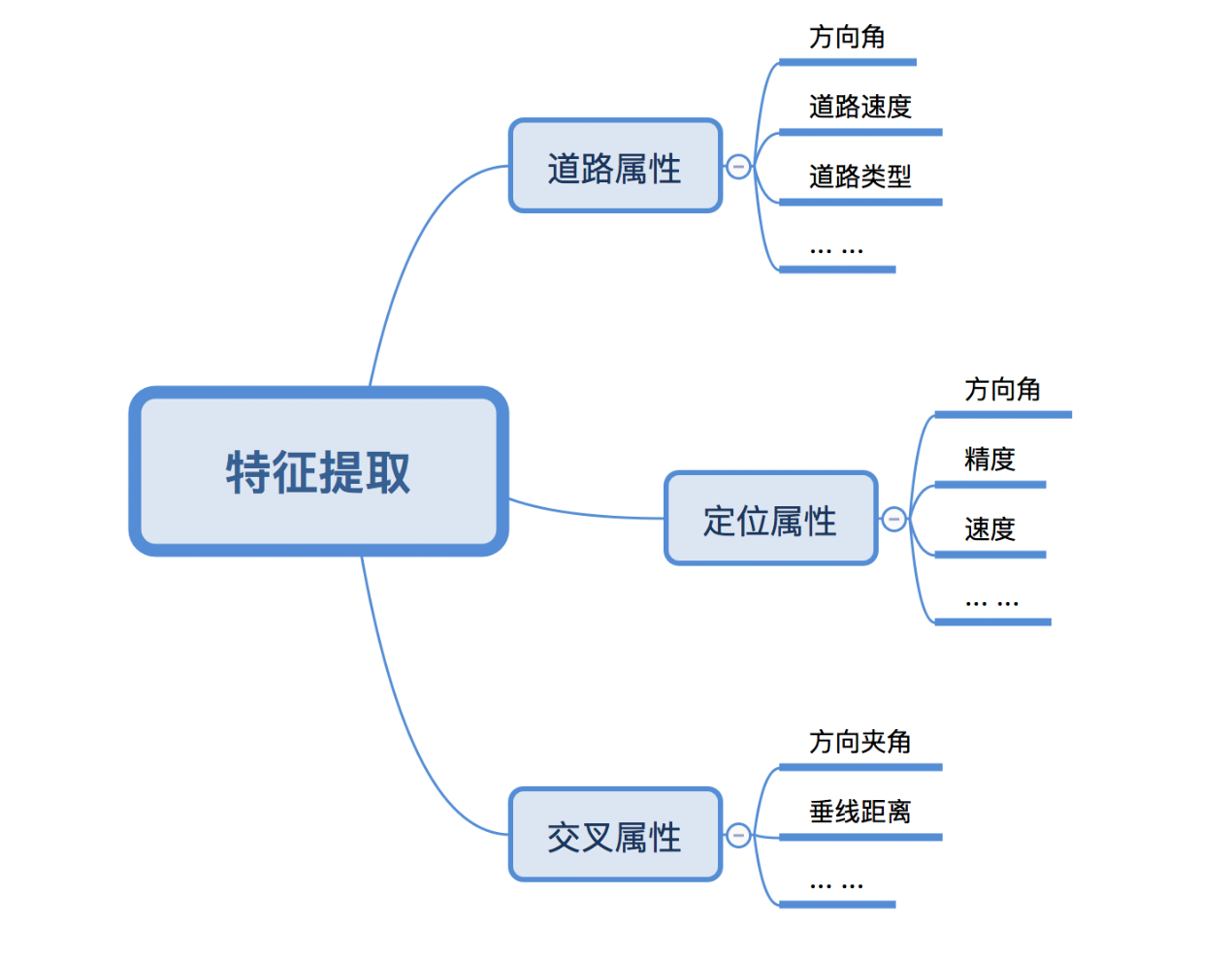
在起点抓路模型中,我们提取了三大类特征用于构建样本集,分别是定位点相关特征、道路自身特征以及定位点与道路之间的组合特征。
![]()
特征处理是特征工程的核心部分,不同项目在进行特征预处理时会有不同,需要根据实际业务场景进行特殊化处理,往往依赖于专业领域经验。起点抓路项目中,我们针对定位特征进行了样本去重、异常值处理、错误值修正及映射等数据清洗工作。
3.模型选择
在目标问题定义中,我们将起点抓路剖析为搜索排序问题,而机器学习的ranking技术,主要包括point-wise、pair-wise、list-wise三大类。
根据起点抓路业务特点,我们采用了list-wise,其learning to rank框架具有以下特征:
- 输入信息是同一路线规划请求对应的所有道路构成的多特征向量(即一个query)。
- 输出信息是对应请求(即同一query)特征向量的打分序列。
- 对于打分函数,我们采用了树模型。
我们选择NDCG(Normalized Discounted Cumulative Gain 归一化累积折算信息增益值)作为模型评价指标,NDCG是一种综合考虑模型排序结果和真实序列之间关系的指标,也是常用的衡量排序结果的指标。
4.模型训练及效果评估
我们抽取了一定时间段内的请求信息,按照步骤2中描述的方式获取到对应真值及特征数据,打标构建了样本集,将其划分为训练集与测试集,训练模型并查看结果是否符合预期。
评估模型效果,我们将测试集的请求分别用人工规则及机器学习模型进行抓路,并分别与真值进行对比,统计准确率。
对比结果,针对随机抽取的请求,模型与人工规则抓路结果差异率为10%,这10%的差异群体中,模型抓路准确率比人工规则提升40%,效果显著。
写在最后
以上我们介绍了大数据和机器学习在起点抓路方面的一些应用,项目的成功上线也验证了机器学习在提升准确率、优化流程等方面可以发挥重要作用。
未来,我们希望能够将现有模型场景继续细化,寻找新的收益点,从数据和模型两个角度共同探索,持续优化机器学习抓路效果。
![]()
关注高德技术,找到更多出行技术领域专业内容