作者:来自 Elastic Peter Straßer 及 Benjamin Trent
![]()
本文探讨了如何优化后期交互向量,以适应大规模生产工作负载,例如减少磁盘空间占用和提高计算效率。
在之前关于 ColPali 的博客中,我们探讨了如何使用 Elasticsearch 创建视觉搜索应用。我们主要关注 ColPali 等模型为应用带来的价值,但与 E5 等双编码器向量搜索相比,它们在性能上存在一定劣势。
基于第 1 部分的示例,本文将探讨如何利用不同技术和 Elasticsearch 强大的向量搜索工具,使后期交互向量适应大规模生产工作负载。
完整代码示例可在 GitHub 上查看。
问题
ColPali 在索引中的每个文档页面会生成 1000 多个向量,这在使用后期交互向量时带来了两个主要挑战:
- 磁盘空间:存储所有这些向量会占用大量磁盘空间,在大规模应用时成本高昂。
- 计算量:在使用
maxSimDotProduct() 进行文档排序时,需要将每个文档的所有向量与查询的 N 个向量进行比较,计算成本极高。
接下来,我们将探讨一些优化技术,以解决这些问题。
位向量(Bit Vectors)
为了减少磁盘空间占用,我们可以将图像压缩为位向量(bit vectors)。可以使用一个简单的 Python 函数,将多向量转换为位向量:
def to_bit_vectors(embeddings: list) -> list:
return [
np.packbits(np.where(np.array(embedding) > 0, 1, 0))
.astype(np.int8)
.tobytes()
.hex()
for embedding in embeddings
]
函数核心概念
该函数的核心逻辑非常简单:
- 值大于 0 的元素转换为 1
- 值小于 0 的元素转换为 0
这样,我们就得到了一个 仅包含 0 和 1 的数组,并将其转换为 十六进制字符串 来表示位向量(bit vector)。
在索引映射(index mapping)中,我们需要将 element_type 参数设置为 bit:
mappings = {
"mappings": {
"properties": {
"col_pali_vectors": {
"type": "rank_vectors",
"element_type": "bit"
}
}
}
}
es.indices.create(index=INDEX_NAME, body=mappings)
在将所有新的位向量(bit vectors)写入索引后,我们可以使用以下代码对它们进行排序:
query = "What do companies use for recruiting?"
query_vector = to_bit_vectors(create_col_pali_query_vectors(query))
es_query = {
"_source": False,
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "maxSimInvHamming(params.query_vector, 'col_pali_vectors')",
"params": {
"query_vector": query_vector
}
}
}
},
"size": 5
}
![]()
通过牺牲少量精度,我们可以使用 Hamming 距离(maxSimInvHamming(...))进行排序,该方法能够利用 位掩码(bit-masks)、SIMD 等优化技术。更多关于 位向量 和 Hamming 距离 的信息,请参考我们的博客。
或者,我们也可以 不 将查询向量转换为位向量,而是直接使用完整精度的后期交互向量进行搜索:
query = "What do companies use for recruiting?"
query_vector = create_col_pali_query_vectors(query)
es_query = {
"_source": False,
"query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "maxSimDotProduct(params.query_vector, 'col_pali_vectors')",
"params": {
"query_vector": query_vector
}
}
}
},
"size": 5
}
![]()
这将使用非对称相似性函数来比较向量。
让我们考虑两个位向量(bit vectors)之间的常规 Hamming 距离。假设我们有一个文档向量 D:
![]()
以及一个查询向量 Q:
![]()
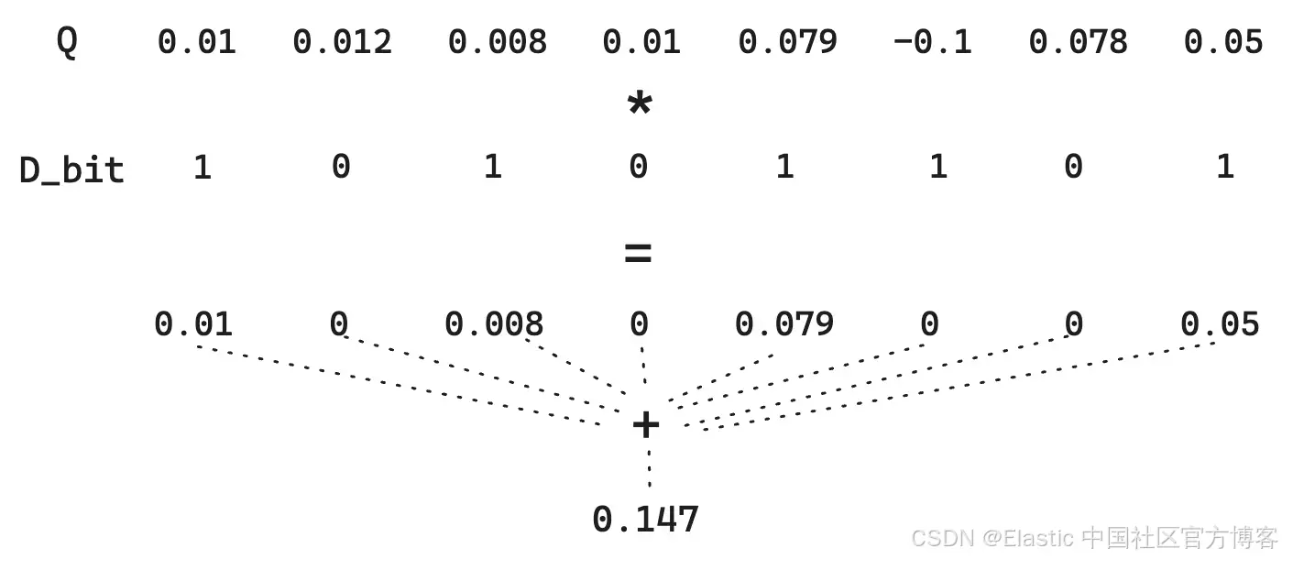
简单的二进制量化将 D 转换为 10101101,将 Q 转换为 11111011。对于 Hamming 距离,我们需要直接的位运算 —— 这是非常快速的。在这种情况下,Hamming 距离 为 01010110,其值为 86。因此,得分就变成了该 Hamming 距离的反值。请记住,更相似的向量 具有 更小的 Hamming 距离,因此反转该值可以使更相似的向量得分更高。在此案例中,得分将为 0.012。
然而,需要注意的是,我们失去了每个维度的大小差异。1 就是 1。因此,对于 Q,0.01 和 0.79 之间的差异消失了。由于我们只是按照 >0 进行量化,我们可以做一个小技巧,即 Q 向量不进行量化。这虽然无法利用极其快速的位运算,但它仍然保持了较低的存储成本,因为 D 向量仍然是量化的。
![]()
简而言之,这保留了 Q 中的信息,从而提高了距离估计的质量,并保持了低存储成本。
使用 位向量 可以显著节省磁盘空间和查询时的计算负载。但我们还可以做更多的优化。
平均向量(Average Vectors)
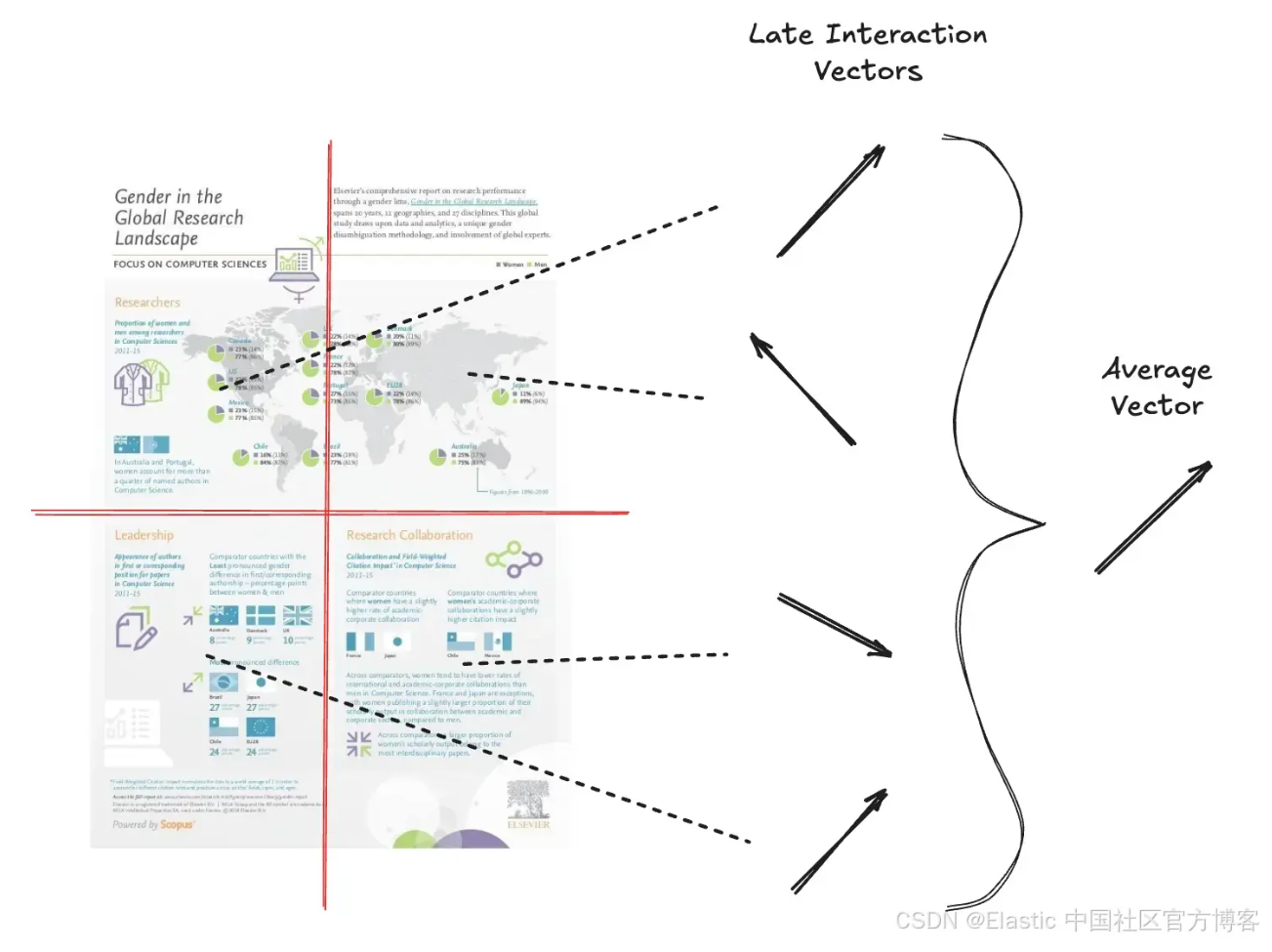
为了在数十万文档的搜索中进行扩展,即使是 位向量 带来的性能提升也不足以满足需求。为了应对这些类型的工作负载,我们需要利用 Elasticsearch 的 HNSW 索引结构进行向量搜索。
由于 ColPali 每个文档会生成大约 一千个向量,这对于添加到我们的 HNSW 图 中来说太多了。因此,我们需要减少向量的数量。为此,我们可以通过对 ColPali 生成的所有文档向量取平均值,来创建文档含义的单一表示。
![]()
目前,这在 Elasticsearch 中无法直接实现,因此我们需要在将向量导入 Elasticsearch 之前对其进行预处理。
我们可以使用 Logstash 或 Ingest Pipelines 来完成此操作,但在这里我们将使用一个简单的 Python 函数:
def to_avg_vector(vectors):
vectors_array = np.array(vectors)
avg_vector = np.mean(vectors_array, axis=0)
norm = np.linalg.norm(avg_vector)
if norm > 0:
normalized_avg_vector = avg_vector / norm
else:
normalized_avg_vector = avg_vector
return normalized_avg_vector.tolist()
我们还对向量进行了归一化,以便使用 点积相似度。
在将所有 ColPali 向量转换为平均向量后,我们可以将它们索引到我们的 dense_vector 字段中:
mappings = {
"mappings": {
"properties": {
"avg_vector": {
"type": "dense_vector",
"dims": 128,
"index": True,
"similarity": "dot_product"
},
"col_pali_vectors": {
"type": "rank_vectors",
"element_type": "bit"
}
}
}
}
es.indices.create(index=INDEX_NAME, body=mappings)
我们必须考虑到,这会增加总的磁盘使用量,因为我们不仅保存了后期交互向量,还保存了更多的信息。此外,我们还需要额外的 RAM 来存储 HNSW 图 ,从而使我们能够在数十亿个向量中进行扩展搜索。为了减少 RAM 的使用,我们可以利用我们流行的 BBQ 功能 。这样,我们就能在庞大的数据集上获得快速的搜索结果,否则是无法实现的。
现在,我们只需使用 KNN 查询 来查找最相关的文档。
query = "What do companies use for recruiting?"
query_vector = to_avg_vector(create_col_pali_query_vectors(query))
es_query = {
"_source": False,
"knn": {
"field": "avg_vector",
"query_vector": query_vector,
"k": 10,
"num_candidates": 100
},
"size": 5
}
![]()
之前最佳匹配不幸降到了排名第三。
为了解决这个问题,我们可以进行多阶段检索。在第一阶段,我们使用 KNN 查询 在数百万个文档中搜索查询的最佳候选文档。在第二阶段,我们仅对前 k(此处为 10)个文档进行重新排序,使用 ColPali 的高保真度后期交互向量来提高准确度。
query = "What do companies use for recruiting?"
col_pali_vector = create_col_pali_query_vectors(query)
avg_vector = to_avg_vector(col_pali_vector)
es_query = {
"_source": False,
"retriever": {
"rescorer": {
"retriever": {
"knn": {
"field": "avg_vector",
"query_vector": avg_vector,
"k": 10,
"num_candidates": 100
}
},
"rescore": {
"window_size": 10,
"query": {
"rescore_query": {
"script_score": {
"query": {
"match_all": {}
},
"script": {
"source": "maxSimDotProduct(params.query_vector, 'col_pali_vectors')",
"params": {
"query_vector": col_pali_vector
}
}
}
}
}
}
}
},
"size": 5
}
![]()
这里,我们使用在 8.18 版本中引入的 rescore retriever 来对结果进行重新排序。重新评分后,我们看到最佳匹配再次排在第一位。
注意:在生产应用中,我们可以使用比 10 更高的 k 值,因为 max sim 函数仍然相对高效。
Token pooling
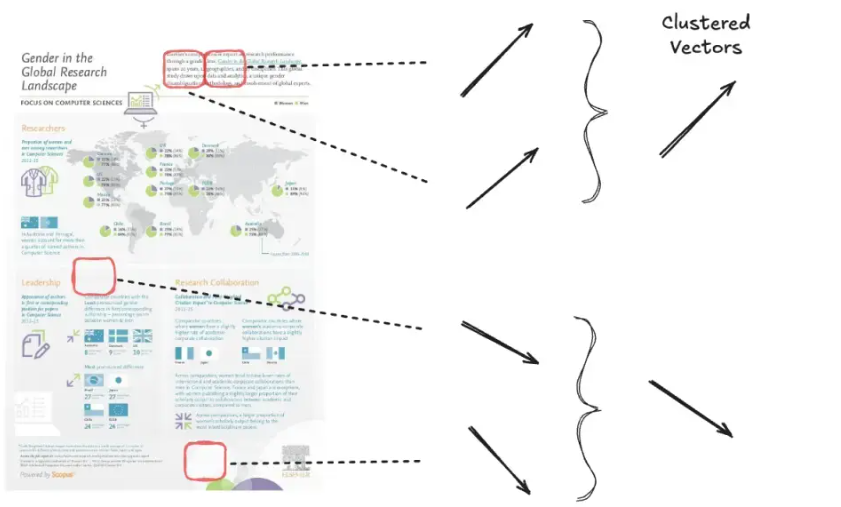
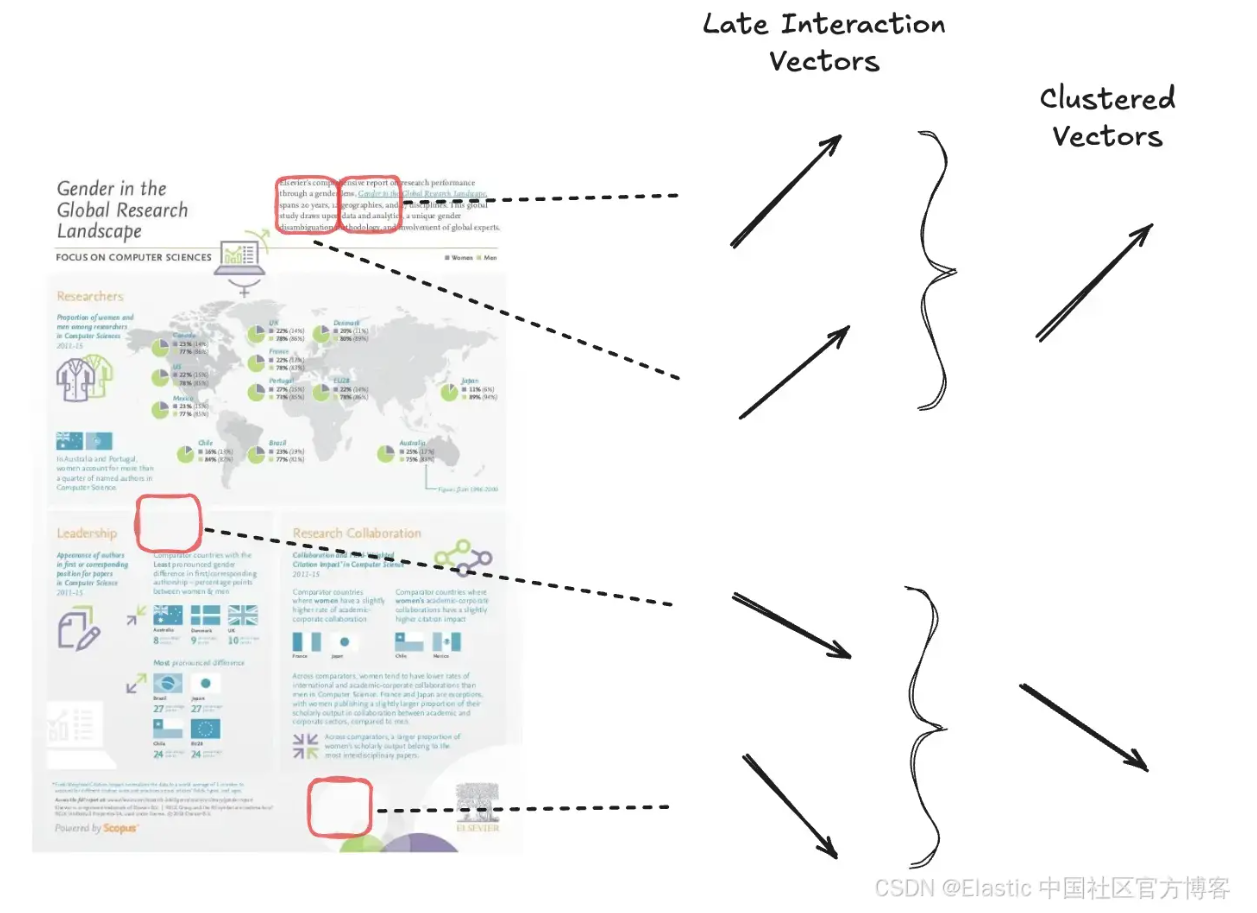
Token pooling 通过汇聚冗余信息(如白色背景区域)来减少多向量嵌入的序列长度。这种技术减少了嵌入的数量,同时保留了页面的大部分信息。
![]()
我们通过聚类语义相似的向量来减少总的向量数量。
Token pooling 通过使用聚类算法将文档中相似的 token 嵌入分组为簇。然后,计算每个簇中向量的均值,以创建一个单一的聚合表示。这个聚合向量替代该组中的原始 tokens,从而减少总的向量数量,同时几乎不损失文档信号。
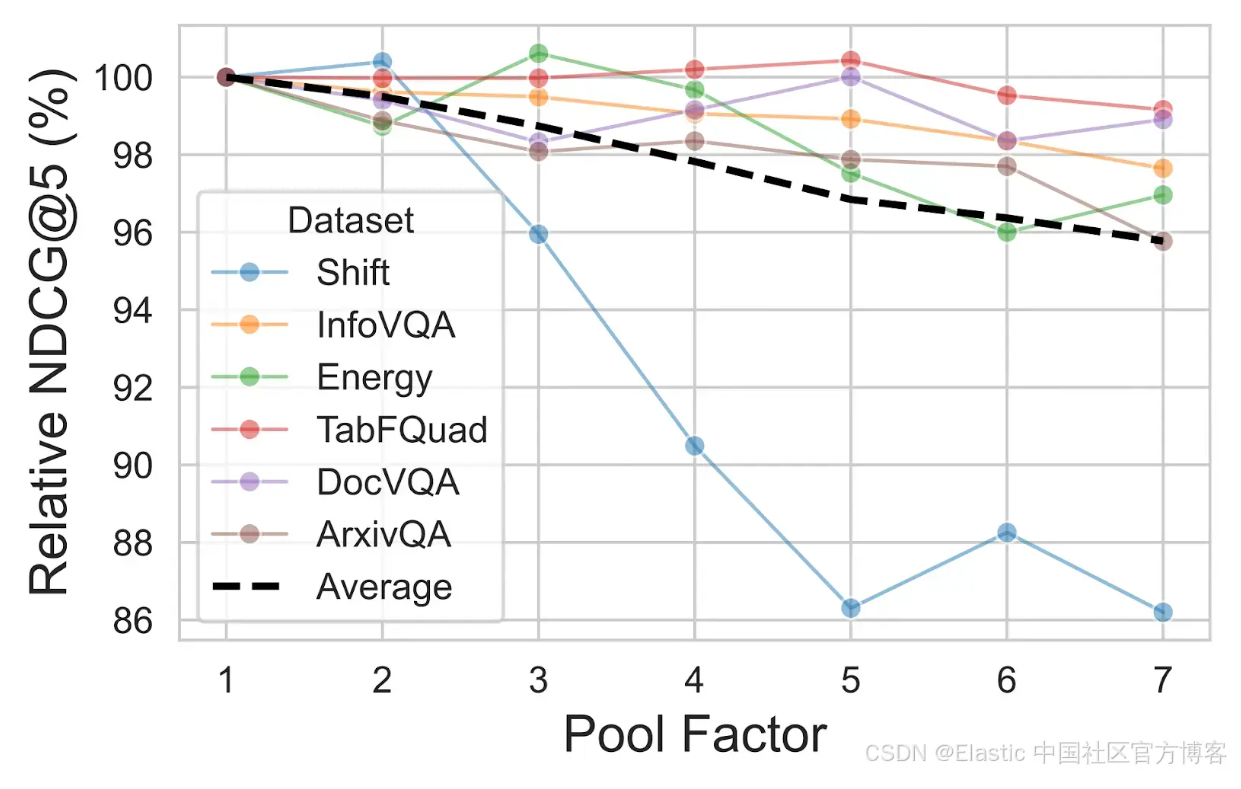
ColPali 论文为大多数数据集提出了初始的 pool factor 值为 3,这在减少总向量数量 66.7% 的同时,保留了原始性能的 97.8%。
![]()
Source: https://arxiv.org/pdf/2407.01449
但我们需要小心:Shift 数据集包含非常密集、文本密集且几乎没有空白区域的文档,在 pool factor 增加时性能会迅速下降。
为了创建池化向量(pooled vectors),我们可以使用 colpali_engine 库:
from colpali_engine.compression.token_pooling import HierarchicalTokenPooler
pooler = HierarchicalTokenPooler(pool_factor=3) # test on your data for a good pool_factor
def pool_vectors(embedding: list) -> list:
tensor = torch.tensor(embedding).unsqueeze(0)
pooled = pooler.pool_embeddings(tensor)
return pooled.squeeze(0).tolist()
我们现在有一个其维度减少了大约 66.7% 的向量。我们像往常一样将其索引,并能够使用 maxSimDotProduct() 函数进行搜索。
![]()
我们能够获得良好的搜索结果,代价是结果的准确性略有下降。
提示:使用更高的 pool_factor(100-200),你也可以在平均向量方案和我们在这里讨论的方案之间找到一个折衷方案。当每个文档大约有 5-10 个向量时,将它们索引到嵌套字段中并利用 HNSW 索引变得可行。
Coss-encoder 与 late-interaction 和 bi-encoder 的对比
通过我们目前所学的内容,late-interaction 模型(如 ColPali 或 ColBERT)与其他 AI 检索技术相比,处于什么位置呢?
虽然 max sim 函数比 cross-encoders 更便宜,但它仍然需要比使用 bi-encoders 的向量搜索进行更多的比较和计算。在 bi-encoder 中,我们仅需对每个查询-文档对比两个向量。
![]()
因此,我们的建议是将 late-interaction 模型一般只用于对前 k 个搜索结果进行重新排序。我们在字段类型的命名中也反映了这一点:rank_vectors。
但那 cross-encoder 呢?是否 late interaction 模型因为执行时更便宜而更好?像往常一样,答案是:这取决于情况。 cross-encoders 通常产生更高质量的结果,但它们需要大量计算,因为查询-文档对必须经过完整的 Transformer 模型处理。它们的一个优势是,它们不需要对向量进行索引,并且可以以无状态的方式运行。这带来了以下优势:
- 使用更少的磁盘空间
- 系统更简单
- 更高质量的搜索结果
- 较高的延迟,因此不能进行深度重新排序
另一方面,late-interaction 模型可以将部分计算卸载到索引时进行,从而使查询变得更便宜。我们为此付出的代价是需要索引向量,这使得我们的索引管道更加复杂,并且需要更多的磁盘空间来保存这些向量。
特别是在 ColPali 的情况下,来自图像的信息分析非常昂贵,因为它们包含大量数据。在这种情况下,折衷更倾向于使用 late-interaction 模型,如 ColPali,因为在查询时评估这些信息会非常耗费资源/缓慢。
对于像 ColBERT 这样的 late-interaction 模型,它处理的主要是文本数据(像大多数 cross-encoders,例如 elastic-rerank-v1),则决策可能会更多地倾向于使用 cross-encoder 来利用磁盘节省和系统简化的优势。
我们鼓励你根据自己的用例权衡这些优缺点,并尝试 Elasticsearch 提供的不同工具,以构建最佳的搜索应用程序。
结论
在这篇博客中,我们探讨了各种优化 late interaction 模型(如 ColPali)的方法,以便在 Elasticsearch 中进行大规模的向量搜索。虽然 late interaction 模型在检索效率和排名质量之间提供了良好的平衡,但它们也带来了与存储和计算相关的挑战。
为了解决这些问题,我们探讨了以下几种方法:
- 比特向量:通过使用高效的相似性计算(如汉明距离或非对称最大相似度)显著减少磁盘空间。
- 平均向量:将多个嵌入压缩成一个单一的密集表示,从而通过 HNSW 索引实现高效的检索。
- 标记池化:智能地合并冗余的嵌入,同时保持语义完整性,减少查询时的计算开销。
Elasticsearch 提供了一个强大的工具包,可以根据你的需求自定义和优化搜索应用程序。无论你是优先考虑检索速度、排名质量还是存储效率,这些工具和技术都使你能够根据实际应用的需求平衡性能和质量。
Elasticsearch 拥有许多新功能,帮助你构建适合你用例的最佳搜索解决方案。深入了解我们的示例笔记本,开始免费的云试用,或者现在就在本地机器上试试 Elastic。
原文:Scaling late interaction models in Elasticsearch - part 2 - Elasticsearch Labs