阿里巴巴旗下通义千问团队于2025年4月29日正式发布了最新一代大语言模型Qwen3系列,标志着开源人工智能领域的又一重大突破。此次发布包括多款模型,从0.6B参数的轻量级版本到235B总参数的旗舰MoE模型不等,全部采用Apache 2.0许可证开源。
![]()
核心亮点
Qwen3系列最大的创新在于引入「思考模式」与「非思考模式」的混合设计。在思考模式下,模型会进行深入的逐步推理;而非思考模式则提供快速响应。这种设计允许用户根据实际需求灵活调整「思考预算」,在复杂任务上投入更多计算资源,简单任务则快速完成。
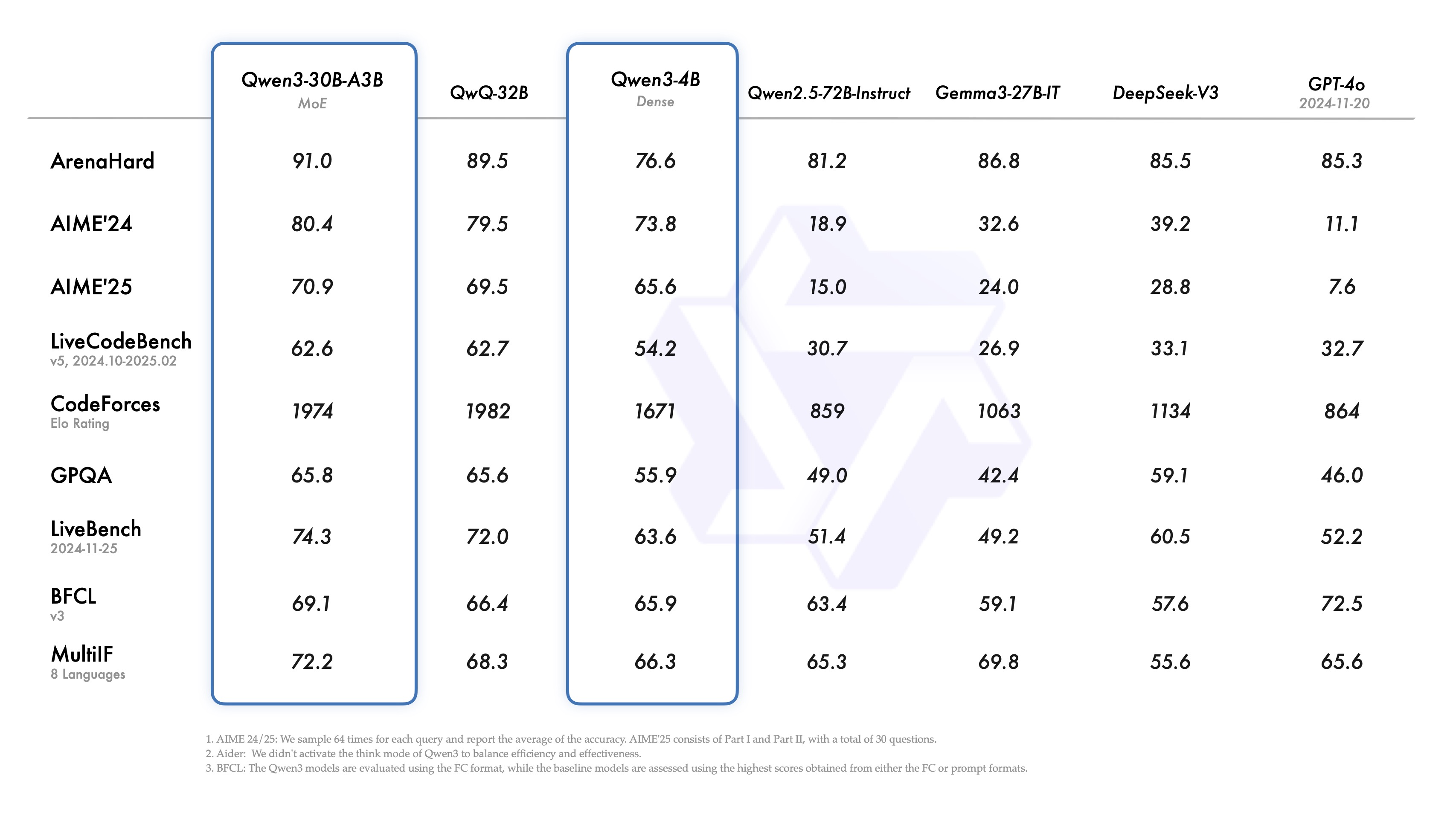
旗舰模型Qwen3-235B-A22B拥有2350亿总参数,但仅激活约220亿参数,在代码、数学和通用能力上与DeepSeek-R1、OpenAI的o1、o3-mini、Grok-3和Gemini-2.5-Pro等顶级模型相比表现极具竞争力。
![]()
更令人惊讶的是体量更小的Qwen3-30B-A3B模型,它仅激活30亿参数(是QwQ-32B的10%),却能提供更强的性能。甚至4B参数的小模型也能匹敌此前Qwen2.5-72B-Instruct的表现水平。
技术特色
Qwen3模型支持119种语言和方言,预训练数据量达到约36万亿个token,几乎是Qwen2.5的两倍。训练过程分为三个阶段,包括基础预训练、知识密集型数据强化和长上下文扩展。
在后训练阶段,模型经历了四个关键步骤:长思维链冷启动、长思维链强化学习、思维模式融合以及通用强化学习,这使得最终模型能够同时具备深度推理和快速响应的能力。
社区反响
Hacker News社区对这一发布反响热烈。用户们普遍认为这是开源模型领域的一次重大突破,尤其对Qwen团队在发布前就与各大框架和社区协作的态度表示赞赏。
一位用户评论:「他们提前数周就为qwen3支持修补了所有主要的LLM框架,如llama.cpp、transformers、vllm、sglang、ollama等,并在同一时间在各平台上发布模型权重。就像一次全球电影首映。不能低估这种细节和努力水平。」
Qwen3-30B-A3B模型因其平衡的性能和资源消耗比受到特别关注,被认为可能是本地部署代码助手的理想选择。有用户评论:「到目前为止,我发现开源权重模型要么不如专有对手那么好,要么在本地运行太慢。这(Qwen 3)看起来是一个很好的平衡。」
与竞争对手的比较
此次发布时机引人注目,恰好发生在Meta的LlamaCon大会前夕,多位用户将Qwen3与即将发布的Llama系列新模型进行了比较,认为阿里的这次发布展示了更成熟的开源策略。
有用户指出:「这比Llama 4更令人信服!」另一位评论:「这是LlamaCon周最大的公告!」
还有用户分享了性能体验:「在聊天中尝试了一个小型编码任务,大模型(235B)产生了相当令人印象深刻的答案。它甚至不需要『使用堆』这样的提示,自己就能理解问题所需的算法。」
技术部署与实用性
Qwen3系列模型已在Hugging Face、ModelScope和Kaggle等平台开放使用。官方推荐使用SGLang和vLLM进行部署,而本地使用则可选择Ollama、LMStudio、MLX、llama.cpp和KTransformers等工具。
一个值得注意的特点是,Qwen3内置对MCP(机器控制协议)的支持,这是开源模型过去普遍欠缺的Agent能力,使其能更好地与环境交互和使用工具。
预训练创新
Qwen团队采用了创新的方法扩充训练数据。他们不仅从网络收集数据,还利用Qwen2.5-VL从PDF文档中提取文本,并用Qwen2.5提升内容质量。此外,他们还使用Qwen2.5-Math和Qwen2.5-Coder这两个专家模型合成了大量数学和代码领域的数据,包括教科书、问答对和代码片段等。
行业意义
Qwen3的发布代表着开源AI领域的一次质的飞跃。模型设计上融合了思考与速度的平衡,在技术能力上达到了与封闭商业模型竞争的水平,而开源许可则确保了研究者和开发者能自由使用和改进这些模型。
Hacker News用户总结道:「我们真的正接近这样一个点:本地模型已足够强大,能处理大多数人需要完成的几乎所有任务。」
Qwen3系列的成功发布,不仅展示了阿里巴巴在AI领域的技术实力,也为全球AI开源社区注入了新的活力,可能会加速开源模型在更多应用场景中的部署与创新。如官方所言,Qwen3将「思深,行速」的理念带入了AI实践,为下一代人工智能的发展指明了方向。