背景
在分布式系统中,请求链路追踪(Trace) 是诊断性能瓶颈、定位故障的核心能力。近期,阿里云函数计算的 Tracing 能力由 2.0 的 Jeager 升级为 OpenTelemetry 标准的 W3C 协议,通过打通 FC 函数计算与可观测链路 OpenTelemetry 版的全链路观测能力,彻底打通了函数执行的全路径观测,这不仅让用户能够清晰、直观地透视函数内部执行细节、上下游依赖关系及整个系统的交互行为,更关键的是打破了传统 Serverless 架构中的"黑盒"困境,清晰界定函数与外部服务(云服务、自建系统等)的业务边界,从而在复杂业务场景下显著提升问题排查效率与根因定位精度。
全链路透明化
- FC系统级span透传:将FC内部组件(如调度器、冷启动模块)的关键生命周期事件以Span形式上报,覆盖函数调用全流程(调度→初始化→执行→释放)。
- 业务Span与系统Span自动拼接:用户自定义业务逻辑(函数代码)的Span与FC系统Span自动拼接,形成端到端Trace视图,暴露潜在性能瓶颈(如冷启动耗时、资源争抢)。
![]()
跨环境互通
- 标准化协议支持 :兼容 traceparent 、tracestate、baggage 等Header,确保FC函数与下游服务(如数据库、消息队列)的上下文无损传递。
- 多环境互通:支持跨函数、跨服务、跨云厂商的Trace上下文透传,无缝集成已有OpenTelemetry生态工具链。
动态成本控制
- 灵活的采样率控制:支持通过函数配置调整采样率(如1%低负载采样,100%故障排查采样),平衡数据量与资源开销。
使用场景
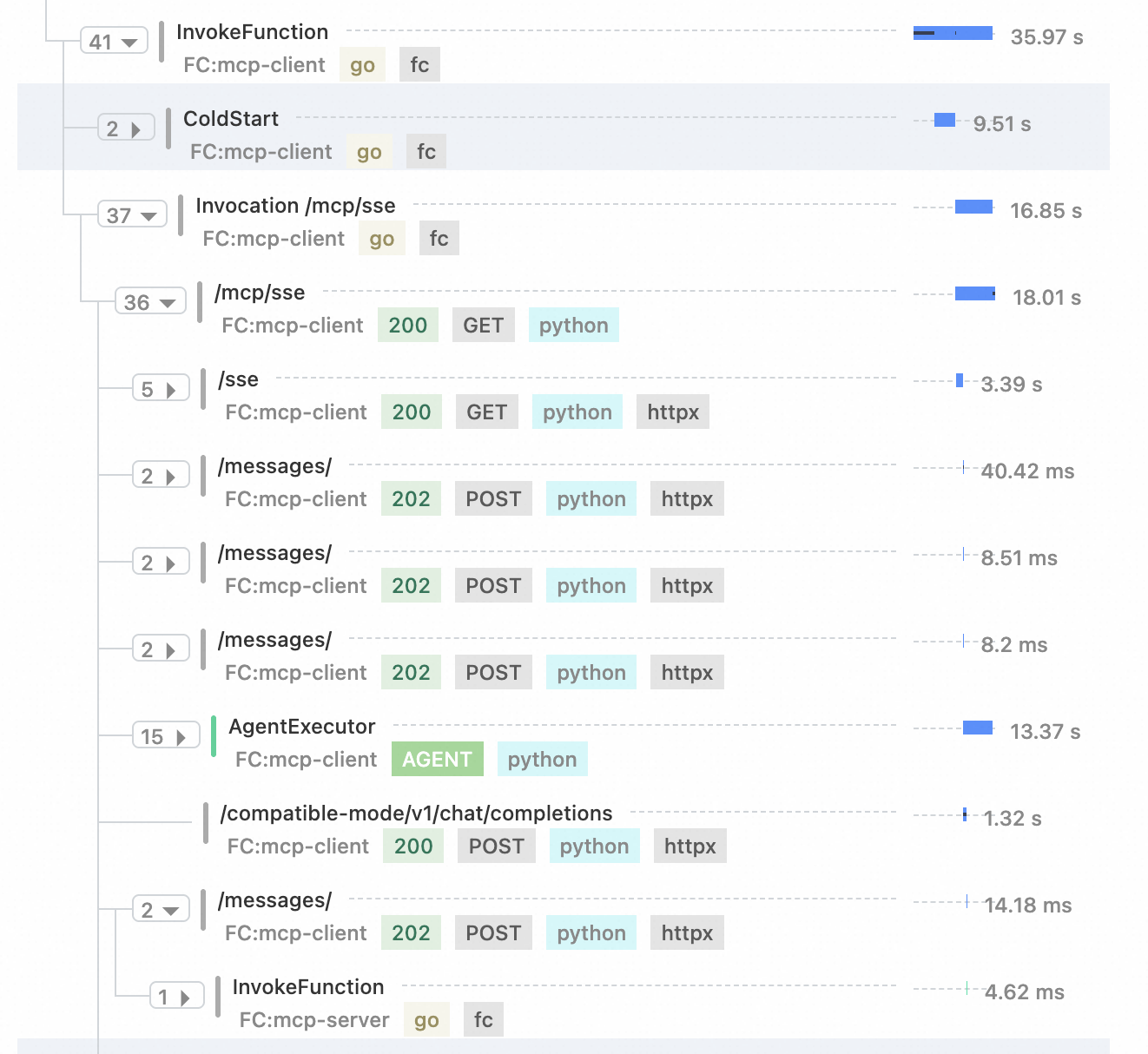
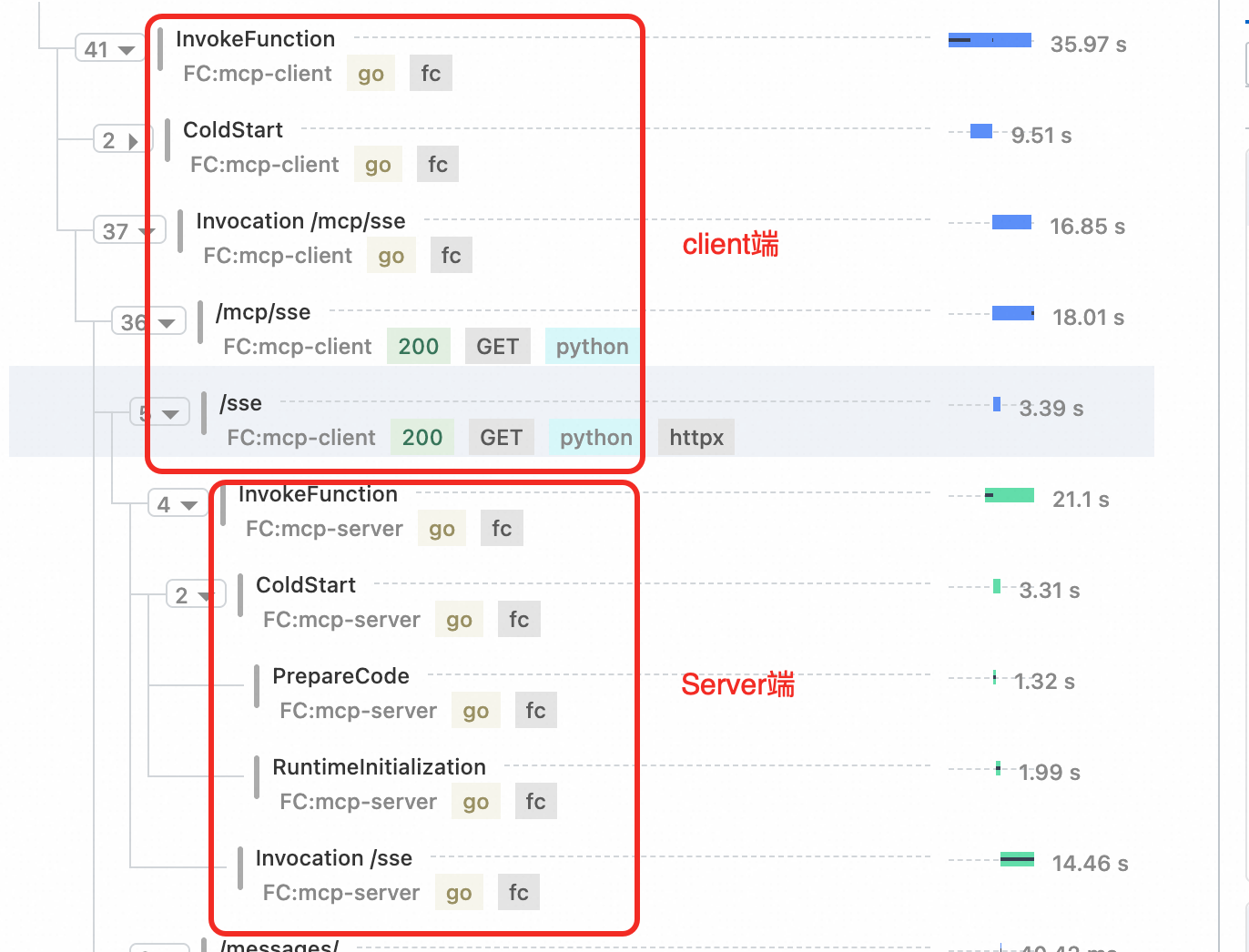
函数计算集成链路追踪后,可以快速定位 Serverless 场景下的性能瓶颈。以一个langchain作为mcp-client端,高德天气查询作为mcp-server端为例。一次查询天气的调用链路如下:可以清晰的看到冷启动信息、sse连接,message连接,以及Agent的调用信息。
![]()
分析冷启动时间,优化代码
开启链路追踪后,开发者可以在FC控制台以及链路追踪控制台查看函数执行情况,请求在函数计算的时间消耗对开发者完全透明可见。
查看冷启动时间,如果 PrepareCode 时间比预期时间长,需要精简代码包;
使用自定义运行时和自定义镜像时,函数执行环境完全由用户自定义,RuntimeInitialization 时间比预期时间长则需要优化启动代码。
![]()
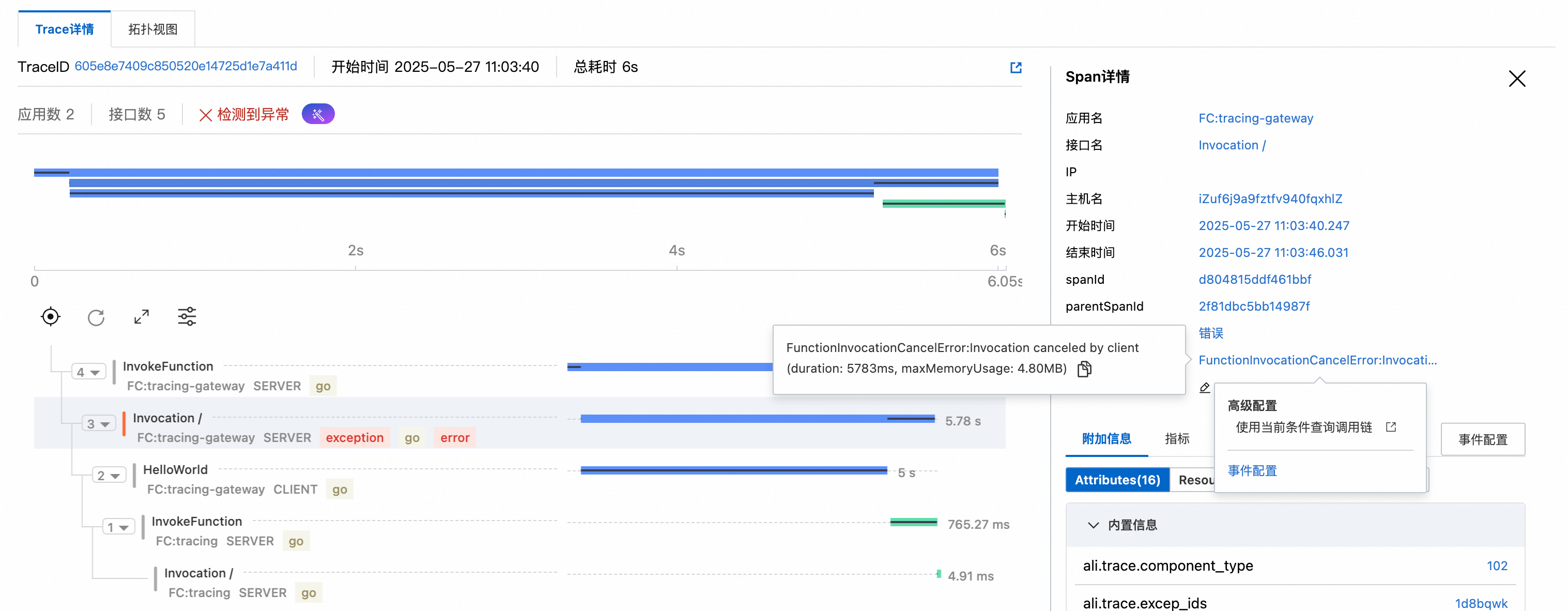
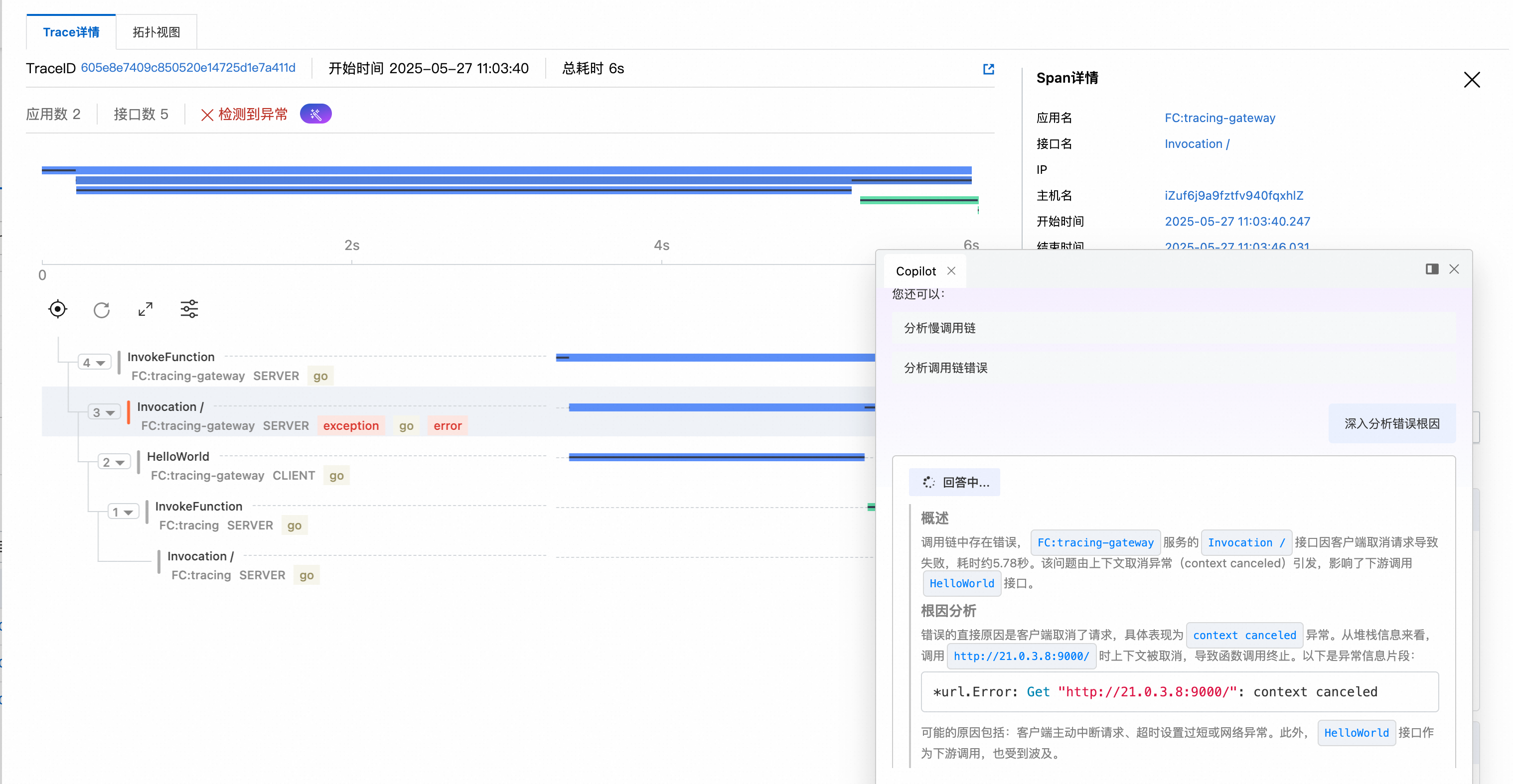
快速定位异常请求根因
当有异常请求时,定位到对应trace可查看异常信息,并利用AI运维助手分析Trace。
![]()
![]()
作为分布式链路的一环,追踪链路
当函数计算作为分布式链路中的一环时,函数计算链路追踪可以串联上下游服务,看到请求在各个步骤的延时。串联mcp-client和mcp-server端。
![]()
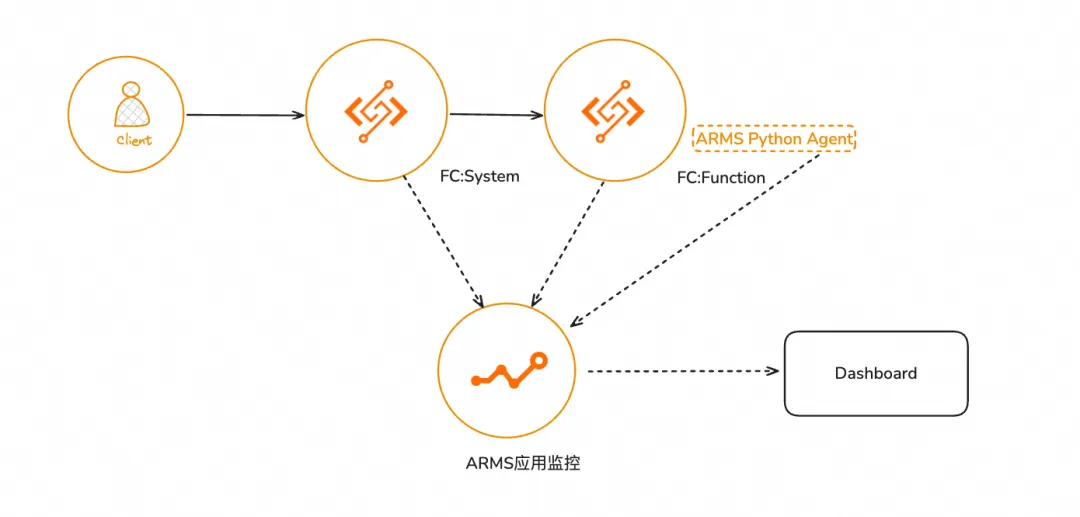
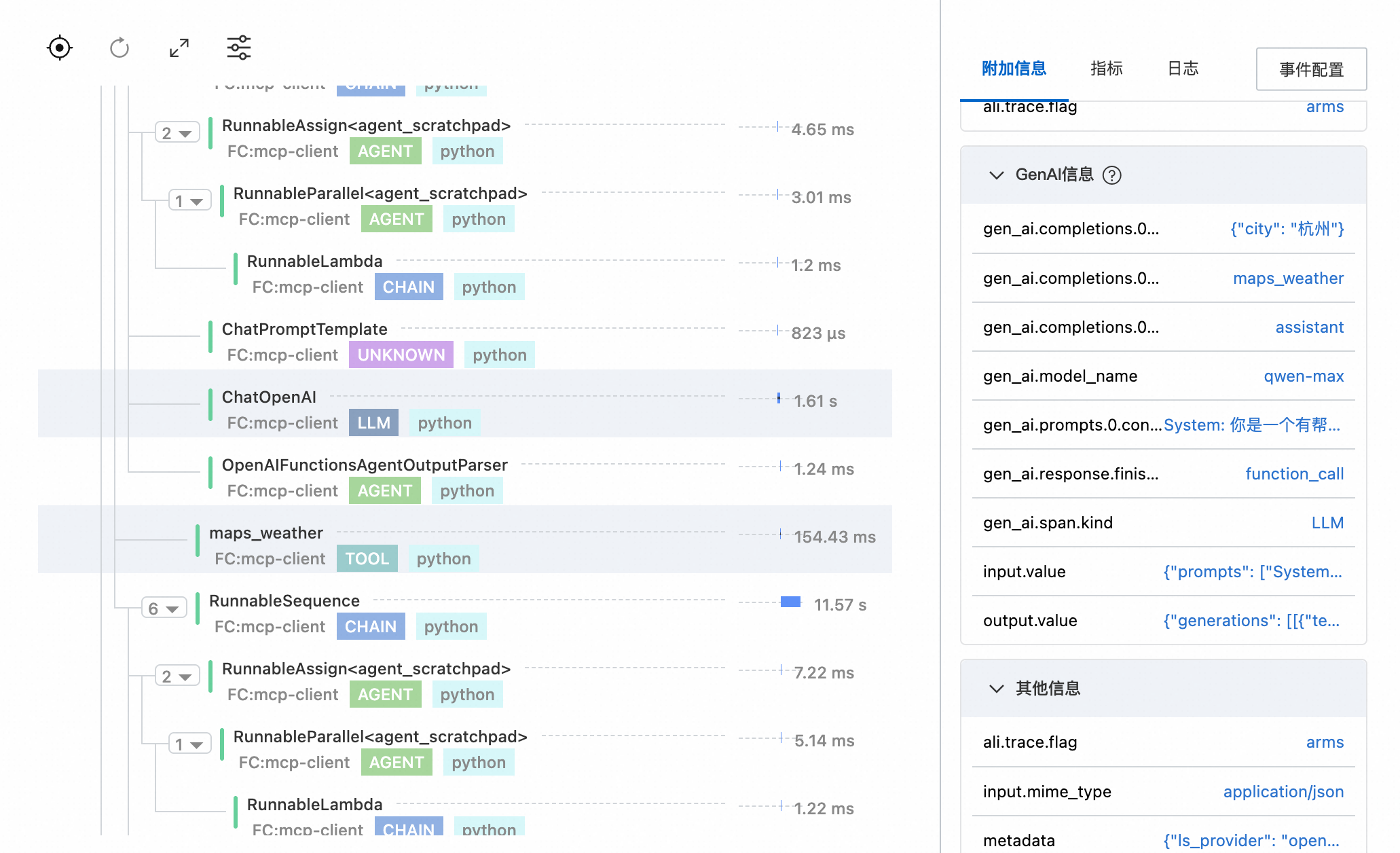
使用Arms Python探针监控LLM应用
为LLM(Large Language Model)应用安装Python探针后,调用链分析功能将会对大模型应用的调用链信息进行分析,您可以在调用链分析页面查看大模型调用链中不同类型的Span耗时、以及Span的关联信息,例如Input、Output、Token消耗等。
![]()
效果对比
| 场景 | 升级前 | 升级后 |
| :--- | :--- | :--- |
| 冷启动耗时分析 | 依赖日志拼凑,无法区分系统/业务耗时 | 可视化Span分段,精准定位瓶颈环节 |
| 跨服务调用追踪 | 上下文断裂,无法关联上下游 | W3C Header透传,完整链路还原 |
总结
通过本次升级,FC 函数计算与 OpenTelemetry 的深度融合实现了全链路透明化,覆盖从系统层到业务层的完整追踪,并基于统一的 W3C 协议标准打破数据孤岛,确保跨环境一致性。同时,动态采样策略的引入有效平衡了性能与成本,为可观测性提供经济高效的解决方案。
未来,我们计划进一步扩展无侵入式监控能力,同时持续丰富可观测诊断工具集,通过智能分析和自动化诊断功能提升故障排查效率,助力用户构建更敏捷、更智能的运维体系。
更多内容关注 Serverless 微信公众号(ID:serverlessdevs),汇集 Serverless 技术最全内容,定期举办 Serverless 活动、直播,用户最佳实践。