作者:汪诚愚(熊兮)、严俊冰(玖烛)、蔡文睿(清素)、岳元浩(顾城)、黄俊(临在)
前言
随着大型语言模型(LLM)的复杂性和规模不断增长,对于许多研究人员和企业而言,如何有效地利用这些庞大的模型变得愈发重要。然而,巨大的计算需求和训练成本为模型的广泛应用设置了障碍。知识蒸馏是一种将大模型的知识转移到小模型的方法,其核心思想是在不显著降低性能的前提下,通过训练将复杂的模型转化为更小、更高效的版本。通过这种方式,知识蒸馏不仅能够有效降低计算成本,还能够提高模型在资源受限环境中的适应性,从而为大规模应用提供可能。在此背景下,阿里云人工智能平台(PAI)推出了一款新的开源工具包——EasyDistill(https://github.com/modelscope/easydistill),旨在简化大型语言模型的知识蒸馏过程,助力参数量更小但性能卓越的大模型的实际应用。除了 EasyDistill 本身,这一框架还包括了蒸馏大模型 DistilQwen 系列以及相应的开源数据集,供用户使用,其中包括一百万条通用指令遵循数据和两百万条思维链推理数据。尤其是, DistilQwen 系列最新的变长思维链推理蒸馏模型 DistilQwen-ThoughtX 能够根据任务难度输出变长思维链,其32B版本推理能力超越了 DeepSeek 官方蒸馏模型。
在下文中,我们详细描述 EasyDistill 的框架功能,包括对应的 DistilQwen 模型以及其对应开源数据集。
1. EasyDistill框架功能
在本节中,我们将深入讨论 EasyDistill 的功能模块及其在知识蒸馏中的各类应用细节。
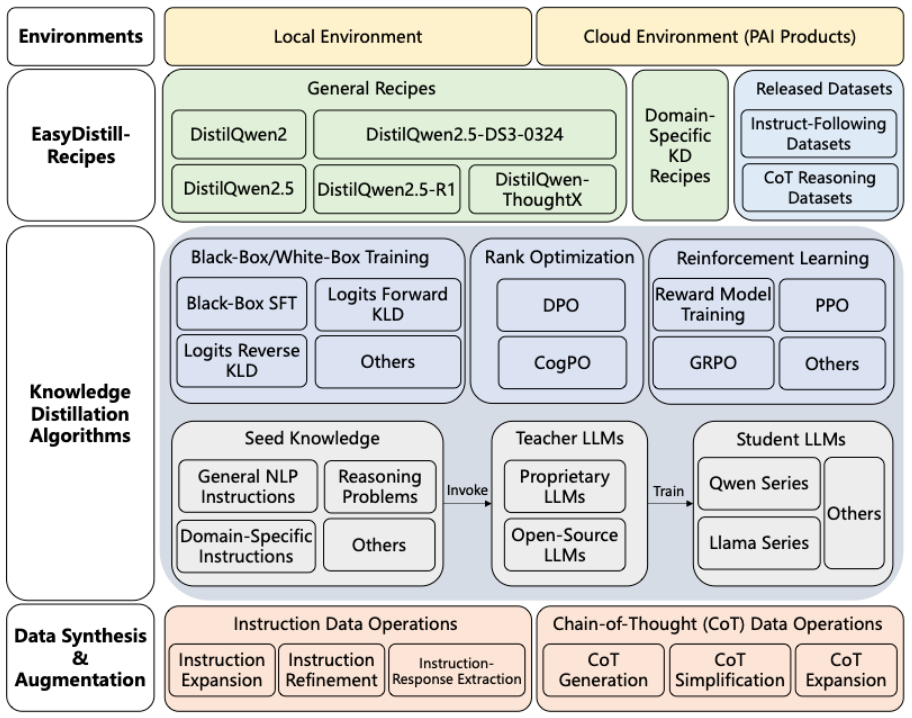
1.1 基本架构和功能简介
EasyDistill 的基础架构如下图所示:
![]()
1.2 数据合成
在训练大语言模型过程中,合成数据起着至关重要的作用。尤其在知识蒸馏阶段,种子数据集的规模通常有限,使合成数据的使用显得尤为必要。我们在 EasyDistill 框架中集成了多种数据合成和增强操作,这些操作利用了专有和开源的教师模型,使训练集不仅在数量上增加,还在任务、主题或领域的多样性方面得到了提升。
EasyDistill 支持的第一组操作专注于合成各种 NLP 任务的指令数据。框架引入了多项功能,包括指令扩展、指令优化,以及从原始文本中自动生成指令-响应对等。具体而言,指令扩展通过增加指令数据集的数量,使模型能够获取更加丰富的上下文信息,从而提升训练集的知识覆盖率;指令优化则涉及去除冗余信息并提高指令的明确性,确保模型回复质量更高;自动生成指令-响应对的功能使得模型能够从非结构化文本中提取知识,为训练数据集注入更多的多样性。
EasyDistill 框架的第二组操作专注于思维链,这是蒸馏大规模推理模型的重要组成部分。除生成思维链的算子外,我们进一步整合了用于简化和扩展思维链的算子。思维链简化算子通过减少模型推理的复杂性,使思维链更加清晰和连贯,提升模型在推理过程中的效率。思维链扩展算子则能够在复杂问题上提供更多详细步骤和逻辑链,从而增强模型解决复杂问题的能力。
1.3 基础蒸馏训练
在基础蒸馏训练模块中,EasyDistill 提供了黑盒化和白盒化的模型蒸馏训练功能。对于专有的闭源大语言模型,由于只能访问模型的输出,其黑盒化知识蒸馏主要依赖于监督微调(SFT),将这些输出视为学生模型的真实值进行训练。这种方法操作简单,但在数据有限的情况下,其效果可能受到限制。值得注意的是,EasyDistill 框架支持所有符合 OpenAI 格式的闭源模型 API,例如 OpenAI、DashScope、PAI-EAS 等。
针对开源的教师语言模型,EasyDistill 训练层提供了一种更为精细的白盒化训练策略。除了进行 SFT 之外,我们还利用教师模型的隐藏知识进行指导。这种方式能够显著提升效果。具体而言,我们从教师模型获取 token 级别的 logits,通过最小化教师模型与学生模型 logits 分布之间的差异来优化训练表现。为此,EasyDistill 框架采用了包括 Kullback–Leibler 散度(KLD)和反向 KLD 在内的多种损失函数。根据我们的研究,模型的前10个概率最大的 token 的概率之和几乎为1。因此,EasyDistill 允许用户选择仅使用教师模型中前 top-k 的 token logits,并与学生模型的对应 logits 进行匹配。随后,在计算损失函数时,我们仅考虑这k个选定的 logits 进行近似计算。这种策略不仅降低了计算时间,而且加快了 logits 的存储和读取速度。
1.4 进阶蒸馏训练
上述黑盒化和白盒化模型蒸馏训练的核心原则在于让学生模型模仿教师模型的行为。然而,这种方法可能导致学生模型"过拟合"教师模型的输出,从而限制其泛化能力的提升。为解决这一问题,EasyDistill 框架在训练层引入了基于强化学习(RL)和偏好优化的方法,通过教师模型的反馈来训练学生模型。
在强化学习中,决定模型优化上限的一个核心因素是高质量的奖励模型(Reward Model)。EasyDistill 支持的首项功能是利用教师模型的反馈来训练奖励模型,这类似于从AI反馈中进行强化学习(RLAIF)框架。具体而言,我们使用教师模型生成的选择和拒绝回复作为偏好数据,并利用这些数据训练奖励模型。一旦奖励模型建立,便可通过各种强化学习算法优化学生模型。为此,EasyDistill 集成了多种流行算法用于训练学生模型,特别是对通用大语言模型的近端策略优化(Proximal Policy Optimization,PPO)和用于优化推理模型的群体相对策略优化(Group Relative Policy Optimization,GRPO)。
然而,RL 算法的一个潜在缺点是训练过程中的不稳定性。为此,EasyDistill 还引入了偏好优化的方法,将偏好直接融入大模型中以实现更稳定的训练过程。在这一框架下,我们集成了直接偏好优化(Direct Preference Optimization,DPO)算法,直接利用选择和拒绝的回复作为偏好数据来优化学生模型。对于推理模型,蒸馏后的小模型一般具有与大模型不同的认知能力。为此,EasyDistill 引入了我们提出的认知偏好优化(CogPO)算法,通过与模型的认知能力对齐,进一步增强小模型的推理能力。
2. 初步体验 EasyDistill
为了适应不同的使用需求,EasyDistill 采用了模块化设计。用户可以依据具体的任务场景选择适合的模块进行组合和应用。我们也提供了简洁的命令行接口使得用户能够方便地运行各种知识蒸馏算法。以下是使用 EasyDistill 的一些基本步骤。
2.1 克隆代码库:
git clone https://github.com/modelscope/easydistill
cd EasyDistill
2.2 安装必要的依赖:
python setup.py install
2.3 通过命令行界面探索 EasyDistill 的使用:
easydistill --config <config-file-path>
配置文件可为不同的知识蒸馏任务设定具体的参数和路径,如下提供了一个黑盒化蒸馏训练的配置示例:
{
"job_type": "kd_black_box_local",
"dataset": {
"instruction_path": "train.json",
"labeled_path": "train_labeled.json",
"template" : "chat_template/chat_template_kd.jinja",
"seed": 42
},
"inference":{
"enable_chunked_prefill": true,
"seed": 777,
"gpu_memory_utilization": 0.9,
"temperature": 0.8,
"trust_remote_code": true,
"enforce_eager": false,
"max_model_len": 4096,
"max_new_tokens": 512
},
"models": {
"teacher": "teacher/Qwen/Qwen2.5-7B-Instruct/",
"student": "student/Qwen/Qwen2.5-0.5B-Instruct/"
},
"training": {
"output_dir": "./result/",
"num_train_epochs": 3,
"per_device_train_batch_size": 1,
"gradient_accumulation_steps": 8,
"max_length":512,
"save_steps": 1000,
"logging_steps": 1,
"learning_rate": 2e-5,
"weight_decay": 0.05,
"warmup_ratio": 0.1,
"lr_scheduler_type": "cosine"
}
}
教师模型也可以使用闭源的 API 进行配置,示例如下:
{
"job_type": "kd_black_box_api",
"dataset": {
"instruction_path": "train.json",
"labeled_path": "train_labeled.json",
"template" : "./chat_template/chat_template_kd.jinja",
"seed": 42
},
"inference":{
"base_url": "ENDPOINT",
"api_key": "TOKEN",
"stream": true,
"system_prompt" : "You are a helpful assistant.",
"max_new_tokens": 512
},
"models": {
"student": "student/Qwen/Qwen2.5-0.5B-Instruct/"
},
"training": {
"output_dir": "./result/",
"num_train_epochs": 3,
"per_device_train_batch_size": 1,
"gradient_accumulation_steps": 8,
"max_length":512,
"save_steps": 1000,
"logging_steps": 1,
"learning_rate": 2e-5,
"weight_decay": 0.05,
"warmup_ratio": 0.1,
"lr_scheduler_type": "cosine"
}
}
用户只需要指定大模型对应的 base_url 和 api_key 即可,无需配置其他教师大模型的信息。
3. DistilQwen:基于 EasyDistill 的蒸馏开源模型家族
在 EasyDistill 的支持下,我们开发了一系列基于通义千问开源框架的蒸馏语言模型,称为 DistilQwen。这些模型充分利用知识蒸馏的方法,能够在减少模型参数量的同时保持高性能表现。这些蒸馏模型特别适用于资源受限的环境。同时,我们在 EasyDistill 框架的 Recipes 模块中提供了这些蒸馏算法的使用指引。
3.1 DistilQwen 之 System 1 模型
在大语言模型框架中,System 1 模型使用直觉型的任务解决机制来回答用户的指令。由于这些模型的输出 token量较少,其推理速度更快。在 DistilQwen 系列中,我们开源了 DistilQwen2 和 DistilQwen2.5 两个模型系列。其中,DistilQwen2 是 Qwen2 模型的增强版本,具备改进的指令跟随能力,以适应各种自然语言处理任务。我们使用 GPT-4 和 Qwen-max 作为教师模型来生成高质量的回复,同时平衡输入指令的任务分布。在蒸馏训练过程中,我们首先采用 SFT 训练,之后通过 DPO 算法进行偏好优化,以增强学生模型与教师模型之间的对齐。
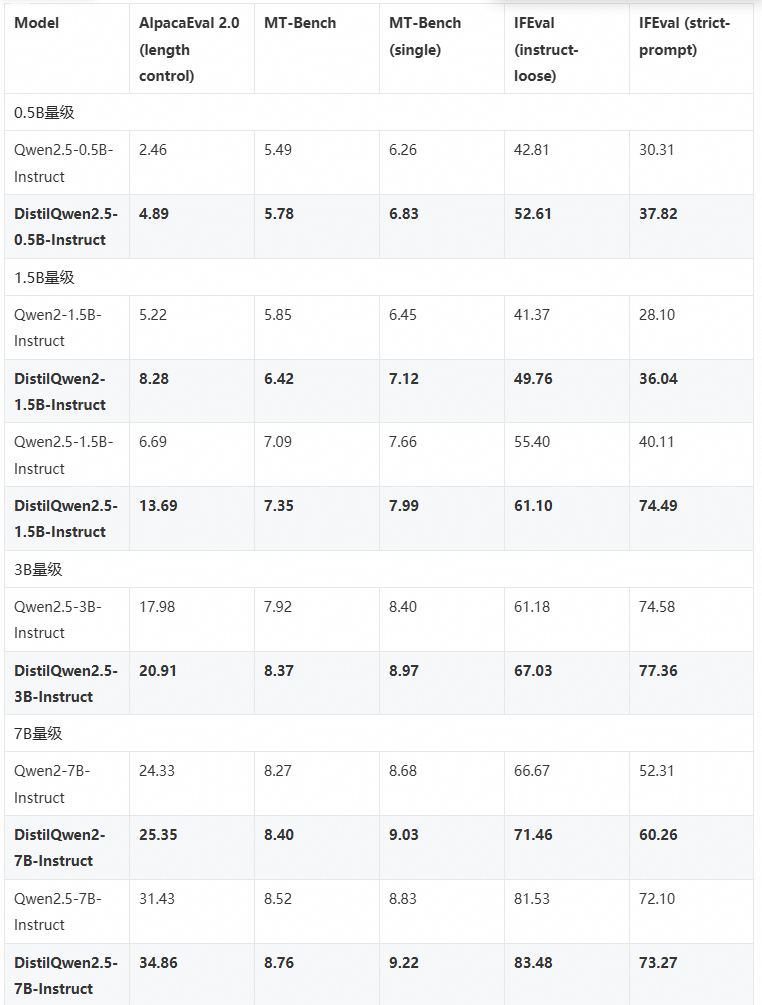
DistilQwen2.5 系列模型是 DistilQwen2 的升级版本,以 Qwen2.5 模型作为底座,使用黑盒和白盒知识蒸馏算法的结合进行训练。我们首先使用与 DistilQwen2 相同的指令数据处理和黑盒 SFT 训练过程。随后,我们进一步采用白盒化的 logitis 优化对齐训练,以完善学生对教师模型中复杂知识的获取。这里,我们使用 Qwen2.5-72B-Instruct 作为开源教师模型。下表展示了 DistilQwen2 和 DistilQwen2.5 与原始模型性能表现的对比。
![]()
3.2 DistilQwen 之 System 2 模型
与 System 1 模型不同,System 2 模型使用慢思考模式,对复杂问题的解决首先输出思维链,其次给出问题的解答,从而显著提升了模型的深度推理能力,在 DistilQwen 系列中,我们首先推出 DistilQwen2.5-R1 系列模型,使用 DeepSeek-R1 作为教师模型。为了使更小的蒸馏模型在推理能力上与其内在的认知能力相匹配,我们进一步使用提出的 CogPO 算法对思维链进行精细化处理。
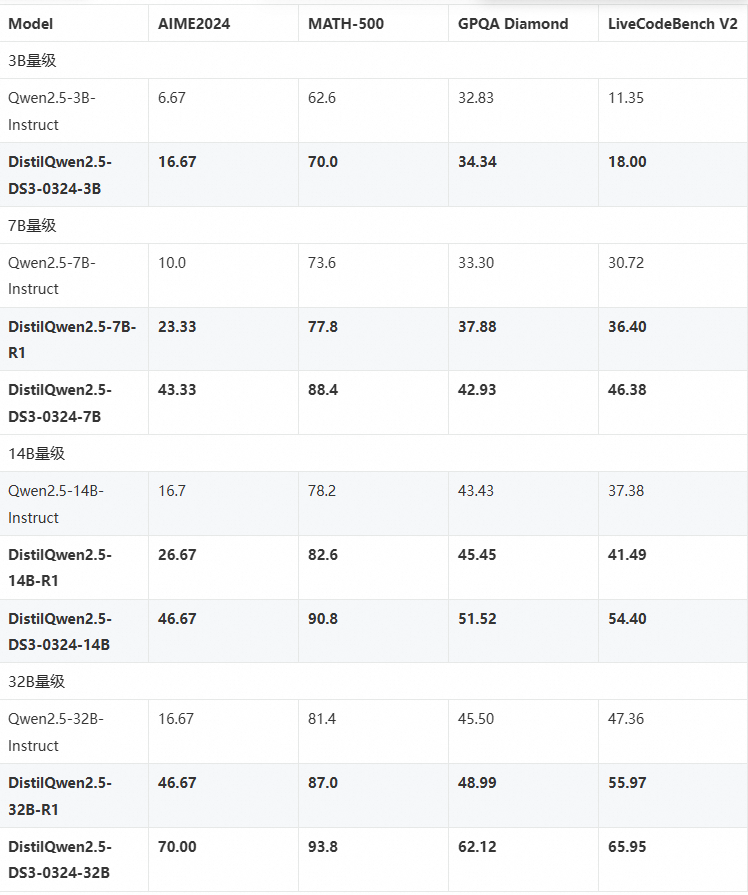
此外,我们将 DeepSeek-V3-0324 的快思维推理能力转移到 DistilQwen2.5-DS3-0324 模型中。为了缩短推理过程,我们使用 CoT 简化算子来减少 DistilQwen2.5-R1 训练数据中的token。结合重写的 CoT 数据集,以及DeepSeek-V3-0324 的 CoT 蒸馏数据,我们训练了 DistilQwen2.5-DS3-0324 系列模型。下图展示了 DistilQwen2.5-R1 和 DistilQwen2.5-DS3-0324 的性能表现。
![]()
3.3 DistilQwen 最新发布:变长思维链推理模型 DistilQwen-ThoughtX
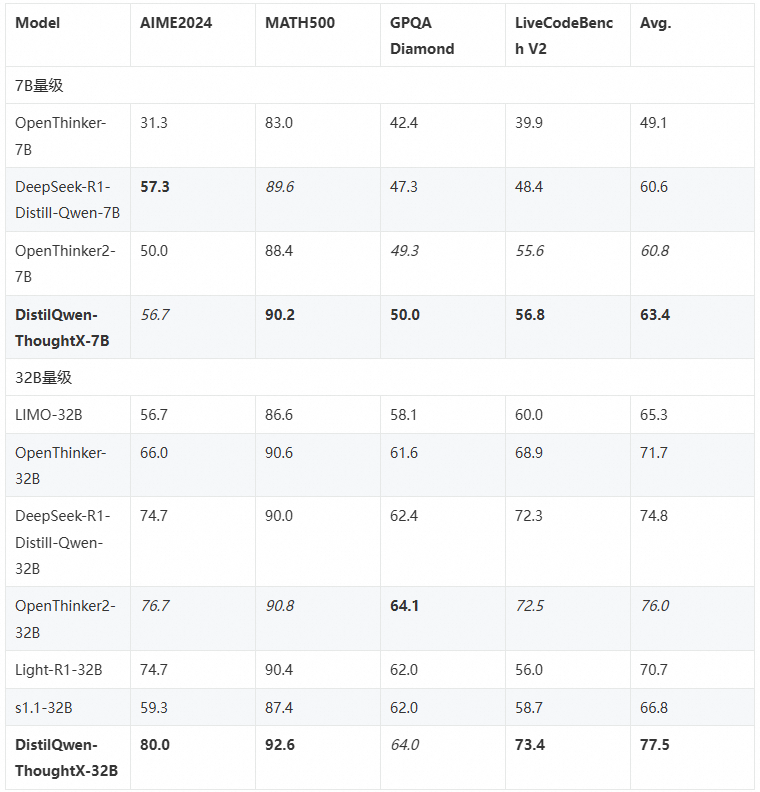
深度推理模型的一个问题是,他们对于各种输入问题都输出较长的思维链进行推理;然而,不适合的思维链可能反而使得模型推理能力下降。因此,提升模型推理能力的关键是模型根据问题难度和自身能力,实现自适应的变长思维链推理。最新的 DistilQwen 系列是 DistilQwen-ThoughtX,与之前的 DistilQwen 模型以及其他开源蒸馏模型相比,它具有更强的推理能力,并可以生成了长度更为优化的推理链。这一模型系列的训练集为我们推出的具有两百万条思维链的 OmniThought 开源数据集,我们对于每条思维链数据都进行推理冗余度(Reasoning Verbosity,RV)和认知难度(Cognitive Difficulty,CD)评分,确保模型获得高质量的思维链训练数据。DistilQwen-ThoughtX 在开源社区中表现甚至优于 DeepSeek 官方采用闭源数据集蒸馏的模型。下表展示了 DistilQwen-ThoughtX 的性能表现:
![]()
DistilQwen 所有模型均可以 HuggingFace 和 ModelScope 开源社区中进行下载。
4. 开源数据集
本章介绍基于 EasyDistill 框架的开源数据集,这些数据集集用于训练 DistilQwen 系列模型,分为两个系列:指令遵循系列和思维链推理系列。
4.1 指令遵循数据集
社区开发者在微调 DistilQwen 模型时,容易发生灾难性遗忘的现象。为了缓解这一问题,我们开源了用于训练 DistilQwen2 和 DistilQwen2.5 系列模型的两个子集:DistilQwen_100K 和 DistilQwen_1M。这些数据集也可以用于提升其他类似大型语言模型在指令遵循方面的能力。这些数据集涵盖了数学、代码、基于知识的问答以及创造性生成等内容,总数据集规模分别为10万和100万。用户可以在模型微调过程中将 DistilQwen_100K 和 DistilQwen_1M 或其子集与自己的数据结合使用,以提升模型在下游任务的效果。
4.2 思维链推理数据集
OmniThought 是用于训练 DistilQwen-ThoughtX 的大规模思维链推理数据集。我们从开源社区搜集大量推理问题以及对应的思维链,并且使用 DeepSeek-R1 和 QwQ-32B 生成更多的思维链,对于每条思维链,我们也使用上述模型验证其正确性,总共获得了200万条思维链。对于 OmniThought 的每一个思维链,我们都给出提出的推理冗余度(RV)和认知难度(CD)评分,这些评分描述了 CoT 冗长程度和模型对于上述思维链的认知难度等级。因此,在蒸馏推理小模型时,可以根据上述评分筛选出更优的思维链子集进行训练。在前文中,我们也展示了,训练出的 DistilQwen-ThoughtX 的表现甚至优于 DeepSeek 官方采用闭源数据集蒸馏的模型。
所有这些数据集都可以在 HuggingFace 和 ModelScope 上公开下载,汇总如下表。
| 数据集 |
类别 |
数据量 |
下载链接 |
| DistilQwen_100K |
指令遵循 |
10万 |
下载链接 |
| DistilQwen_1M |
指令遵循 |
100万 |
下载链接 |
| OmniThought |
思维链推理 |
200万 |
下载链接 |
5. 本文小结
本文介绍了阿里云人工智能平台PAI推出的开源工具包 EasyDistill。随着大语言模型的复杂性和规模增长,它们面临计算需求和训练成本的障碍。知识蒸馏旨在不显著降低性能的前提下,将大模型转化为更小、更高效的版本以降低训练和推理成本。EasyDistill 框架简化了知识蒸馏过程,其具备多种功能模块,包括数据合成、基础和进阶蒸馏训练。通过数据合成,丰富训练集的多样性;基础和进阶蒸馏训练则涵盖黑盒和白盒知识转移策略、强化学习及偏好优化,从而提升小模型的性能。
基于 EasyDistill 框架,我们进一步开源了 DistilQwen 模型系列,并且提供了蒸馏技术的实际应用案例EasyDistill-Recipes。特别地,DistilQwen 模型系列的最新版本额 DistilQwen-ThoughtX 实现了变长思维链输出,其推理能力超越了其他开源蒸馏模型。此外,本文还介绍了 EasyDistill 框架的开源数据集,包括100万条指令遵循和200万条思维链推理数据集,以支持社区开发者的使用和进一步提升模型性能。所有数据集均可在HuggingFace 和 ModelScope 平台获取。
在未来,我们将进一步扩展 EasyDistill 框架的功能,开源更多 DistilQwen 模型系列和相应资源。欢迎大家加入我们,一起交流大模型蒸馏技术!
6. 参考工作
相关论文
- Chengyu Wang, Junbing Yan, Wenrui Cai, Yuanhao Yue, Jun Huang. EasyDistill: A Comprehensive Toolkit for Effective Knowledge Distillation of Large Language Models. arXiv preprint
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Reasoning with OmniThought: A Large CoT Dataset with Verbosity and Cognitive Difficulty Annotations. arXiv preprint
- Wenrui Cai, Chengyu Wang, Junbing Yan, Jun Huang, Xiangzhong Fang. Training Small Reasoning LLMs with Cognitive Preference Alignment. arXiv preprint
- Chengyu Wang, Junbing Yan, Yuanhao Yue, Jun Huang. DistilQwen2.5: Industrial Practices of Training Distilled Open Lightweight Language Models. ACL 2025
- Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Building a Family of Data Augmentation Models for Low-cost LLM Fine-tuning on the Cloud. COLING 2025
- Yuanhao Yue, Chengyu Wang, Jun Huang, Peng Wang. Distilling Instruction-following Abilities of Large Language Models with Task-aware Curriculum Planning. EMNLP 2024
技术介绍
欢迎大家在评论区互动留言哦!