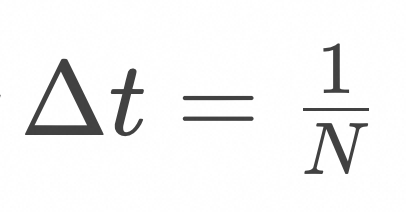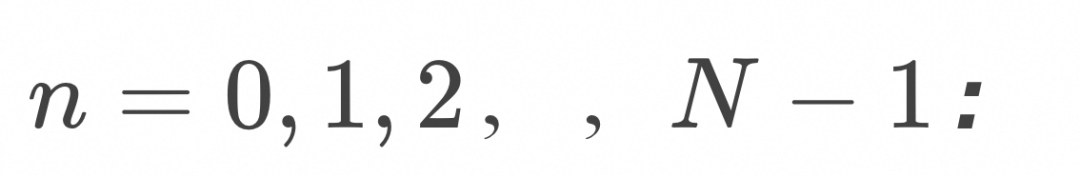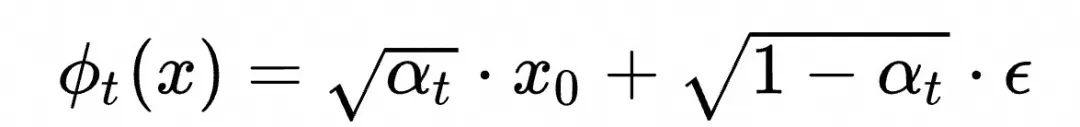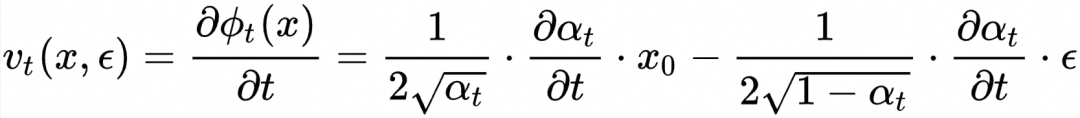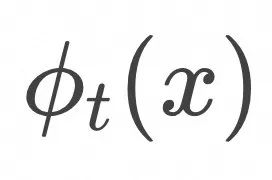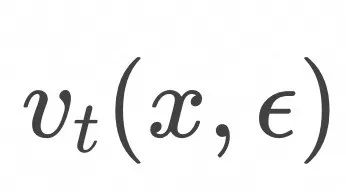随着生成式人工智能的快速发展,扩散模型逐渐成为领域内的焦点技术之一。从稳定扩散(Stable Diffusion)到 MidJourney,再到近期的 Flux 和 DALLE3等,各种扩散模型在生成图像的表现上日趋完善。扩散模型不仅在生成艺术画作和创意设计中展示了强大的能力,也在内容创作、电商营销等场景发挥重要价值。
扩散模型的理论框架主要包括 DDPM、score matching 和 flow matching 等。flow matching 作为一种更灵活简洁的训练范式,被当前最前沿的开源文生图、文生视频模型所采用,如 SD3 和 Flux等。它不仅显著提升了训练的收敛效率,同时也更易于从理论层面进行理解。
在本文中,我们将以 Flow Matching 为切入点,深入探讨扩散模型的基础原理。网络上关于扩散模型原理的解读文章中,通常有着大量复杂的公式推导,而扩散模型训练算法本身却非常简洁。本文将尽量避开冗长的公式推导,力求以清晰直观的方式揭示这些简洁的算法形式背后的核心原理。
![]() 扩散模型
扩散模型
![]()
生成模型简介
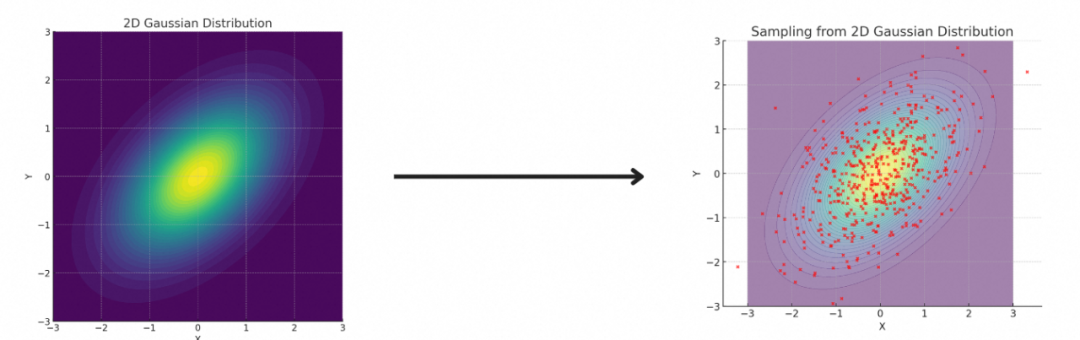
对于一些简单的分布,例如均匀分布和高斯分布,我们可以通过简单的算法轻松实现采样。
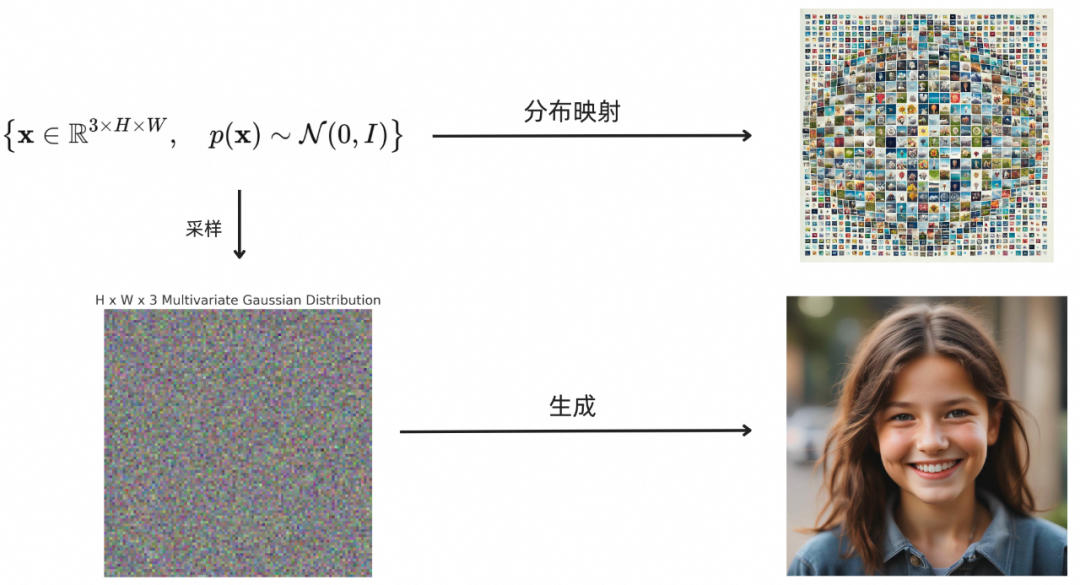
然而,对于自然图像这样的高维复杂分布,由于缺乏解析解,采样变得异常困难。尽管我们可以收集大量自然图像的样本,但要从中生成新的样本却并非易事。生成模型的目标是基于训练集中的已有样本,学习并从其背后的分布中进行采样。
![]() 图像生成模型
图像生成模型
对于自然图像这样的复杂分布,我们可以通过某种方法构建其与简单分布(通常是高斯分布)之间的映射关系。通过这种映射关系,可以先从简单分布中采样,再映射到复杂分布,从而实现对复杂分布的采样目标。而如何构建这一映射过程,正是各类生成算法的核心。
![]() 图像生成建模
图像生成建模
Flow Matching
▐ Continuous Normalizing Flow
Continuous Normalizing Flow是一种能够将简单分布映射为任意复杂分布的方式,我们先通过一个简单的例子来理解一下。
![]() 湖面上小黄鸭分布的变换
湖面上小黄鸭分布的变换
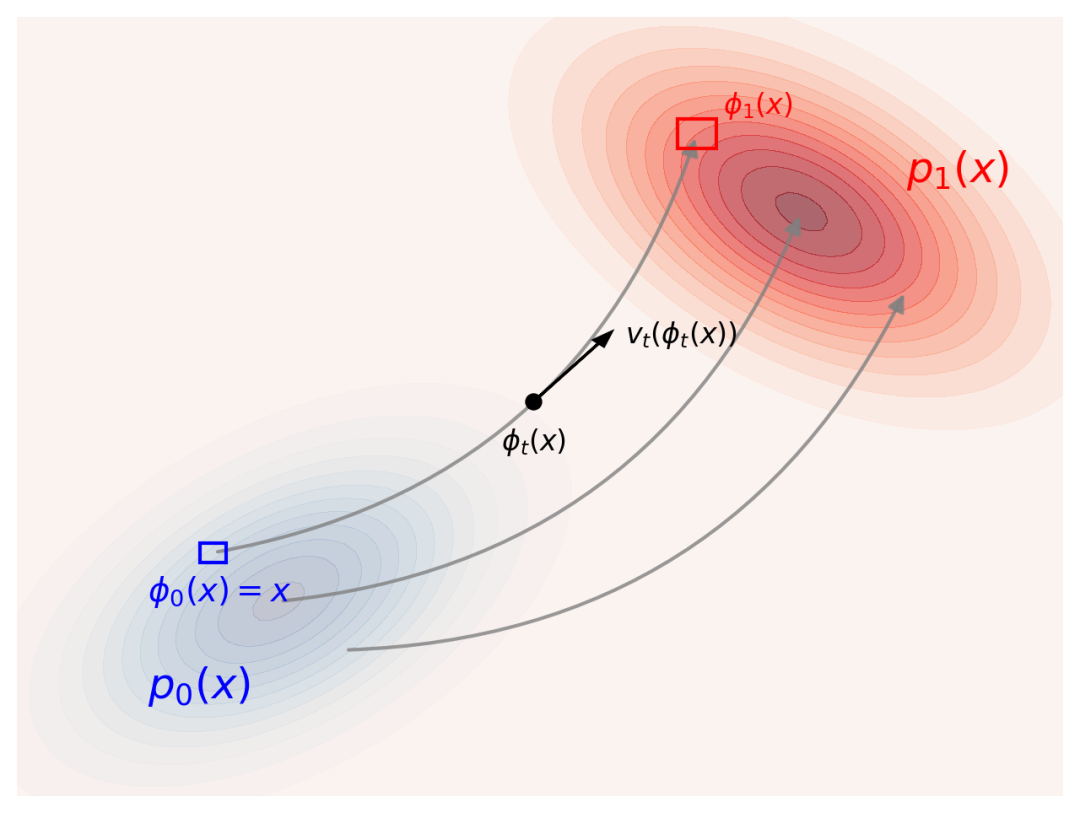
想象这样一个场景:湖面上漂浮着大量小黄鸭,它们的位置分布呈现出一个简单的二维高斯分布。而所有的小黄鸭都严格跟着湖面水流的运动而移动。如果我们能够精确控制任意时刻湖面上每一点的水流方向和速度,是否就能将这群小黄鸭的位置分布调整为任意指定的分布呢?答案是肯定的。下面我们将通过更精确的数学语言来描述这一过程:
记数据点为![]() 表示d-维样本数据空间中的一个点。(对应例子中湖面空间)
表示d-维样本数据空间中的一个点。(对应例子中湖面空间)
我们定义一个随时间变化的向量场: ![]() 该向量场定义在数据空间的每个点上,且随时间 t 变化,其维度与数据空间维度一致。(对应任意时刻湖面上每一点的水流方向和速度)
该向量场定义在数据空间的每个点上,且随时间 t 变化,其维度与数据空间维度一致。(对应任意时刻湖面上每一点的水流方向和速度)
3.样本随时间演化
样本点x在数据空间中样本随时间t∈[0,1] 演化的轨迹记为 ![]() (对应任一只小黄鸭在湖面上的运动轨迹),满足下面的常微分方程。
(对应任一只小黄鸭在湖面上的运动轨迹),满足下面的常微分方程。
这一方程表明,样本点(小黄鸭)的位置随时间变化,完全受当前所处位置的向量场(湖面水流方向和速度)决定。
4.样本概率分布的随时间变化
对于定义在数据空间中的某个初始概率分布![]() ,如果所有样本都按照上面的常微分方程运动,可以证明对应的概率分布
,如果所有样本都按照上面的常微分方程运动,可以证明对应的概率分布![]() 随时间的变化规律满足以下公式:
随时间的变化规律满足以下公式:
简单来说,![]() 与
与![]() 在变换前的初始点的概率
在变换前的初始点的概率![]() 成正比。而
成正比。而 ![]()
描述了变换过程中空间伸缩的程度。可以将其理解为变换前后某点邻域的空间体积比值(例如下图中蓝色小正方形和红色小正方形的面积比)。所以上面的公式实际上是变换前后某个点邻域概率守恒的表现。
不过,在后续推导中我们并不直接使用这一公式,关键在于当![]() 时,初始分布
时,初始分布![]() 映射为目标
映射为目标 ![]() ,并且这个过程是可逆的。由此,我们得到了一个理论上将任意两个分布相互映射的方法。
,并且这个过程是可逆的。由此,我们得到了一个理论上将任意两个分布相互映射的方法。
如果我们知道一个简单分布 ![]() 映射到复杂分布
映射到复杂分布 ![]() 对应的flow
对应的flow ![]() (并不唯一),则可以通过下面的方式实现对复杂分布的采样。
上述迭代过程本质上是通过数值离散化求解前述的常微分方程。实际上,任何适用于常微分方程的求解方法都可以替代上述简单的迭代方式。扩散模型的采样过程核心在于求解这一常微分方程,而各种加速采样的算法本质上都是在研究如何更高效地求解该方程。
(并不唯一),则可以通过下面的方式实现对复杂分布的采样。
上述迭代过程本质上是通过数值离散化求解前述的常微分方程。实际上,任何适用于常微分方程的求解方法都可以替代上述简单的迭代方式。扩散模型的采样过程核心在于求解这一常微分方程,而各种加速采样的算法本质上都是在研究如何更高效地求解该方程。
▐ Flow Matching求解![]()
通过前面的铺垫,我们在理论上已经掌握了一种从任意复杂分布中进行采样的方法。然而,接下来面临的关键问题是:我们如何得到简单分布 ![]() 映射到复杂分布
映射到复杂分布 ![]() 对应的flow
对应的flow ![]() ?而这正是Flow Matching算法的核心所在。
?而这正是Flow Matching算法的核心所在。
![]() 如何求解
如何求解 ![]()
a.简单高斯分布的映射
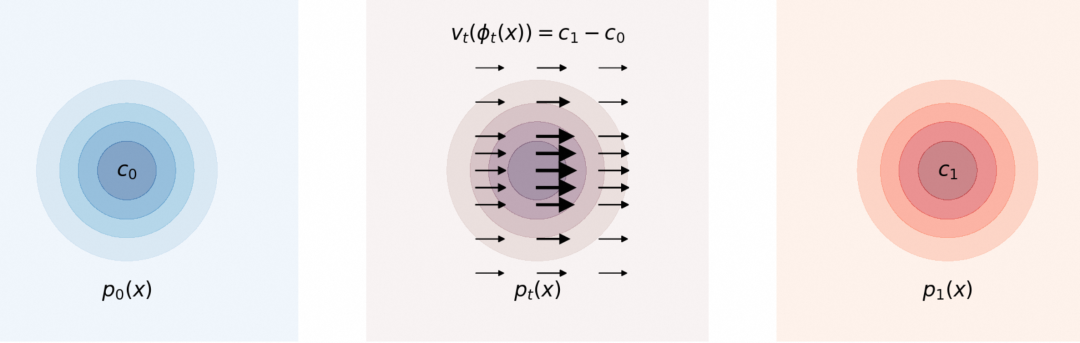
首先考虑一个非常简单的情形:![]() 和
和![]() 为标准差σ 相同,均值点分别为
为标准差σ 相同,均值点分别为![]() 和
和![]() 的多维高斯分布,这种情况下一个可能的解为类似匀速直线运动的
的多维高斯分布,这种情况下一个可能的解为类似匀速直线运动的![]() 的常数向量场的解,如下面的视频所示。
的常数向量场的解,如下面的视频所示。
标准差相同的高斯分布之间的映射
对应的向量场表达式为常数![]()
![]()
标准差相同的高斯分布之间的映射
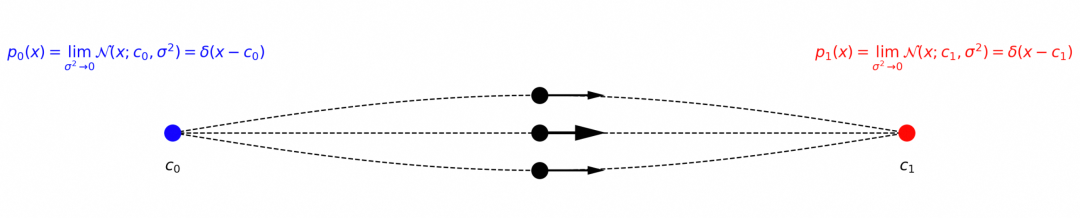
这表明两个标准差相同的高斯分布可以通过简单的“匀速直线运动向量场”进行映射。如果考虑![]() 的极限,上面的情形退化为两个delta分布之间映射。delta 分布可以简单理解为所有概率分布集中于一点的分布。
的极限,上面的情形退化为两个delta分布之间映射。delta 分布可以简单理解为所有概率分布集中于一点的分布。
这种情况下, ![]() ,且对应的样本运动轨迹集中在下面的直线上
,且对应的样本运动轨迹集中在下面的直线上 ![]() 对应的随时间演化的概率分布为
对应的随时间演化的概率分布为
b.复杂分布的映射
前面我们介绍了简单高斯分布和delta分布的映射方法。对于任意分布![]() 和
和![]() ,它们表达为delta分布的线性叠加:
,它们表达为delta分布的线性叠加:
根据上一节的推导,上面线性叠加中的两个delta分布之间的映射的条件概率随时间演化可以表达为
对应的条件向量场为 ![]() 将上面的条件概率演化路径
将上面的条件概率演化路径![]() 进行线性叠加得到的边缘概率随时间演化表达为
进行线性叠加得到的边缘概率随时间演化表达为
不难发现,上面的边缘概率分布随时间演化能够从![]() 映射到
映射到![]()
那么上面的边缘概率随时间演化![]() 对应的flow
对应的flow![]() 是什么呢?
是什么呢?
![]()
![]() 是简单的delta函数映射条件概率
是简单的delta函数映射条件概率![]() 的线性叠加,而
的线性叠加,而![]() 对应的条件向量场flow为简单的“匀速直线运动向量场”
对应的条件向量场flow为简单的“匀速直线运动向量场”![]() ,那么
,那么![]() 对应的flow
对应的flow![]() 是否就是这些“匀速直线运动向量场”的线性叠加呢?答案是肯定的,具体由下式得到。
是否就是这些“匀速直线运动向量场”的线性叠加呢?答案是肯定的,具体由下式得到。
上式表明,如上图所示,为了计算![]() ,随机采样
,随机采样![]() 和
和![]() ,在
,在![]() 条件下计算
条件下计算![]() 的期望值。
的期望值。
![]() 是
是 ![]() 的统计平均
虽然我们不在此证明该公式,但可以从物理直观上理解:在微观层面上,空气中每一点处的空气分子的运动方向和速度是随机的(可以用一个随机微分方程描述),但是在宏观上可以用统一的“风速场”进行描述(可以用常微分方程描述)。而这个“风速场”在某个点的值等于该点处空气分子随机运动速度的统计平均。如果我们只关心整个空间概率密度分布随时间的变化,微观空气分子随机运动与宏观“风速场”刻画的运动是完全等价(任何随机微分方程都可以找到对应的常微分方程,它们具有相同的概率密度随时间演化规律)。
的统计平均
虽然我们不在此证明该公式,但可以从物理直观上理解:在微观层面上,空气中每一点处的空气分子的运动方向和速度是随机的(可以用一个随机微分方程描述),但是在宏观上可以用统一的“风速场”进行描述(可以用常微分方程描述)。而这个“风速场”在某个点的值等于该点处空气分子随机运动速度的统计平均。如果我们只关心整个空间概率密度分布随时间的变化,微观空气分子随机运动与宏观“风速场”刻画的运动是完全等价(任何随机微分方程都可以找到对应的常微分方程,它们具有相同的概率密度随时间演化规律)。
c.对 ![]() 神经网络参数化
神经网络参数化
上一节的讨论实际上提供了一个计算![]() 理论可行的算法,具体如下:
理论可行的算法,具体如下:
Algorithm:计算t时刻任意![]() 处的向量场
处的向量场![]()
-
初始化空列表![]()
-
While![]() :
:
-
Return ![]()
实际上,我们不可能对所有可能的![]() 和
和![]() 去通过上面这种非常低效的方式去计算统计平均。因此,我们引入神经网络对
去通过上面这种非常低效的方式去计算统计平均。因此,我们引入神经网络对![]() 进行神经网络参数化,定义为
进行神经网络参数化,定义为![]() ,并通过优化网络参数使其收敛到:
,并通过优化网络参数使其收敛到:![]()
这样,我们通过一次网络的前向推理就可以得到![]() 和
和![]() 处的
处的![]() 。
。
那么接下来的问题是:如何构造网络的损失函数,通过训练使网络输出能够接近上述的期望形式?一个巧妙的解决方案是,可以证明,对于下面的L2 形式的损失函数,其最优解正是上述期望值形式:
背后的原因在于对于L2的loss,最优解就是对应的期望均值形式。
对此可以利用一个更简单的例子进行理解。如果向量![]() 是
是![]() 的一个函数,对于L2 的 loss,
的一个函数,对于L2 的 loss,![]() 很容易证明这个loss的最优解为(回忆一下最小二乘法)
很容易证明这个loss的最优解为(回忆一下最小二乘法)![]()
这两个case的区别仅仅在于,下面这个case只是一个向量的优化。而上面的case中,我们做的是定义在![]() 和
和![]() 的整个数据空间和时间上的向量场的优化。
的整个数据空间和时间上的向量场的优化。
顺便提一句,通常我们再讨论扩散模型的优化目标时,会提到“预测原图”、“预测噪音”,“预测噪音和原图的差值”等等,这些说法有一定的误导性。因为实际上我们并不是希望网络能够预测“原图”或者“噪音”,而是以它们为目标构造L2的loss,最终期望网络收敛到对应的以![]() 为条件的“原图”或者“噪音”的统计期望值。所以扩散模型的训练即使在完全收敛的情况下,它的loss也不为0,而是以
为条件的“原图”或者“噪音”的统计期望值。所以扩散模型的训练即使在完全收敛的情况下,它的loss也不为0,而是以![]() 为条件的“原图”或者“噪音”的统计方差。
为条件的“原图”或者“噪音”的统计方差。
d.Flow matching的训练和采样算法
对应于上面的loss形式,将![]() 设为高斯分布,
设为高斯分布,![]() 设为图像训练集对应的分布,我们得到Flow Matching的训练算法如下:
设为图像训练集对应的分布,我们得到Flow Matching的训练算法如下:
Algorithm:Flow Matching Training
-
初始化网络参数
![]()
-
-
采样图像样本
![]() ,高斯噪音
,高斯噪音![]()
-
计算
![]()
-
计算条件向量场
![]()
-
计算损失函数并更新网络
![]()
通过上面的训练算法完成对![]() 的训练以后,就可以通过求解常微分方程进行采样了,算法如下:
Algorithm:Flow Matching Inference
可以注意到,相对于DDPM最原始的形式,Flow Matching的训练和采样算法形式非常简洁,并且在实践中展现了更好的收敛效果。
的训练以后,就可以通过求解常微分方程进行采样了,算法如下:
Algorithm:Flow Matching Inference
可以注意到,相对于DDPM最原始的形式,Flow Matching的训练和采样算法形式非常简洁,并且在实践中展现了更好的收敛效果。
e.Flow Matching 的其他形式
![]()
前面我们在讨论两个delta分布之间的映射选择的“匀速直线运动”轨迹尽管是最为简单和自然的选择,但并不是唯一的选择。
任何在 ![]() 和
和![]() 时刻收敛到两个端点的且对
时刻收敛到两个端点的且对![]() 连续可导的轨迹都可以。例如DDPM的形式
连续可导的轨迹都可以。例如DDPM的形式![]() 尽管这个形式不再是“匀速直线运动”,但是我们仍然可以通过对时间求导得到
将
尽管这个形式不再是“匀速直线运动”,但是我们仍然可以通过对时间求导得到
将![]() 和
和![]() 带入前面的训练算法就可以得到对应的训练流程,尽管在Flow Matching的框架下看起来DDPM的轨迹选择似乎是个不那么简洁的选择。
带入前面的训练算法就可以得到对应的训练流程,尽管在Flow Matching的框架下看起来DDPM的轨迹选择似乎是个不那么简洁的选择。
在生成模型的研究中,构建简单分布与复杂分布之间的映射是核心挑战,而 Flow Matching 提供了一种高效解决方案。从 Continuous Normalizing Flow 的理论基础,到基于神经网络的高效实现,再到具体的训练和采样流程,Flow Matching 展现了极大的灵活性和实用性。此外,相较于传统的扩散模型,如 DDPM,Flow Matching 在框架简洁性和实际性能上均表现出优势。
本文以 Flow Matching 为核心,从理论和算法的角度系统地探讨了扩散模型的基本原理,并通过多个直观的示例和公式推导展示了其内在逻辑。
-
Flow Matching for Generative Modeling https://arxiv.org/abs/2210.02747
-
Improving and Generalizing Flow-Based Generative Models with Minibatch Optimal Transport
-
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
我们是淘天内容AI团队,负责运用最新的生成式AI能力,挖掘淘宝核心场景的痛点问题,通过内容生成、智能交互等方式,改善用户购物体验、降低平台&商家经营门槛。在过去的几年团队持续以技术驱动产品和商业创新,在给业务创造价值的同时,也在Agent、可控图文、视频生成,多模态统一大模型等最前沿的技术领域也有着广泛布局和深度探索,在NIPS,CVPR,ICLR等顶会发表了数十篇论文,欢迎对团队技术工作感兴趣的同学进行交流 或者加入我们 。








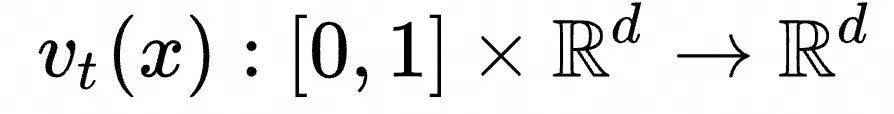
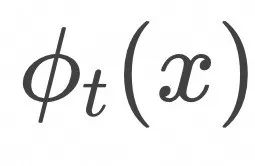
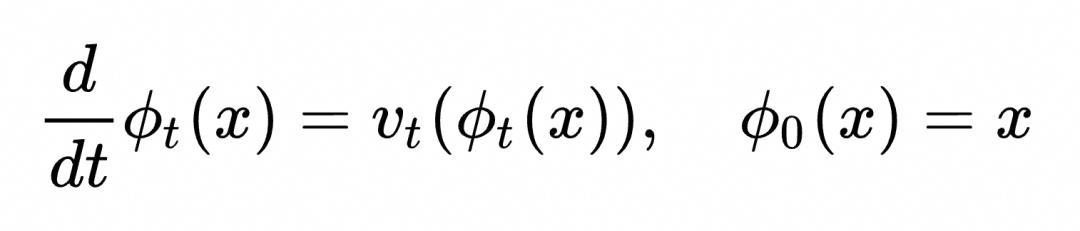
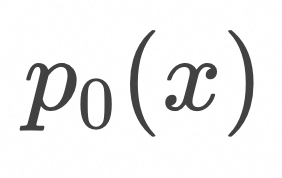
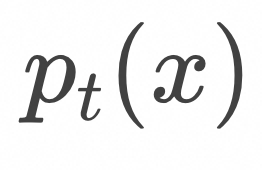
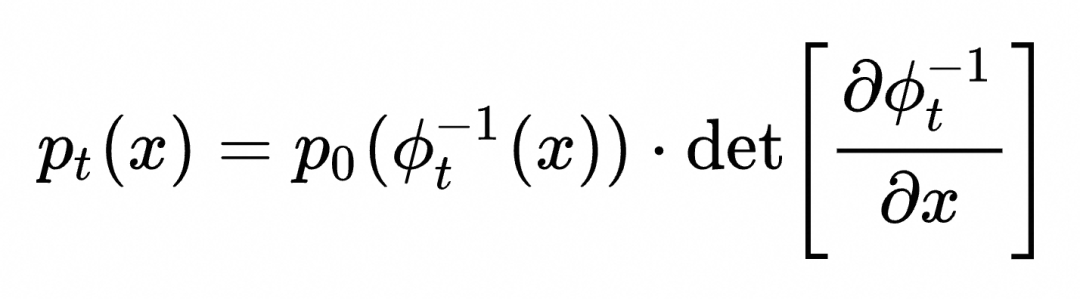
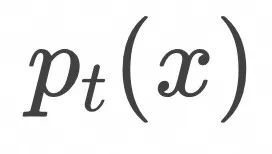
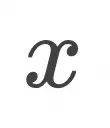
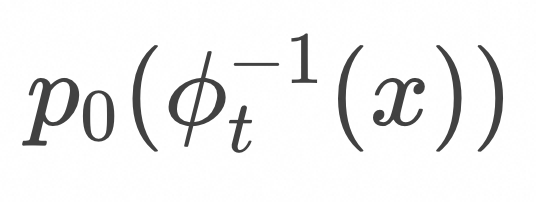

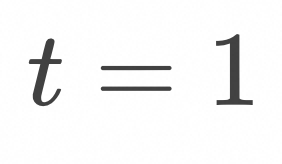
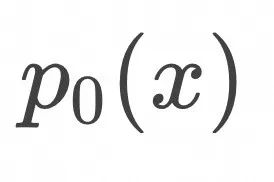
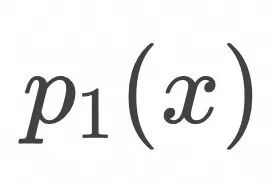
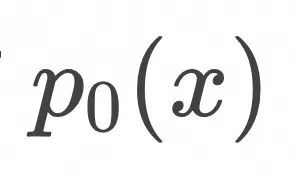
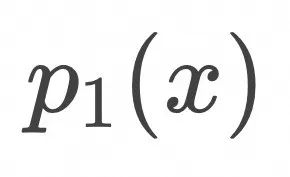
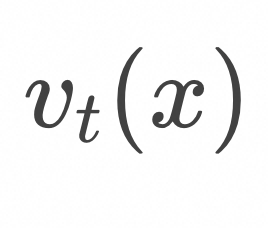
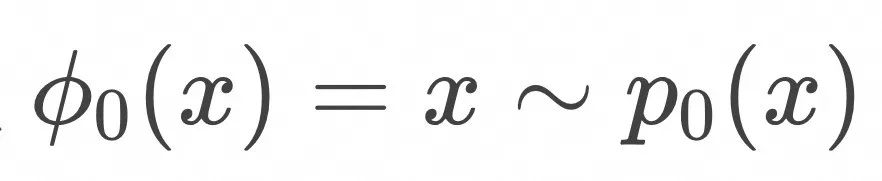
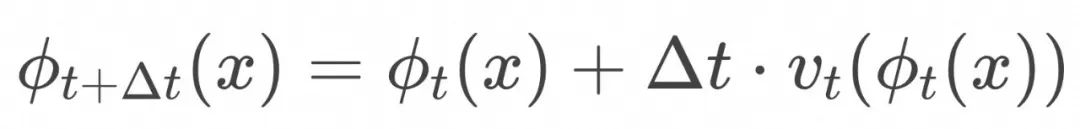
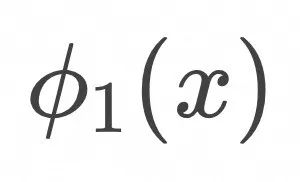
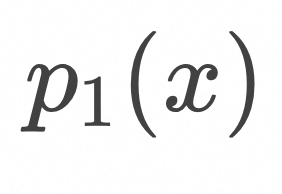
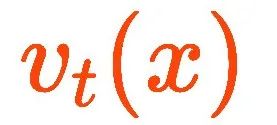
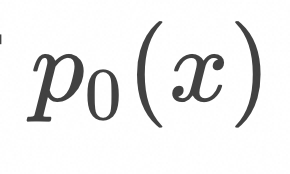

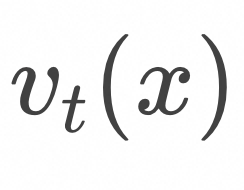

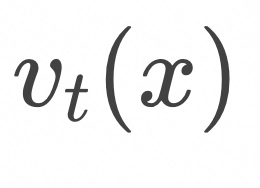
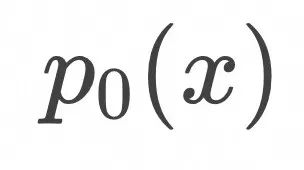
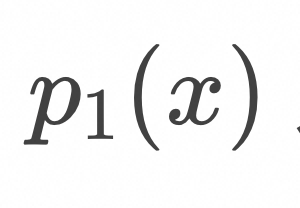
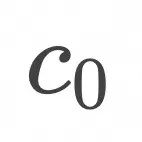
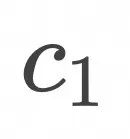
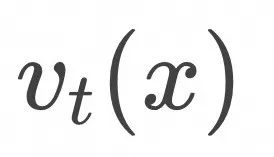
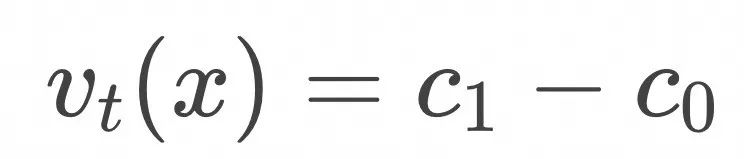


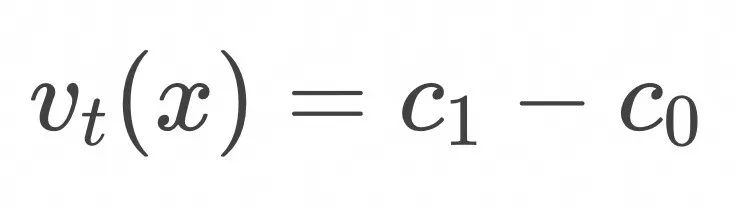
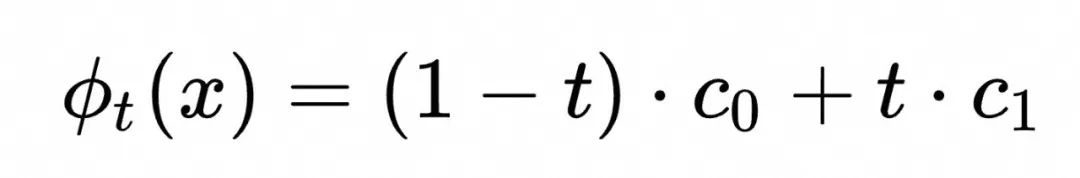
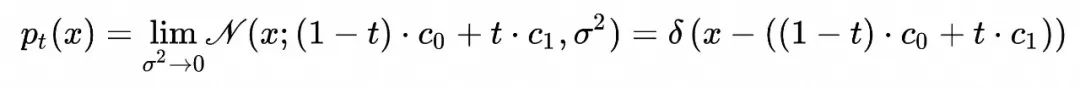

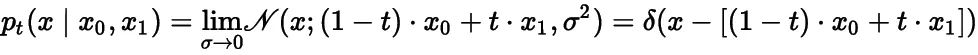
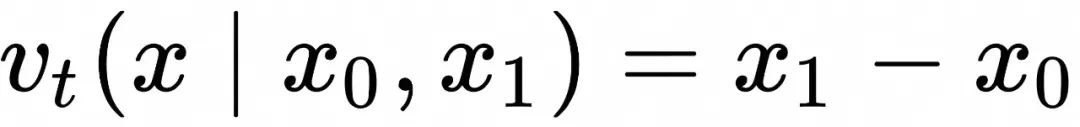
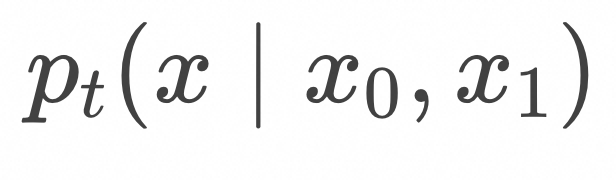
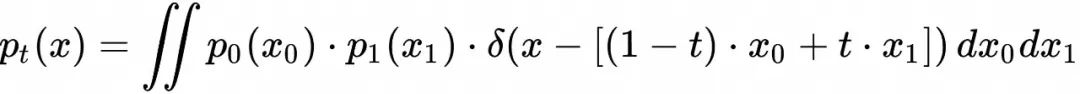
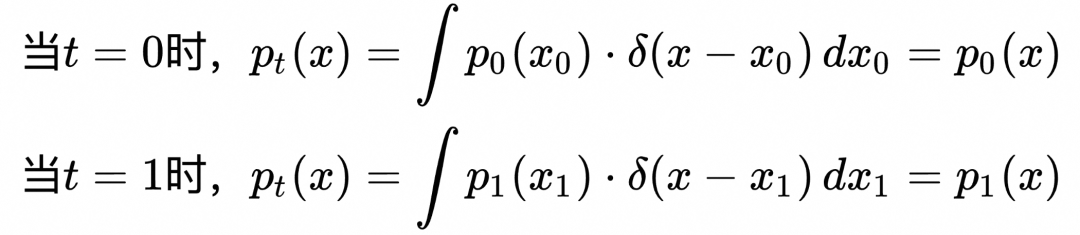
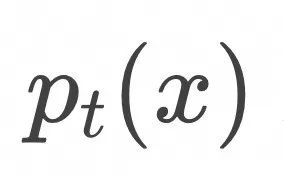
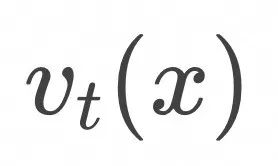
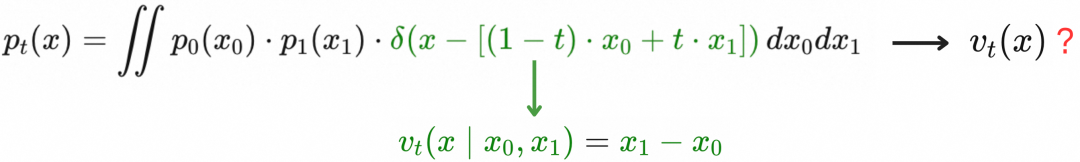
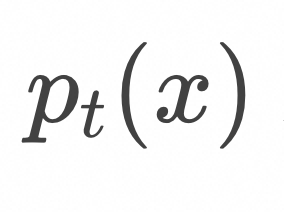
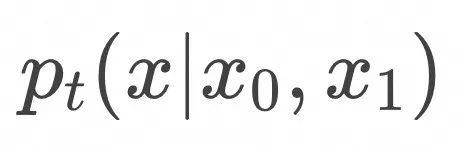
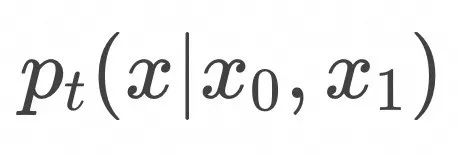
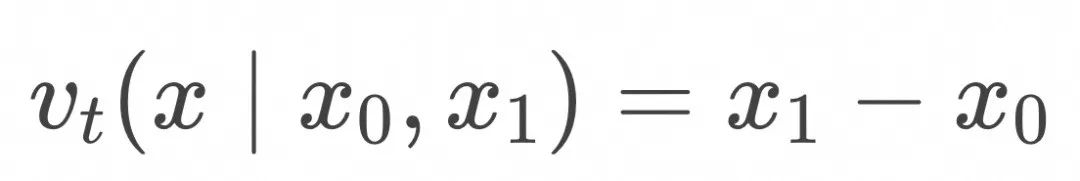

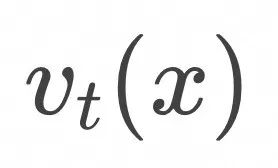
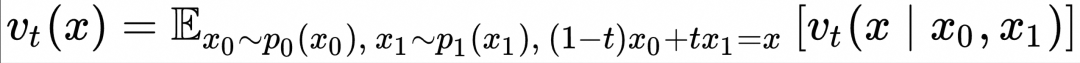
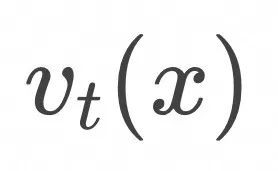
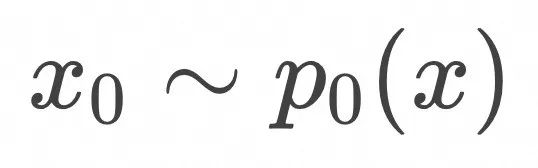
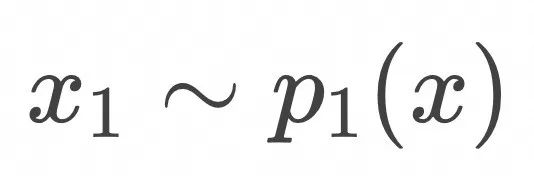 ,在
,在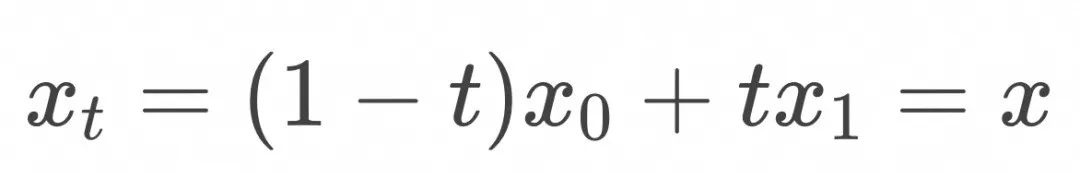
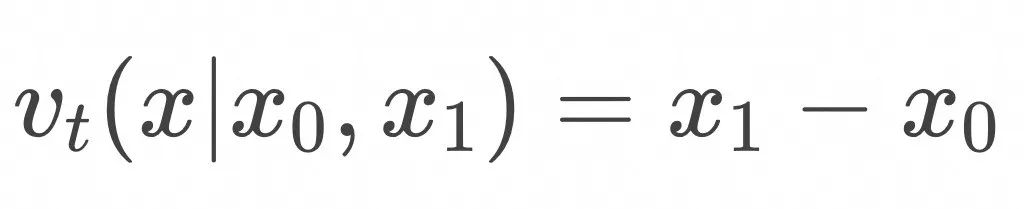 的期望值。
的期望值。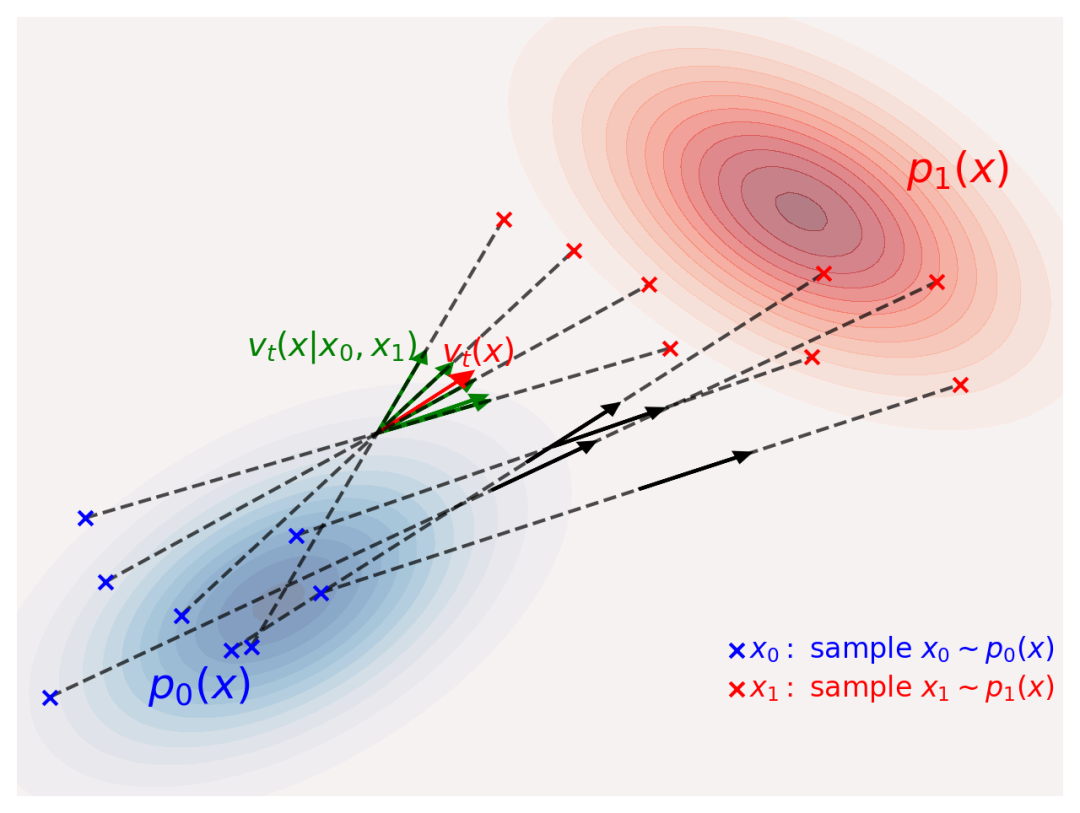
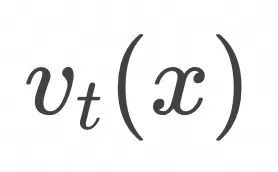
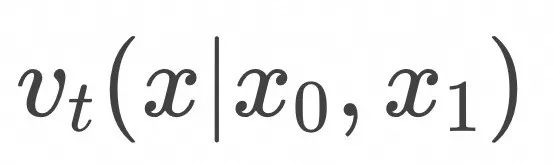
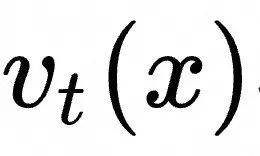
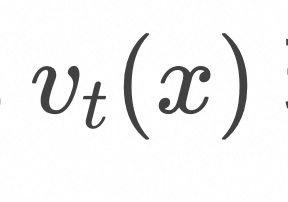

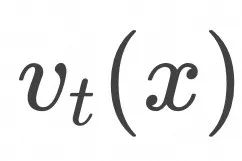
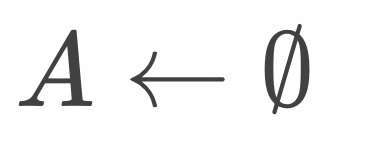
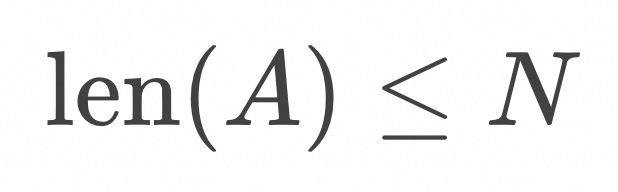

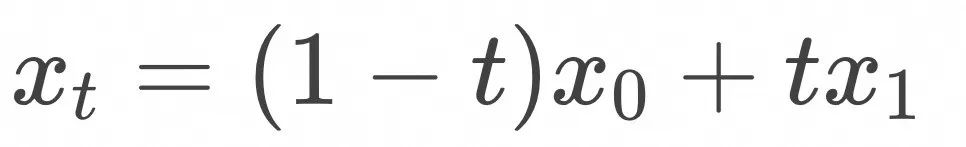
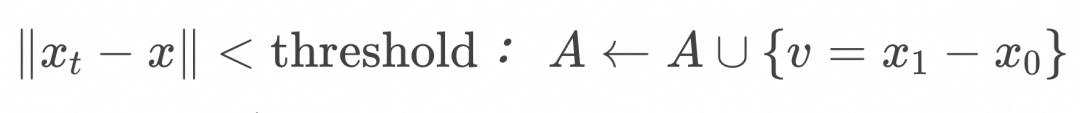
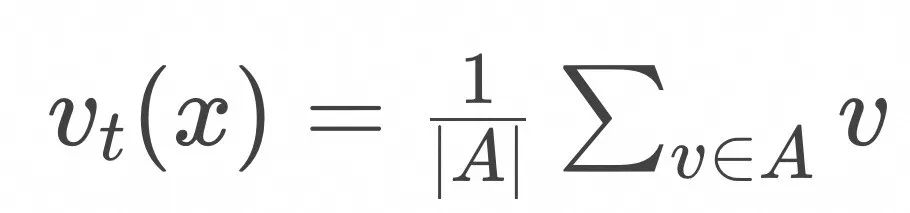

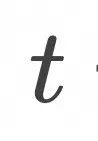
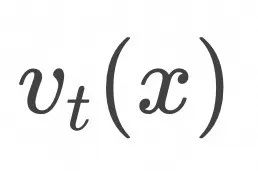
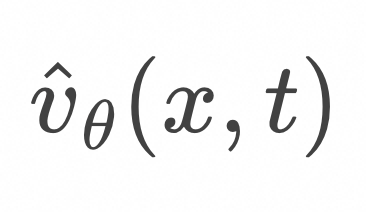
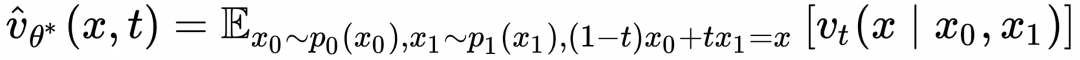
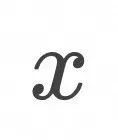
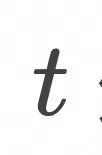
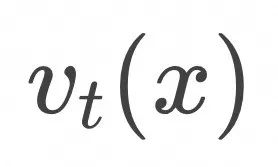
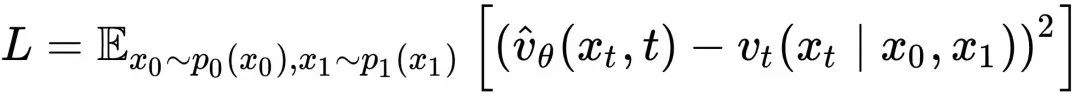
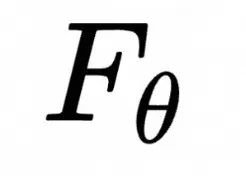 是
是
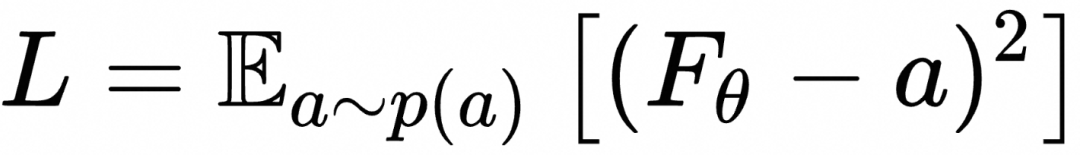
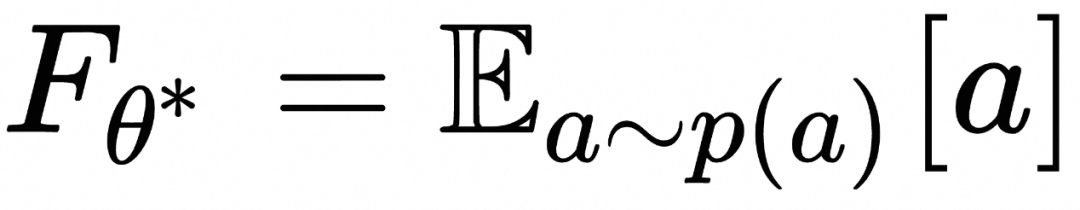
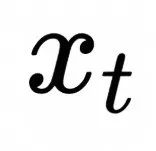
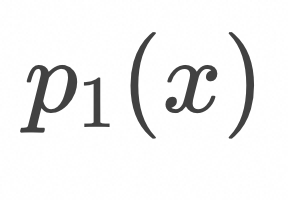 设为高斯分布,
设为高斯分布,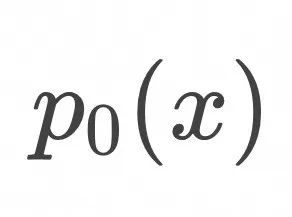 设为图像训练集对应的分布,我们得到Flow Matching的训练算法如下:
设为图像训练集对应的分布,我们得到Flow Matching的训练算法如下: ,高斯噪音
,高斯噪音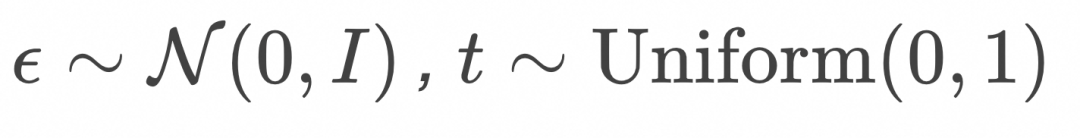
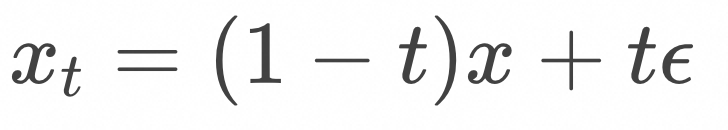
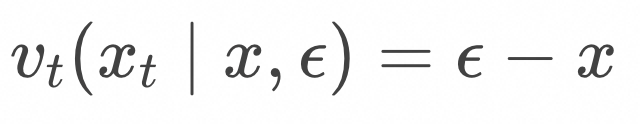
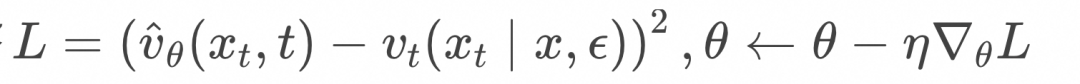
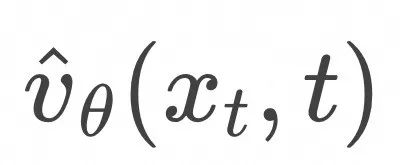 的训练以后,就可以通过求解常微分方程进行采样了,算法如下:
的训练以后,就可以通过求解常微分方程进行采样了,算法如下: ,设定步长
,设定步长