作者:明巍/临城/水德
还在为部署动辄数百 GB 显存的庞大模型而烦恼吗?还在担心私有代码库的安全和成本问题吗?通义灵码团队最新研究《Thinking Longer, Not Larger: Enhancing Software Engineering Agents via Scaling Test-Time Compute》探索了如何通过扩展测试时计算(Test-Time Compute Scaling, TTS),让个人可部署的开源大模型(如仅需单卡运行的 32B 模型),达到与顶级闭源模型(如 DeepSeek R1, OpenAI o1)相媲美的代码推理和问题解决能力。
核心亮点:
-
性能飞跃:32B 模型在结合了两种 Test Time Scaling 策略后,在 SWE-bench Verified 基准上,成功解决了 46.0% 的真实 GitHub Issue,与 DeepSeek R1 和 OpenAI o1 等更大规模的业界领先模型表现相当;
-
实证 TTS 现象:内部 TTS (Internal TTS) 通过高质量、多阶段的合成开发轨迹进行训练,让模型学会深度思考,模型在面对更有挑战的问题时,会动态地分配更多计算资源(输出更多 Token),这验证了"思考更长时间"确实能提升模型解决复杂任务的能力。
-
最优开发过程搜索:在软件开发的关键决策点(如仓库理解、故障定位)进行干预,利用过程奖励模型和结果奖励模型指导搜索,以更优的计算效率找到最佳解决方案。同时利用更大的推理 budget 会产生更优的性能。
方法:内外兼修的 Test-time Scaling 策略
我们提出了一个统一的测试时计算(TTS)扩展框架,包含两种互补策略:
1. 内部 TTS (Internal Test-Time Scaling): 内化深度思考能力
-
高质量轨迹合成 (High-Quality Trajectory Synthesis):
- 数据源 : 从 GitHub 上筛选 超过 1000 星标 的高质量仓库,收集真实的
<issue, pull-request, codebase> 三元组数据。
- 初始过滤: 应用启发式规则过滤数据,例如,保留描述足够详细的 issue (≥20 字符, ≤3 超链接),以及修改量适中 (1-5 个代码文件, 非纯测试文件修改) 的 PR。
- 环境构建与验证 : 利用
ExecutionAgent 尝试为每个仓库自动构建可执行的测试环境,确保后续能够进行真实的补丁验证。无法成功构建或运行环境的仓库被排除,最终形成包含约 9000 个 issue 和 300 个仓库 的高质量数据集。
-
轨迹引导与增强 (Trajectory Bootstrapping):
-
基础框架 : 基于开源的 SWE-SynInfer 框架(包含仓库理解、故障定位、补丁生成三个阶段),增加了补丁验证 (Patch Verification) 阶段,形成 SWE-SynInfer+ 框架。在此阶段,模型需生成复现代码来自动验证补丁有效性,并在失败时进行迭代优化。
-
引导模型: 使用开源推理模型 DeepSeek R1作为教师模型,在其多次内部推理迭代和优化的能力下,生成详尽的、包含多轮思考与修正的 长思维链(Long CoT)轨迹。
-
开发上下文的拒绝采样 (Development-Contextualized Rejection Sampling):
- 多维质量把关 : 对生成的轨迹进行严格的多维度验证和过滤:
- 仓库理解准确性: 检查模型识别的待修改文件是否与开发者实际修改的文件一致。
- 故障定位准确性: 确认模型生成的补丁是否作用于开发者实际修改的代码位置(类、函数、代码块)。
- Issue 复现代码有效性: 验证生成的复现代码能否在原始代码上触发问题,在应用开发者补丁后问题消失。
- 补丁正确性: 应用模型补丁后,运行其生成的复现代码和仓库原有的单元测试,检查问题是否解决且无新问题引入。
- 复杂性过滤: 筛除掉基础模型(Qwen2.5 Coder 32B)无需复杂推理就能一次性解决的简单问题,确保训练数据能有效激发模型的深度推理潜力。
- 保留有效中间步骤: 如果一个轨迹的补丁验证失败,但之前的仓库理解、故障定位等步骤是正确的,保留这些正确的中间步骤数据,避免浪费有价值的推理过程信息。
-
推理式训练 (Reasoning Training):
- 学习目标: 采用标准的监督学习,优化模型生成正确推理动作(包括思考过程和最终行动)的条件概率。损失函数同时计算轨迹中每个步骤的 "思考(think)"(规划、反思、修正等)和 "回答(answer)"(最终输出的 API 调用、代码补丁等)部分,促使模型学习完整的决策过程。
- 历史信息剪枝 : 为提高多轮推理效率,借鉴 DeepSeek R1 的机制,在生成第
i 步时,历史上下文中只保留第 i-1 步的 answer 部分,舍弃 think 部分,减少冗余信息。
2. 外部 TTS (External Test-Time Scaling): 优化决策搜索路径
-
基于开发流程的搜索策略 (Development-Process-Based Search, Dev-Search):
- 核心思想: 软件工程任务是长链条决策过程,中间步骤的错误会严重影响最终结果。我们摒弃仅在终点验证或对每一步都进行低效验证的做法,选择在 三个关键决策阶段(仓库理解、故障定位、补丁生成)集中进行搜索和评估,以高效利用计算预算。
-
过程奖励模型 (Process Reward Model, PRM) 引导:
- 训练目标: 训练 PRM(基于基础模型微调)来判断中间输出的正确性(二元分类任务)。例如,判断识别的文件是否正确,定位的代码位置是否准确。
- 引导方式: 在每个阶段生成 N 个候选输出,使用 PRM 对其打分,保留 Top-k 的高分候选进入下一阶段,实现轻量级的、有指导的 Beam Search,有效剪枝低潜力路径。
-
执行验证与结果奖励模型 (Outcome Reward Model, ORM) 排序:
- 补丁验证: 在补丁生成阶段,利用模型生成的复现代码和仓库自带的回归测试,对候选补丁进行执行验证,确保其有效性且不破坏原有功能。
- 最终排序: 对于通过执行验证的多个候选补丁(可能存在多个),使用 ORM 进行最终排序。ORM 基于 DPO 进行训练,学习偏好"通过所有测试"的补丁优于"未通过测试"的补丁。重要的是,ORM 仅需 Issue 描述和候选补丁作为输入,不依赖中间推理步骤,易于集成。
* 所有模型均基于开源的Qwen2.5 Coder 32B模型进行训练,该模型可在消费级显卡上进行部署。
实验评估:
1. 整体性能 SOTA:
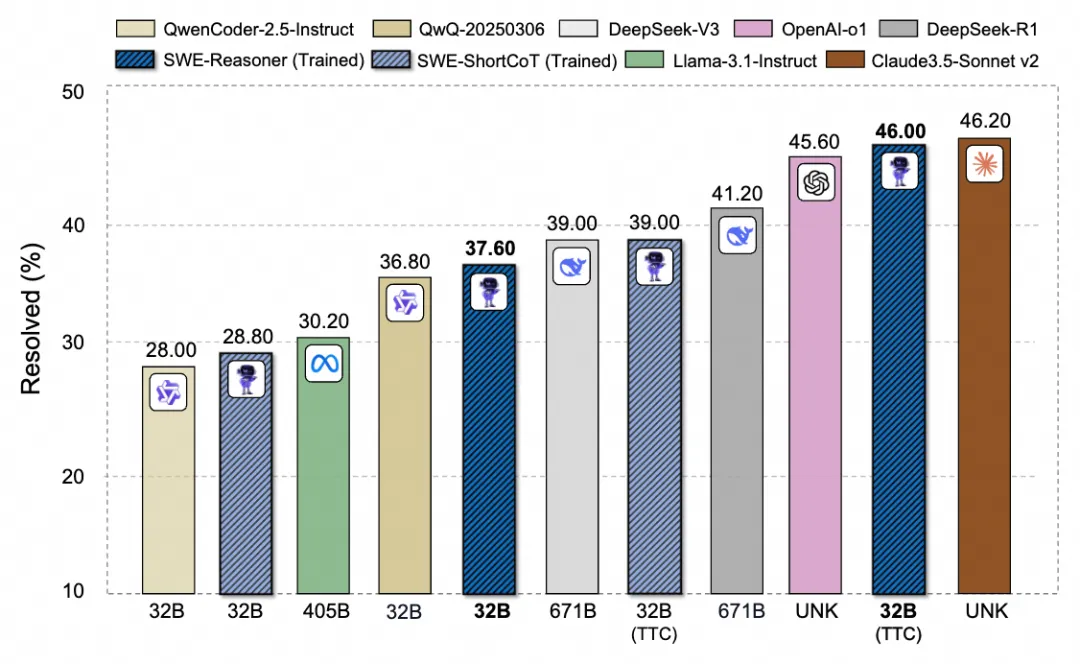
- 结果 :训练的 SWE-Reasoner 32B 模型结合了内部和外部 TTS (Unified TTC, budget=8) 后,达到了 46.0% 的 Issue 解决率。
- 对比 :在 ≤100B 参数量级 的模型中处于领先地位,超越了如 DeepSeek R1 671B (41.20%) 等更大的开源模型,并且接近业界顶尖的闭源模型 Claude 3.5 Sonnet v2 (46.20%) 和 OpenAI o1 (45.60%) 。(详见图1和表1)
- 泛化性与独特性 : 该模型在 SWE-bench 覆盖的 12 个不同 Python 仓库 上均表现出鲁棒的性能,在多数仓库上媲美或超越 DeepSeek R1 671B(详见图2)。此外,通过与其他模型的解决实例对比,我们的方法能够独立解决 17 个 其他模型无法解决的 Issue,展现了独特的解题能力。
![]()
图 1: 在 SWE-Bench Verified 上,对具有扩展测试时间计算的较小 LLM 与较大模型的性能进行比较
![]()
表 1: 与不同模型和框架在 SWE-bench Verified 基准上的性能比较。
![]()
图 2: 针对不同仓库的 issue 解决率比较
- 内部 TTS 研究分析:
- 不同难度性能优势:Long CoT 训练相比 Short CoT 训练在解决更难 issue 上提升明显(基于社区解决频率划分的 Level 5,效果提升约 6 倍,详见图 3)。
- Test-Time Scaling 现象:Reasoning 模型在解决更难的问题上会尝试输出更多 token,有明显的 test-time scaling 现象(SWE-Reasoner 和 OpenAI o1),Claude 3.5 Sonnet 也有这个 TTS 现象,但是整体输出 token 较少。而 Short CoT 模型则没有这种明显的自适应计算行为(详见图 4)。
![]()
图 3: 在不同难度的 SWE-bench Verified 上的不同模型的解决率
![]()
图 4: 在不同难度的 SWE-bench Verified 上的不同模型的平均输出 tokens 比较
- 外部 TTS 研究分析:
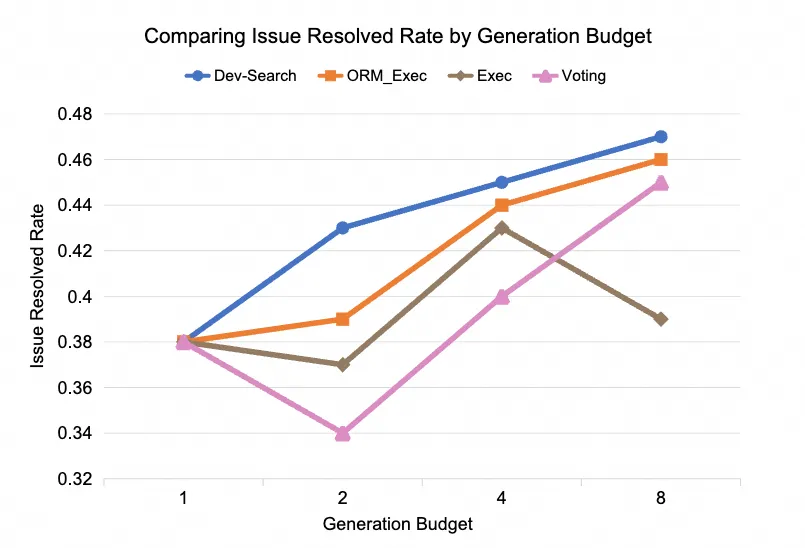
- Dev-Search 策略优势 ,在控制相同推理预算(Rollout 次数 1, 2, 4, 8)的条件下,我们提出的 Dev-Search 策略始终优于仅依赖执行验证 (Exec)、执行验证+ORM (ORM_Exec) 或投票 (Voting) 的基线方法。这证明了在关键开发流程中进行干预和指导能带来更优的搜索效率。(详见图 5)
- 预算与性能关系 (TTS) : 增加推理预算(Generation Budget)通常能带来性能的提升,再次验证了外部 TTS 的有效性 。预算的增加对于解决简单和中等难度(Level 1-4)的问题提升尤为明显。
- 高难度任务瓶颈 : 对于最高难度 (Level 5)的问题,过高的推理预算反而可能导致性能轻微下降。这暗示对于极其复杂的任务,仅靠外部搜索扩展可能已触及模型内在推理能力的瓶颈,需要内部 TTS(想得更深)的共同作用或更强的基础模型能力。(详见图 6)
![]()
图 5: 不同搜索方式在相同 budget 下的性能比较
![]()
图 6: 在不同难度的 SWE-bench Verified 上使用不同 budget 的能力比较
结论
本研究成功展示了通过统一的测试时计算(TTS)扩展框架,可以显著增强个人可部署的开源 SWE Agent 的代码推理和问题解决能力。我们证明了"思考更长时间"(增加推理计算)而非"模型更大"(增加参数)是提升模型在复杂软件工程任务中表现的有效途径。这项工作为在资源受限环境下(如私有部署)使用和发展高性能 SWE Agent 开辟了新的可能性。
展望与思考:更智能更自适应的 SWE Agent
- 自适应计算 : 未来可以研究如何让模型根据任务难度动态、自适应地调整计算资源的投入,实现效率与效果的最佳平衡。
- 环境与验证: 提升自动化测试环境构建和解决方案验证的鲁棒性与规模,是进一步利用强化学习 (RL) 释放 SWE Agent 潜力的关键。
- 任务泛化: 将此 TTS 框架应用到更广泛的软件工程任务中,如测试用例生成和代码重构等。
🔎 详细方案请参考论文:
arxiv📄: https://arxiv.org/abs/2503.23803
Github🌟: https://github.com/yingweima2022/SWE-Reasoner